
Chapter 1 Introduction

1.1 Target Audience
The course is intended for students in the biomedical sciences and researchers who use informatics tools in their research and have not had training in reproducibility tools and methods.
This course is written for individuals who:
- Have some familiarity with R or Python - have written some scripts.
- Have not had formal training in computational methods.
- Have limited or no familiarity with GitHub, Docker, or package management tools.

1.3 Motivation
Cancer datasets are plentiful, complicated, and hold untold amounts of information regarding cancer biology. Cancer researchers are working to apply their expertise to the analysis of these vast amounts of data but training opportunities to properly equip them in these efforts can be sparse. This includes training in reproducible data analysis methods.
Data analyses are generally not reproducible without direct contact with the original researchers and a substantial amount of time and effort (Beaulieu-Jones and Greene 2017). Reproducibility in cancer informatics (as with other fields) is still not monitored or incentivized despite the fact that it is fundamental to the scientific method. Even without incentives, most researchers strive for reproducibility in their own work but often lack the skills or training to do so effectively.
Equipping researchers with the skills to create reproducible data analyses increases the efficiency of everyone involved. Reproducible analyses are more likely to be understood, applied, and replicated by others. This helps expedite the scientific process by helping researchers avoid false positive dead ends. Well documented and reproducible methods save researchers’ time so they don’t have to reinvent the proverbial wheel for methods that others in the field are already performing.
1.4 Curriculum
This course introduces the concepts of reproducibility and replicability in the context of cancer informatics. It uses hands-on exercises to demonstrate in practical terms how to increase the reproducibility of data analyses. The course also introduces tools relevant to reproducibility including analysis notebooks, package managers, git and GitHub.

The course includes hands-on exercises for how to apply reproducible code concepts to your code. Individuals who take this course are encouraged to complete these activities as they follow along with the course material to help increase the reproducibility of their analyses.
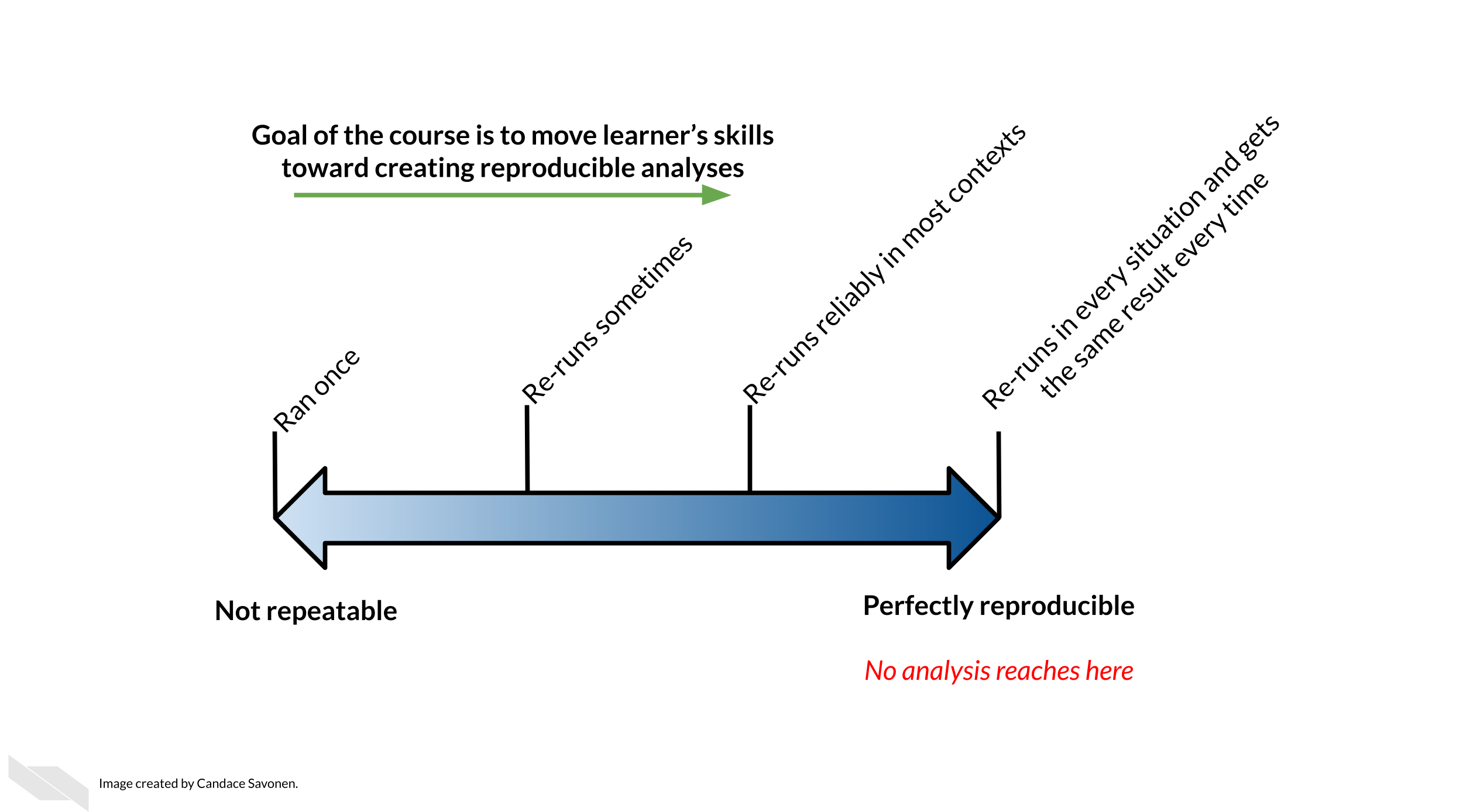
Goal of this course:
Equip learners with reproducibility skills they can apply to their existing analysis scripts and projects. This course opts for an “ease into it” approach. We attempt to give learners doable, incremental steps to increase the reproducibility of their analyses.
What is not the goal
This course is meant to introduce learners to reproducibility tools, but it does not necessarily represent the absolute end-all, be-all best practices for the use of these tools. In other words, this course gives a starting point with these tools, but not an ending point. The advanced version of this course is the next step toward incrementally “better practices”.
1.5 How to use the course
This course is designed with busy professional learners in mind – who may have to pick up and put down the course when their schedule allows.
Each exercise has the option for you to continue along with the example files as you’ve been editing them in each chapter, OR you can download fresh chapter files that have been edited for that part of the course. This way, if you decide to skip a chapter or find that your own files no longer make sense, you have a fresh starting point for each exercise.