Chapter 5 Modeling Data in the Tidyverse
5.1 About This Course
Developing insights about your organization, business, or research project depends on effective modeling and analysis of the data you collect. Building effective models requires understanding the different types of questions you can ask and how to map those questions to your data. Different modeling approaches can be chosen to detect interesting patterns in the data and identify hidden relationships.
This course covers the types of questions you can ask of data and the various modeling approaches that you can apply. Topics covered include hypothesis testing, linear regression, nonlinear modeling, and machine learning. With this collection of tools at your disposal, as well as the techniques learned in the other courses in this specialization, you will be able to make key discoveries from your data for improving decision-making throughout your organization.
In this specialization we assume familiarity with the R programming language. If you are not yet familiar with R, we suggest you first complete R Programming before returning to complete this course.
5.2 The Purpose of Data Science
Data science has multiple definitions. For this module we will use the definition:
Data science is the process of formulating a quantitative question that can be answered with data, collecting and cleaning the data, analyzing the data, and communicating the answer to the question to a relevant audience.
In general the data science process is iterative and the different components blend together a little bit. But for simplicity lets discretize the tasks into the following 7 steps:
- Define the question you want to ask the data
- Get the data
- Clean the data
- Explore the data
- Fit statistical models
- Communicate the results
- Make your analysis reproducible
This module is focused on three of these steps: (1) defining the question you want to ask, (4) exploring the data and (5) fitting statistical models to the data.
We have seen previously how to extract data from the web and from databases and we have seen how to clean it up and tidy the data. You also know how to use plots and graphs to visualize your data. You can think of this module as using those tools to start to answer questions using the tools you have already learned about.
5.3 Types of Data Science Questions
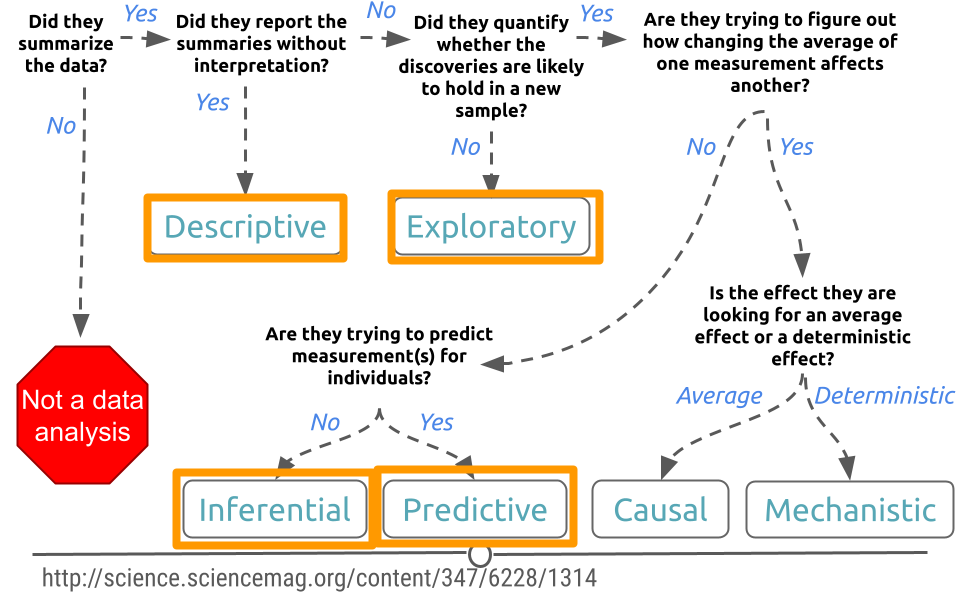
We will look at a few different types of questions that you might want to answer from data. This flowchart gives some questions you can ask to figure out what type of question your analysis focuses on. Each type of question has different goals.
There are four classes of questions that we will focus on:
Descriptive: The goal of descriptive data science questions is to understand the components of a dataset, describe what they are, and explain that description to others who might want to understand the data. This is the simplest type of data analysis.
Exploratory: The goal of exploratory data science questions is to find unknown relationships between the different variables you have measured in your dataset. Exploratory analysis is open ended and designed to find expected or unexpected relationships between different measurements. We have already seen how plotting the data can be very helpful to get a general understanding about how variables relate to one another.
Inferential: The goal of inferential data science questions is to is to use a small sample of data to say something about what would happen if we collected more data. Inferential questions come up because we want to understand the relationships between different variables but it is too expensive or difficult to collect data on every person or object.
Predictive: The goal of predictive data science question is to use data from a large collection to predict values for new individuals. This might be predicting what will happen in the future or predicting characteristics that are difficult to measure. Predictive data science is sometimes called machine learning.
One primary thing we need to be aware of is that just because two variables are correlated with each other, doesn’t mean that changing one causes a change in the other.
One way that people illustrate this idea is to look at data where two variables show a relationship, but are clearly not related to each other. For example, in a specific time range, the number of people who drown while falling into a pool is related to the number of films that Nicholas Cage appears in. These two variables are clearly unrelated to each other, but the data seems to show a relationship. We’ll discuss more later.
5.4 Data Needs
Let’s assume you have the dataset that contains the variables you are looking for to evaluate the question(s) you are interested in, and it is tidy and ready to go for your analysis. It’s always nice to step back to make sure the data is the right data before you spend hours and hours on your analysis. So, let’s discuss some of the potential and common issues people run into with their data.
5.4.1 Number of observations is too small
It happens quite often that collecting data is expensive or not easy. For instance, in a medical study on the effect of a drug on patients with Alzheimer disease, researchers will be happy if they can get a sample of 100 people. These studies are expensive, and it’s hard to find volunteers who enroll in the study. It is also the case with most social experiments. While data are everywhere, the data you need may not be. Therefore, most data scientists at some point in their career face the curse of small sample size. Small sample size makes it hard to be confident about the results of your analysis. So when you can, and it’s feasible, a large sample is preferable to a small sample. But when your only available dataset to work with is small you will have to note that in your analysis. Although we won’t learn them in this course, there are particular methods for inferential analysis when sample size is small.
5.4.2 Dataset does not contain the exact variables you are looking for
In data analysis, it is common that you don’t always have what you need. You may need to know individuals’ IQ, but all you have is their GPA. You may need to understand food expenditure, but you have total expenditure. You may need to know parental education, but all you have is the number of books the family owns. It is often that the variable that we need in the analysis does not exist in the dataset and we can’t measure it. In these cases, our best bet is to find the closest variables to that variable. Variables that may be different in nature but are highly correlated with (similar to) the variable of interest are what are often used in such cases. These variables are called proxy variables.
For instance, if we don’t have parental education in our dataset, we can use the number of books the family has in their home as a proxy. Although the two variables are different, they are highly correlated (very similar), since more educated parents tend to have more books at home. So in most cases where you can’t have the variable you need in your analysis, you can replace it with a proxy. Again, it must always be noted clearly in your analysis why you used a proxy variable and what variable was used as your proxy.
5.4.3 Variables in the dataset are not collected in the same year
Imagine we want to find the relationship between the effect of cab prices and the number of rides in New York City. We want to see how people react to price changes. We get a hold of data on cab prices in 2018, but we only have data on the number of rides from 2015. Can these two variables be used together in our analysis? Simply, no. If we want to answer this question, we can’t match these two sets of data. If we’re using the prices from 2018, we should find the number of rides from 2018 as well. Unfortunately, a lot of the time, this is an issue you’ll run into. You’ll either have to find a way to get the data from the same year or go back to the drawing board and ask a different question. This issue can be ignored only in cases where we’re confident the variables does not change much from year to year.
5.4.4 Dataset is not representative of the population that you are interested in
You will hear the term representative sample, but what is it? Before defining a representative sample, let’s see what a population is in statistical terms. We have used the word population without really getting into its definition.
A sample is part of a population. A population, in general, is every member of the whole group of people we are interested in. Sometimes it is possible to collect data for the entire population, like in the U.S. Census, but in most cases, we can’t. So we collect data on only a subset of the population. For example, if we are studying the effect of sugar consumption on diabetes, we can’t collect data on the entire population of the United States. Instead, we collect data on a sample of the population. Now, that we know what sample and population are, let’s go back to the definition of a representative sample.
A representative sample is a sample that accurately reflects the larger population. For instance, if the population is every adult in the United States, the sample includes an appropriate share of men and women, racial groups, educational groups, age groups, geographical groups, and income groups. If the population is supposed to be every adult in the U.S., then you can’t collect data on just people in California, or just young people, or only men. This is the idea of a representative sample. It has to model the broader population in all major respects.
We give you one example in politics. Most recent telephone poles in the United States have been bad at predicting election outcomes. Why? This is because by calling people’s landlines you can’t guarantee you will have a representative sample of the voting age population since younger people are not likely to have landlines. Therefore, most telephone polls are skewed toward older adults.
Random sampling is a necessary approach to having a representative sample. Random sampling in data collection means that you randomly choose your subjects and don’t choose who gets to be in the sample and who doesn’t. In random sampling, you select your subjects from the population at random like based on a coin toss. The following are examples of lousy sampling:
- A research project on attitudes toward owning guns through a survey sent to subscribers of a gun-related magazine (gun magazine subscribers are not representative of the general population, and the sample is very biased).
- A research project on television program choices by looking at Facebook TV interests (not everybody has a Facebook account. Most online surveys or surveys on social media have to be taken with a grain of salt because not all members of all social groups have an online presentation or use social media.)
- A research study on school meals and educational outcomes done in a neighborhood with residents mainly from one racial group (school meals can have a different effect on different income and ethnic groups).
The moral of the story is to always think about what your population is. Your population will change from one project to the next. If you are researching the effect of smoking on pregnant women, then your population is, well, pregnant women (and not men). After you know your population, then you will always want collect data from a sample that is representative of your population. Random sampling helps.
And lastly, if you have no choice but to work with a dataset that is not collected randomly and is biased, be careful not to generalize your results to the entire population. If you collect data on pregnant women of age 18-24, you can’t generalize your results to older women. If you collect data from the political attitudes of residents of Washington, DC, you can’t say anything about the whole nation.
5.4.5 Some variables in the dataset are measured with error
Another curse of a dataset is measurement error. In simple, measurement error refers to incorrect measurement of variables in your sample. Just like measuring things in the physical world comes with error (like measuring distance, exact temperature, BMI, etc.), measuring variables in the social context can come with an error. When you ask people how many books they have read in the past year, not everyone remembers it correctly. Similarly, you may have measurement error when you ask people about their income. A good researcher recognizes measurement error in the data before any analysis and takes it into account during their analysis.
5.4.6 Variables are confounded
What if you were interested in determining what variables lead to increases in crime? To do so, you obtain data from a US city with lots of different variables and crime rates for a particular time period. You would then wrangle the data and at first you look at the relationship between popsicle sales and crime rates. You see that the more popsicles that are sold, the higher the crime rate.
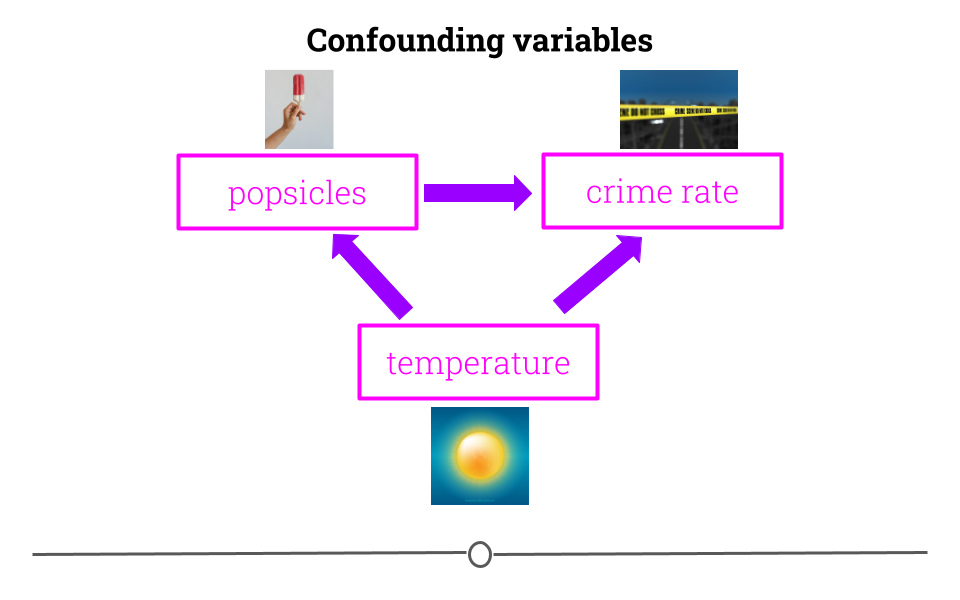
Your first thought may be that popsicles lead to crimes being committed. However, there is a confounder that’s not being considered!
In short, confounders are other variables that may affect our outcome but are also correlated with (have a relationship with) our main variable of interest. In the popsicle example, temperature is an important confounder. More crimes happen when it’s warm out and more popsicles are sold. It’s not the popsicles at all driving the relationship. Instead temperature is likely the culprit.
This is why getting an understanding of what data you have and how the variables relate to one another is so vital before moving forward with inference or prediction. We have already described exploratory analysis to some extent using visualization methods. Now we will recap a bit and discuss descriptive analysis.
5.5 Descriptive and Exploratory Analysis
Descriptive and Exploratory analysis will first and foremost generate simple summaries about the samples and their measurements to describe the data you’re working with and how the variables might relate to one another. There are a number of common descriptive statistics that we’ll discuss in this lesson: measures of central tendency (eg: mean, median, mode) or measures of variability (eg: range, standard deviations, or variance).
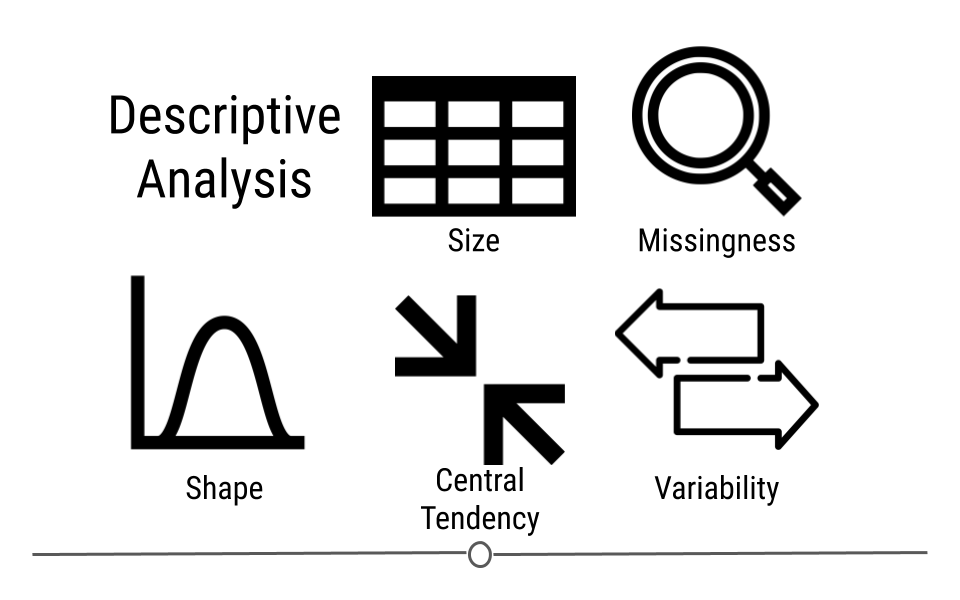
This type of analysis is aimed at summarizing your dataset. Unlike analysis approaches we’ll discuss in later, descriptive and exploratory analysis is not for generalizing the results of the analysis to a larger population nor trying to draw any conclusions. Description of data is separated from interpreting the data. Here, we’re just summarizing what we’re working with.
Some examples of purely descriptive analysis can be seen in censuses. In a census, the government collects a series of measurements on all of the country’s citizens. After collecting these data, they are summarized. From this descriptive analysis, we learn a lot about a country. For example, you can learn the age distribution of the population by looking at U.S. census data.
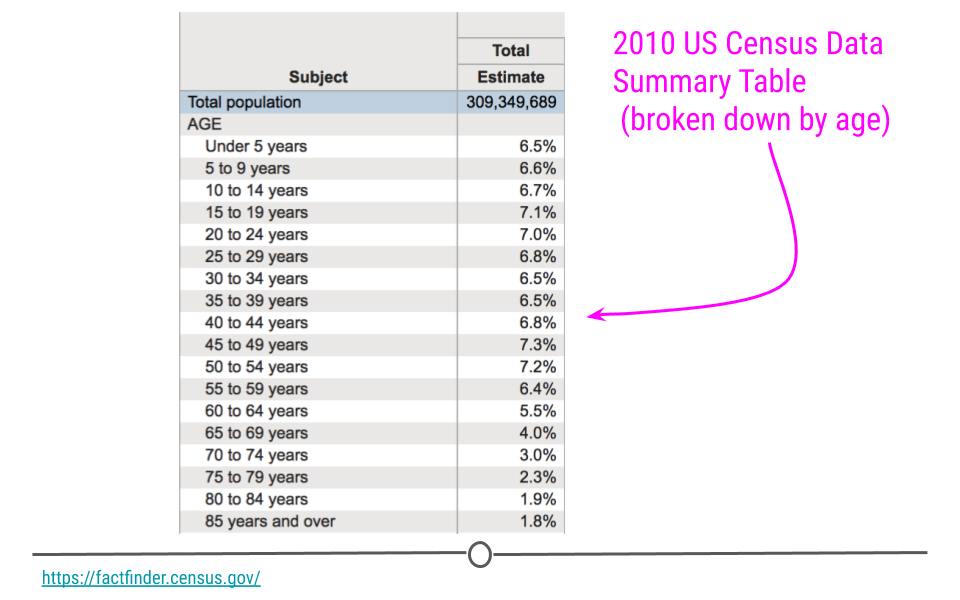
This can be further broken down (or stratified) by sex to describe the age distribution by sex. The goal of these analyses is to describe the population. No inferences are made about what this means nor are predictions made about how the data might trend in the future. The point of this (and every!) descriptive analysis is only to summarize the data collected.
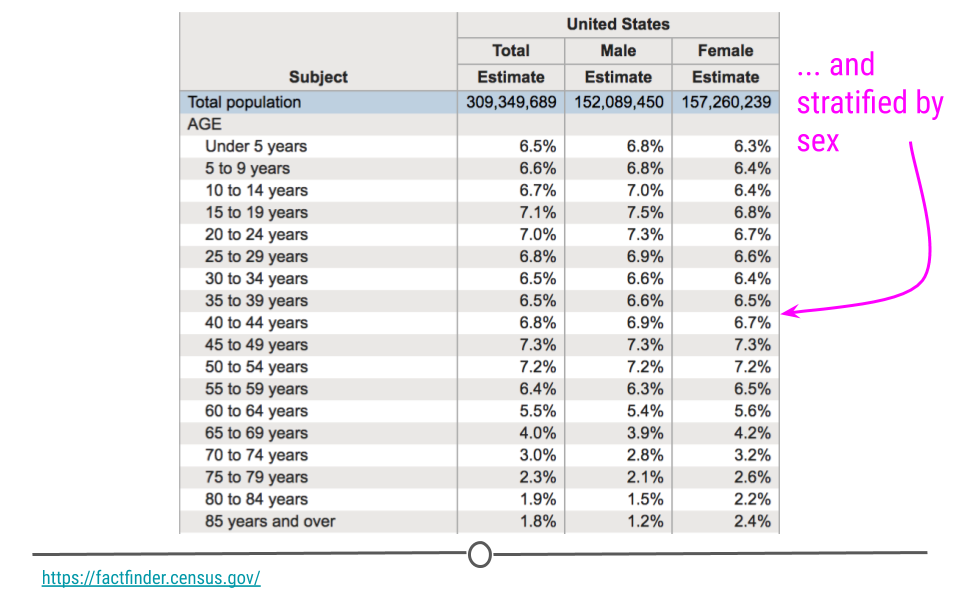
Recall that the glimpse() function of the dplyr package can help you to see what data you are working with.
## load packages
library(tidyverse)
df <- msleep # this data comes from ggplot2
## get a glimpse of your data
glimpse(df)
Also because the data is in tibble format, we can gain a lot of information by just viewing the data itself.
Here we also get information about the dimensions of our data object and the name and class of our variables.
5.5.1 Missing Values
In any analysis, missing data can cause a problem. Thus, it’s best to get an understanding of missingness in your data right from the start. Missingness refers to observations that are not included for a variable. In R, NA is the preferred way to specify missing data, so if you’re ever generating data, its best to include NA wherever you have a missing value.
However, individuals who are less familiar with R code missingness in a number of different ways in their data: -999, N/A, ., or a blank space. As such, it’s best to check to see how missingness is coded in your dataset. A reminder: sometimes different variables within a single dataset will code missingness differently. This shouldn’t happen, but it does, so always use caution when looking for missingness.
In this dataset, all missing values are coded as NA, and from the output of str(df) (or glimpse(df)), we see that at least a few variables have NA values. We’ll want to quantify this missingness though to see which variables have missing data and how many observations within each variable have missing data.
To do this, we can write a function that will calculate missingness within each of our variables. To do this we’ll combine a few functions. In the code here, is.na() returns a logical (TRUE/FALSE) depending upon whether or not the value is missing (TRUE if it is missing). The sum() function then calculates the number of TRUE values there are within an observation. We then use map() to calculate the number of missing values in each variable. The second bit of code does the exact same thing but divides those numbers by the total number of observations (using nrow(df)). For each variable, this returns the proportion of missingness:
library(purrr)
## calculate how many NAs there are in each variable
df %>%
map(is.na) %>%
map(sum)
## calculate the proportion of missingness
## for each variable
df %>%
map(is.na) %>%
map(sum)%>%
map(~ . / nrow(df))%>%
bind_cols()There are also some useful visualization methods for evaluating missingness. You could manually do this with ggplot2, but there are two packages called naniar and visdat written by Nicholas Tierney that are very helpful. The visdat package was used previously in one of our case studies.
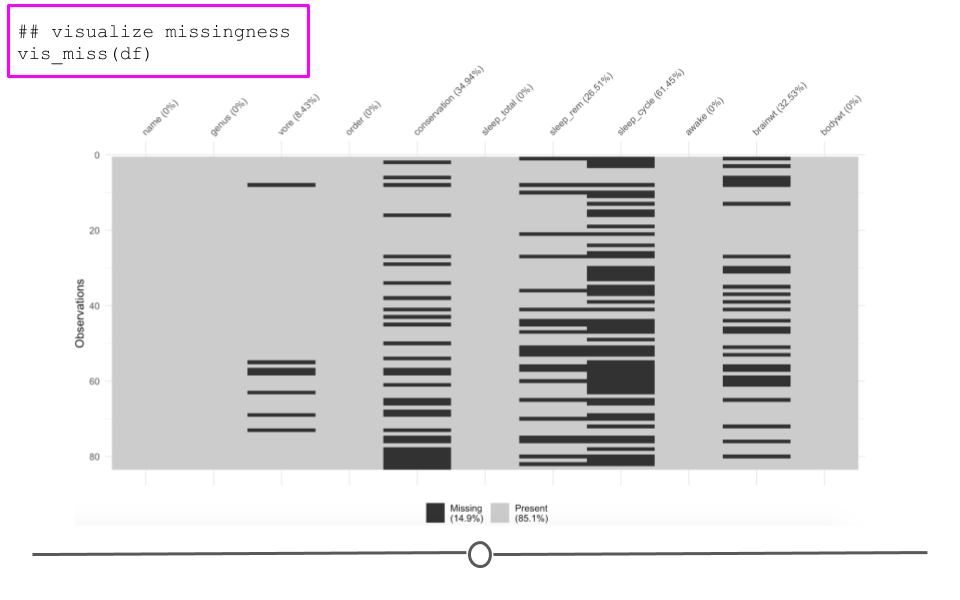
Here, we see the variables listed along the top with percentages summarizing how many observations are missing data for that particular variable. Each row in the visualization is a different observation. Missing data are black. Non-missing values are in grey. Focusing again on brainwt, we can see the 27 missing values visually. We can also see that sleep_cycle has the most missingness, while many variables have no missing data.
5.5.2 Shape
Determining the shape of your variable is essential before any further analysis is done. Statistical methods used for inference often require your data to be distributed in a certain manner before they can be applied to the data. Thus, being able to describe the shape of your variables is necessary during your descriptive analysis.
When talking about the shape of one’s data, we’re discussing how the values (observations) within the variable are distributed. Often, we first determine how spread out the numbers are from one another (do all the observations fall between 1 and 10? 1 and 1000? -1000 and 10?). This is known as the range of the values. The range is described by the minimum and maximum values taken by observations in the variable.
After establishing the range, we determine the shape or distribution of the data. More explicitly, the distribution of the data explains how the data are spread out over this range. Are most of the values all in the center of this range? Or, are they spread out evenly across the range? There are a number of distributions used commonly in data analysis to describe the values within a variable. We’ll cover just a few, but keep in mind this is certainly not an exhaustive list.
5.5.2.1 Normal Distribution
The Normal distribution (also referred to as the Gaussian distribution) is a very common distribution and is often described as a bell-shaped curve. In this distribution, the values are symmetric around the central value with a high density of the values falling right around the central value. The left hand of the curve mirrors the right hand of the curve.
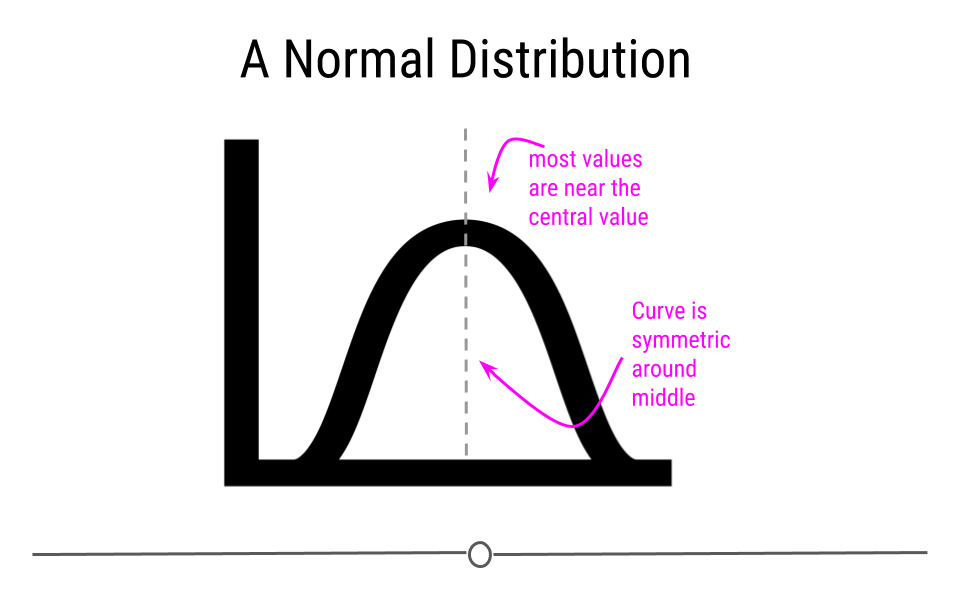
A variable can be described as normally distributed if:
- There is a strong tendency for data to take a central value - many of the observations are centered around the middle of the range.
- Deviations away from the central value are equally likely in both directions - the frequency of these deviations away form the central value occurs at the same rate on either side of the central value.
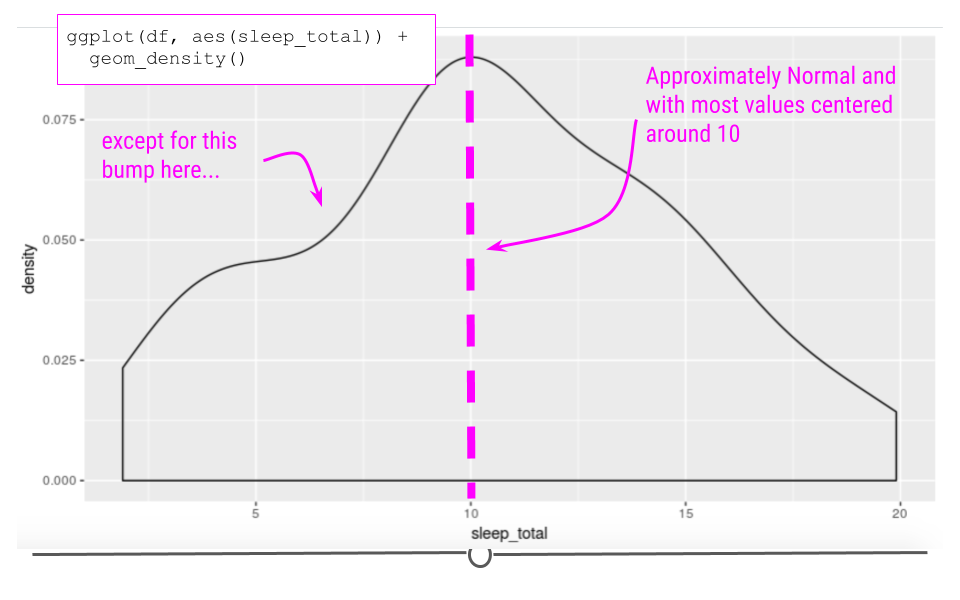
Taking a look at the sleep_total variable within our example dataset, we see that the data are somewhat normal; however, they aren’t entirely symmetric.
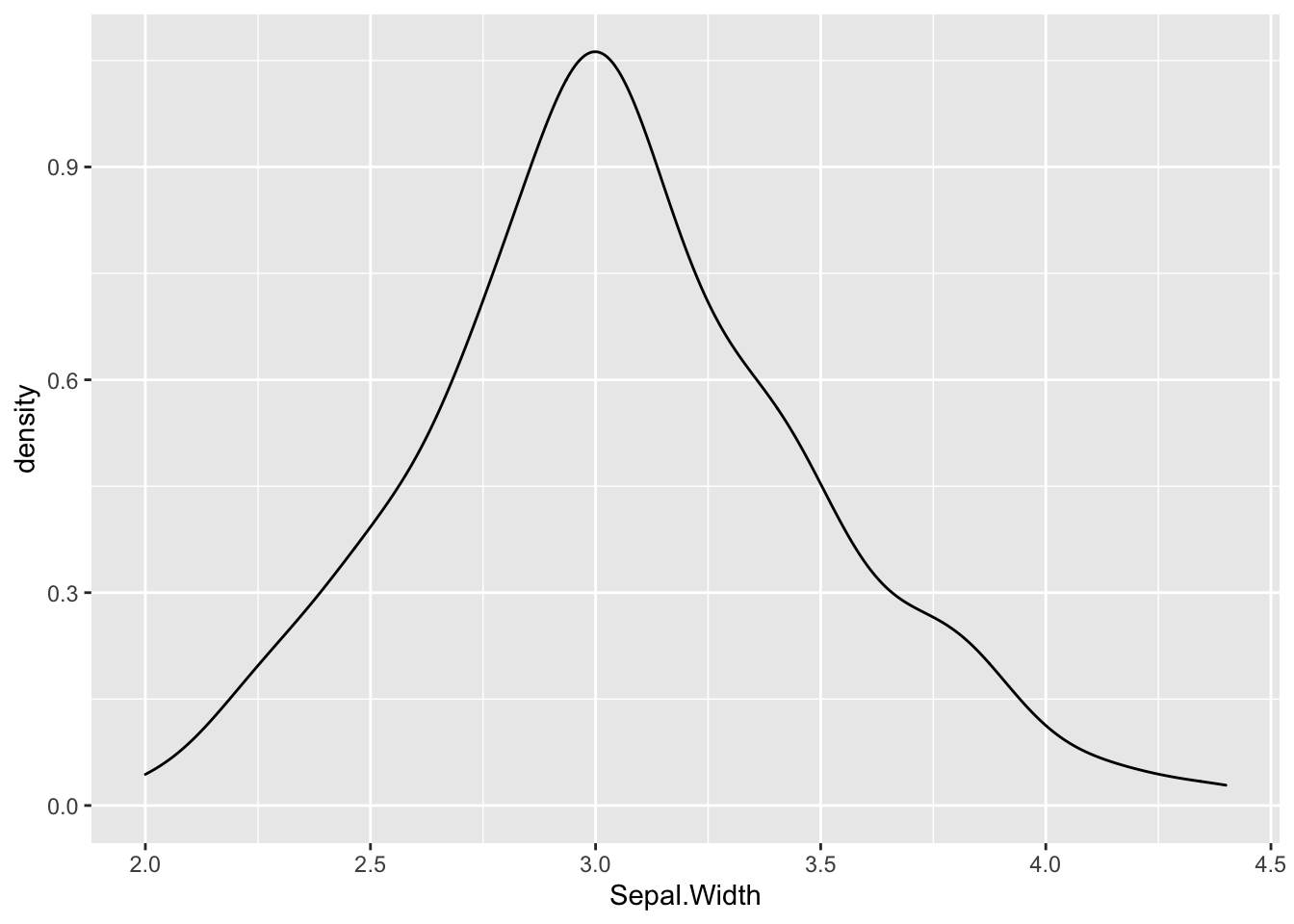
A variable that is distributed more normally can be seen in the iris dataset, when looking at the Sepal.Width variable.
Skewed Distribution
Alternatively, sometimes data follow a skewed distribution. In a skewed distribution, most of the values fall to one end of the range, leaving a tail off to the other side. When the tail is off to the left, the distribution is said to be skewed left. When off to the right, the distribution is said to be skewed right.
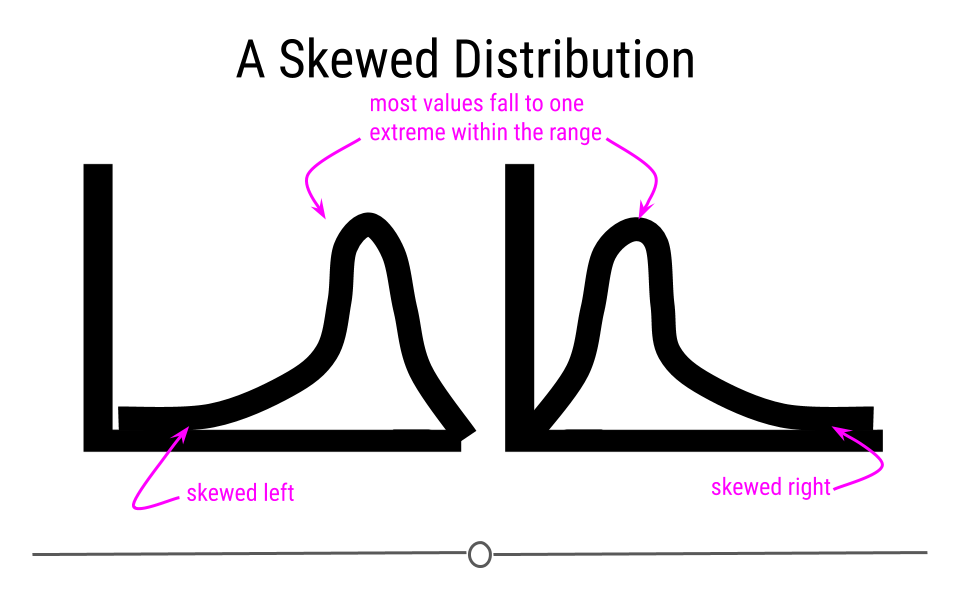
To see an example from the msleep dataset, we’ll look at the variable sleep_rem. Here we see that the data are skewed right, given the shift in values away from the right, leading to a long right tail. Here, most of the values are at the lower end of the range.
## Warning: Removed 22 rows containing non-finite outside the scale range
## (`stat_density()`).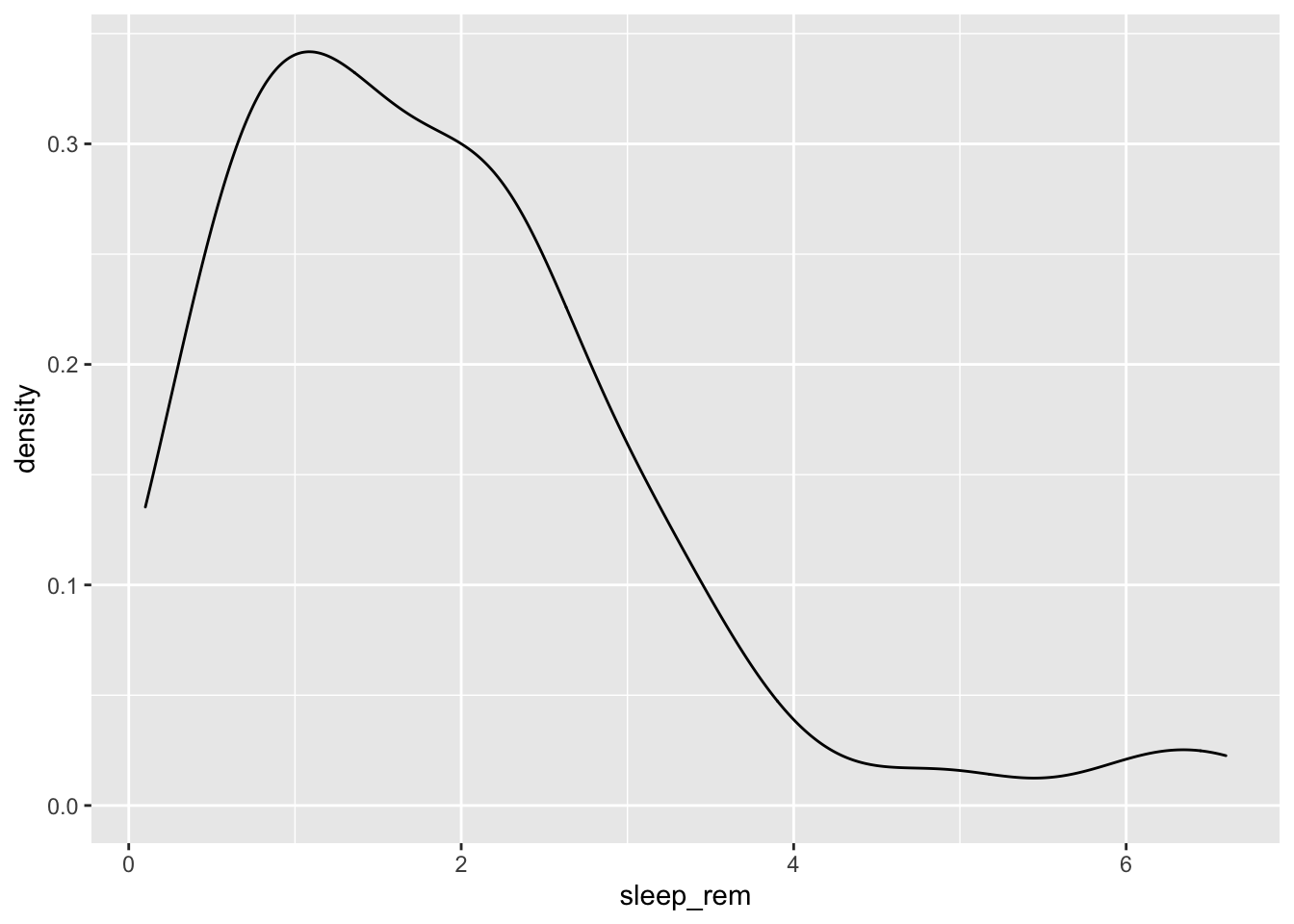
Uniform Distribution
Finally, in distributions we’ll discuss today, sometimes values for a variable are equally likely to be found along any portion of the distribution. The curve for this distribution looks more like a rectangle, since the likelihood of an observation taking a value is constant across the range of possible values.
Outliers
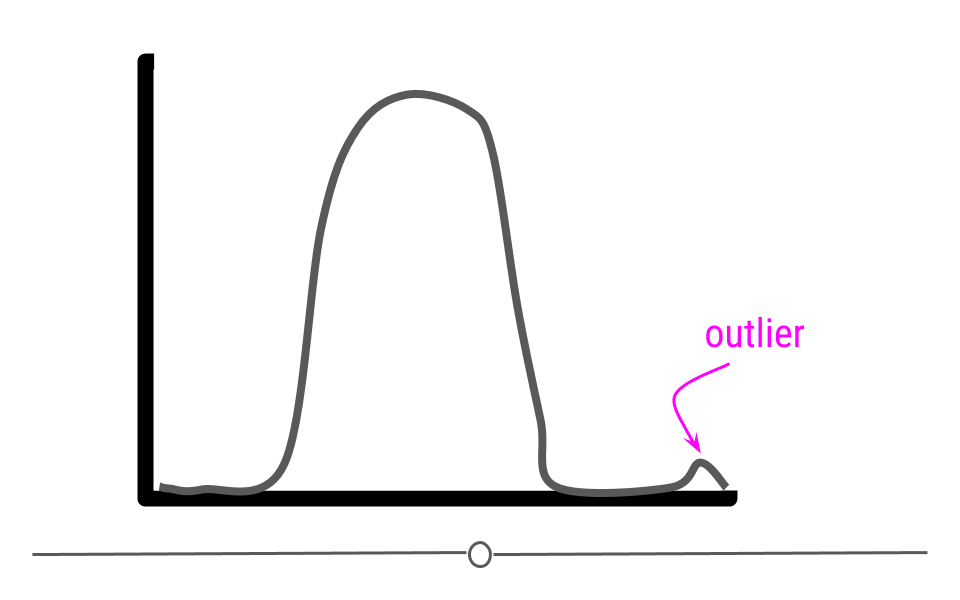
Now that we’ve discussed distributions, it’s important to discuss outliers in more depth. An outlier is an observation that falls far away from the rest of the observations in the distribution. If you were to look at a density curve, you could visually identify outliers as observations that fall far from the rest of the observations.
For example, imagine you had a sample where all of the individuals in your sample are between the ages of 18 and 65, but then you have one sample that is 1 year old and another that is 95 years old.
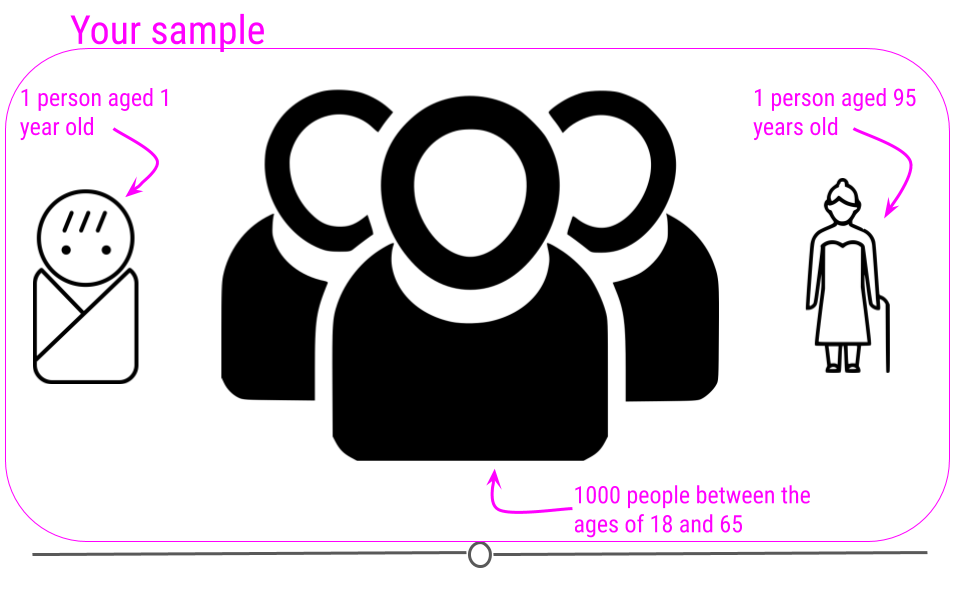
If we were to plot the age data on a density plot, it would look something like this:
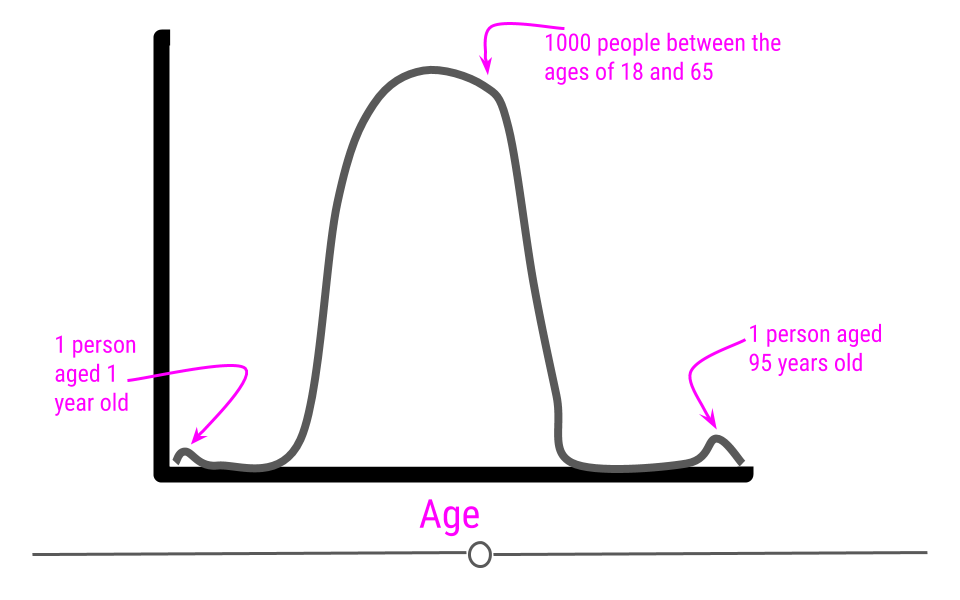
It can sometimes be difficult to decide whether or not a sample should be removed from the dataset. In the simplest terms, no observation should be removed from your dataset unless there is a valid reason to do so. For a more extreme example, what if that dataset we just discussed (with all the samples having ages between 18 and 65) had one sample with the age 600? Well, if these are human data, we clearly know that is a data entry error. Maybe it was supposed to be 60 years old, but we may not know for sure. If we can follow up with that individual and double-check, it’s best to do that, correct the error, make a note of it, and continue with the analysis. However, that’s often not possible. In the cases of obvious data entry errors, it’s likely that you’ll have to remove that observation from the dataset. It’s valid to do so in this case since you know that an error occurred and that the observation was not accurate.
Outliers do not only occur due to data entry errors. Maybe you were taking weights of your observations over the course of a few weeks. On one of these days, your scale was improperly calibrated, leading to incorrect measurements. In such a case, you would have to remove these incorrect observations before analysis.
Outliers can occur for a variety of reasons. Outliers can occur due human error during data entry, technical issues with tools used for measurement, as a result of weather changes that affect measurement accuracy, or due to poor sampling procedures. It’s always important to look at the distribution of your observations for a variable to see if any observations are falling far away from the rest of the observations. It’s then important to think about why this occurred and determine whether or not you have a valid reason to remove the observations from the data.
An important note is that observations should never be removed just to make your results look better! Wanting better results is not a valid reason for removing observations from your dataset.
5.5.3 Identifying Outliers
To identify outliers visually, density plots and boxplots can be very helpful.
For example, if we returned to the iris dataset and looked at the distribution of Petal.Length, we would see a bimodal distribution (yet another distribution!). Bimodal distributions can be identified by density plots that have two distinct humps. In these distributions, there are two different modes – this is where the term “bimodal” comes from. In this plot, the curve suggests there are a number of flowers with petal length less than 2 and many with petal length around 5.
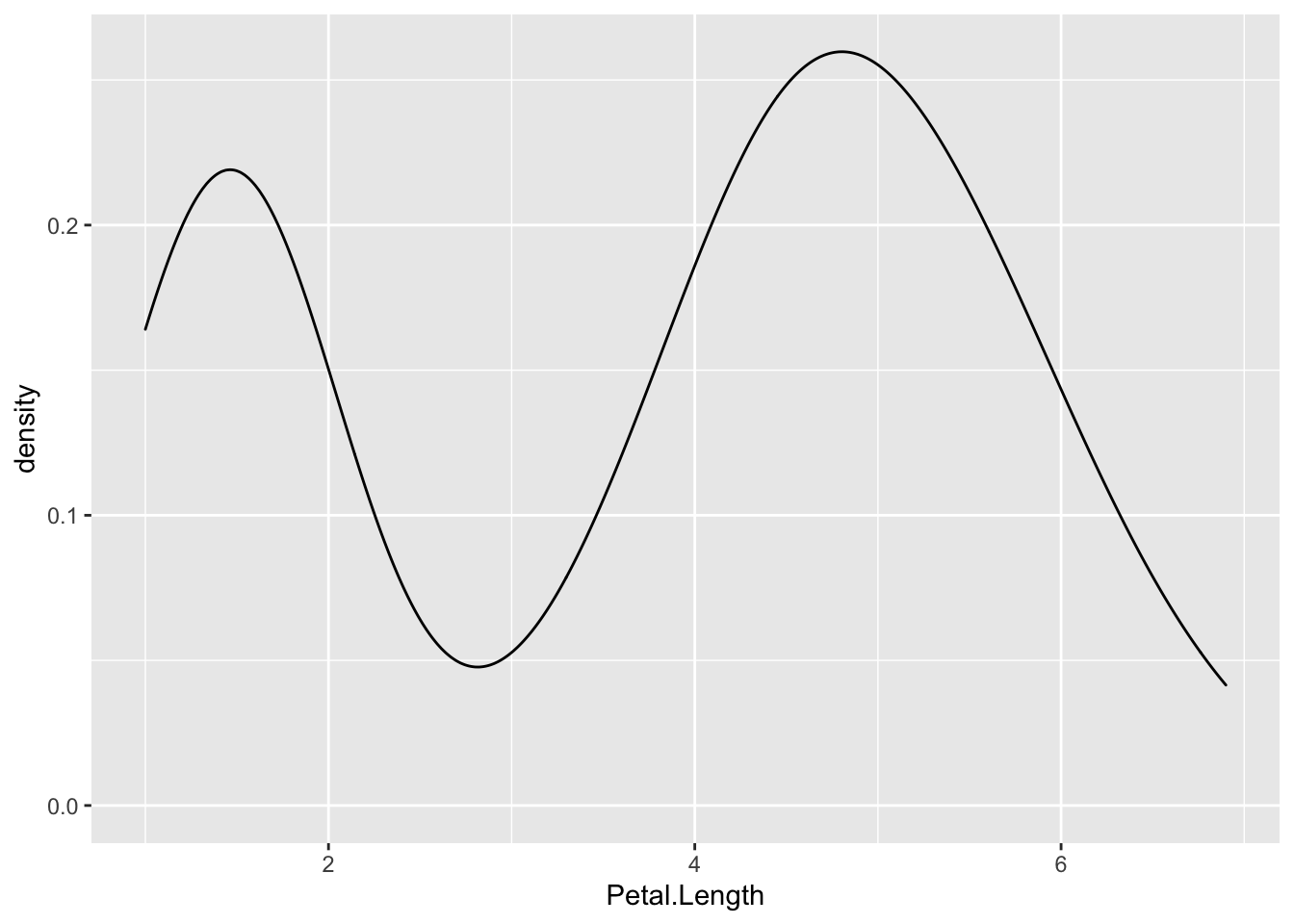
Since the two humps in the plot are about the same height, this shows that it’s not just one or two flowers with much smaller petal lengths, but rather that there are many. Thus, these observations aren’t likely outliers.
To investigate this further, we’ll look at petal length broken down by flower species:
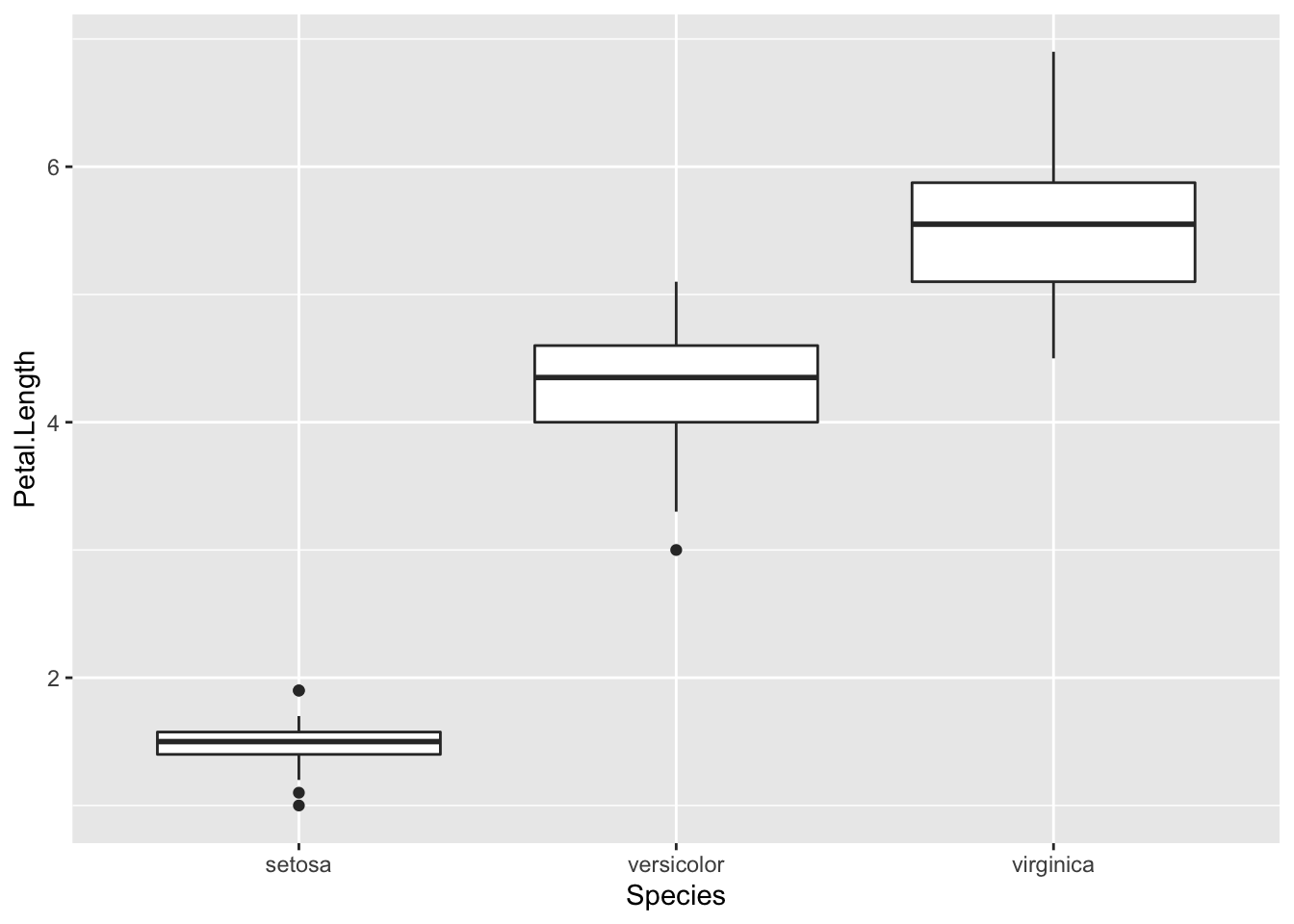
In this boxplot, we see in fact that setosa have a shorter petal length while virginica have the longest. Had we simply removed all the shorter petal length flowers from our dataset, we would have lost information about an entire species!
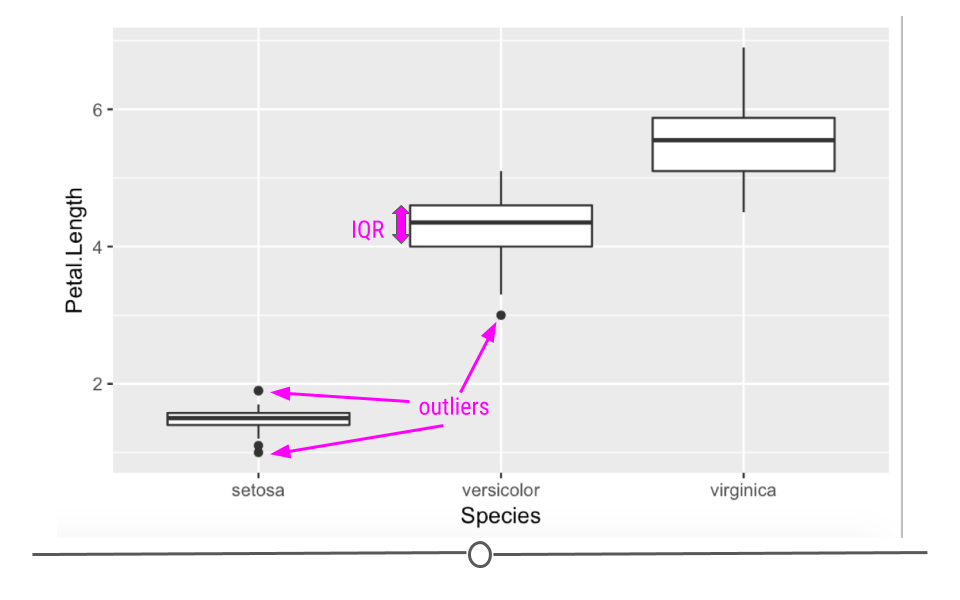
Boxplots are also helpful because they plot “outlier” samples as points outside the box. By default, boxplots define “outliers” as observations as those that are 1.5 x IQR (interquartile range). The IQR is the distance between the first and third quartiles. This is a mathematical way to determine if a sample may be an outlier. It is visually helpful, but then it’s up to the analyst to determine if an observation should be removed. While the boxplot identifies outliers in the setosa and versicolor species, these values are all within a reasonable distance of the rest of the values, and unless I could determine why this occurred, I would not remove these observations from the dataset.
5.5.4 Evaluating Variables
Central Tendency
Once you know how large your dataset is, what variables you have information on, how much missing data you’ve got for each variable, and the shape of your data, you’re ready to start understanding the information within the values of each variable.
Some of the simplest and most informative measures you can calculate on a numeric variable are those of central tendency. The two most commonly used measures of central tendency are: mean and median. These measures provide information about the typical or central value in the variable.
mean
The mean (often referred to as the average) is equal to the sum of all the observations in the variable divided by the total number of observations in the variable. The mean takes all the values in your variable and calculates the most common value.
median
The median is the middle observation for a variable after the observations in that variable have been arranged in order of magnitude (from smallest to largest). The median is the middle value.
Variability
In addition to measures of central tendency, measures of variability are key in describing the values within a variable. Two common and helpful measures of variability are: standard deviation and variance. Both of these are measures of how spread out the values in a variable are.
Variance
The variance tells you how spread out the values are. If all the values within your variable are exactly the same, that variable’s variance will be zero. The larger your variance, the more spread out your values are. Take the following vector and calculate its variance in R using the var() function:
## [1] 0## [1] 104733575040The only difference between the two vectors is that the second one has one value that is much larger than “29”. The variance for this vector is thus much higher.
Standard Deviation
By definition, the standard deviation is the square root of the variance, thus if we were to calculate the standard deviation in R using the sd() function, we’d see that the sd() function is equal to the square root of the variance:
## [1] 323625.7## [1] 323625.7For both measures of variance, the minimum value is 0. The larger the number, the more spread out the values in the valuable are.
5.5.4.1 Summarizing Your Data
Often, you’ll want to include tables in your reports summarizing your dataset. These will include the number of observations in your dataset and maybe the mean/median and standard deviation of a few variables. These could be organized into a table using what you learned in the data visualization course about generating tables.
5.5.4.1.1 skimr
Alternatively, there is a helpful package that will summarize all the variables within your dataset. The skimr package provides a tidy output with information about your dataset.
To use skimr, you’ll have to install and load the package before using the helpful function skim() to get a snapshot of your dataset.
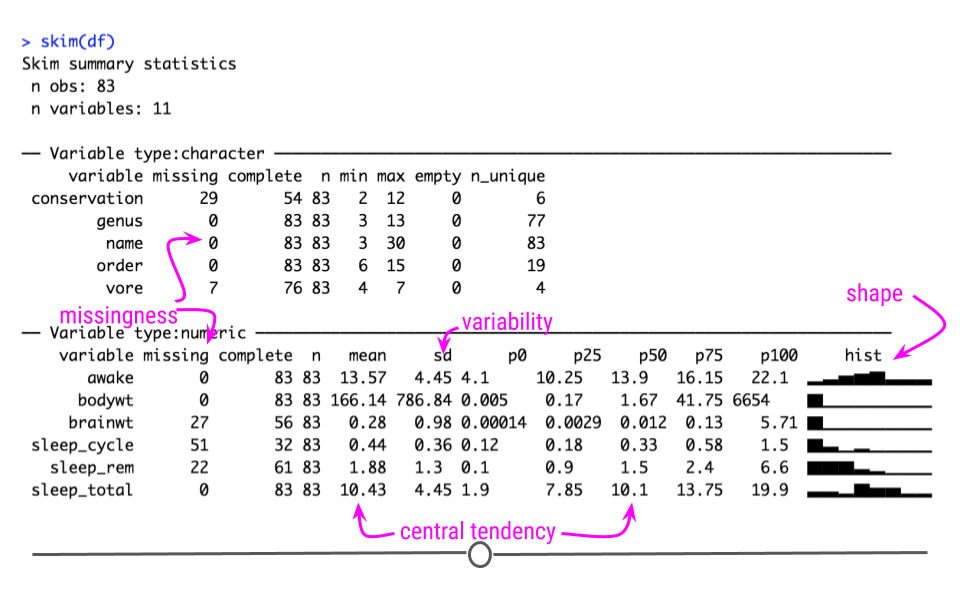
Using this function we can quickly get an idea about missingness, variability, central tendency, and shape, and outliers all at once.
The output from skim() separately summarizes categorical and continuous variables. For continuous variables you get information about the mean and median (p50) column. You know what the range of the variable is (p0 is the minimum value, p100 is the maximum value for continuous variables). You also get a measure of variability with the standard deviation (sd). It even quantifies the number of missing values (missing) and shows you the distribution or shape of each variable (hist)! Potential outliers can also be identified from the hist column and the p100 and p0 columns. This function can be incredibly useful to get a quick snapshot of what’s going on with your dataset.
If we take a look closer at the bodywt and brianwt variables, we can see that there may be outliers. The maximum value of the bodywt variable looks very different from the mean value.
## # A tibble: 1 × 11
## name genus vore order conservation sleep_total sleep_rem sleep_cycle awake
## <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Africa… Loxo… herbi Prob… vu 3.3 NA NA 20.7
## # ℹ 2 more variables: brainwt <dbl>, bodywt <dbl>Ah! looks like it is an elephant, that makes sense.
Taking a deeper look at the histogram we can see that there are two values that are especially different.
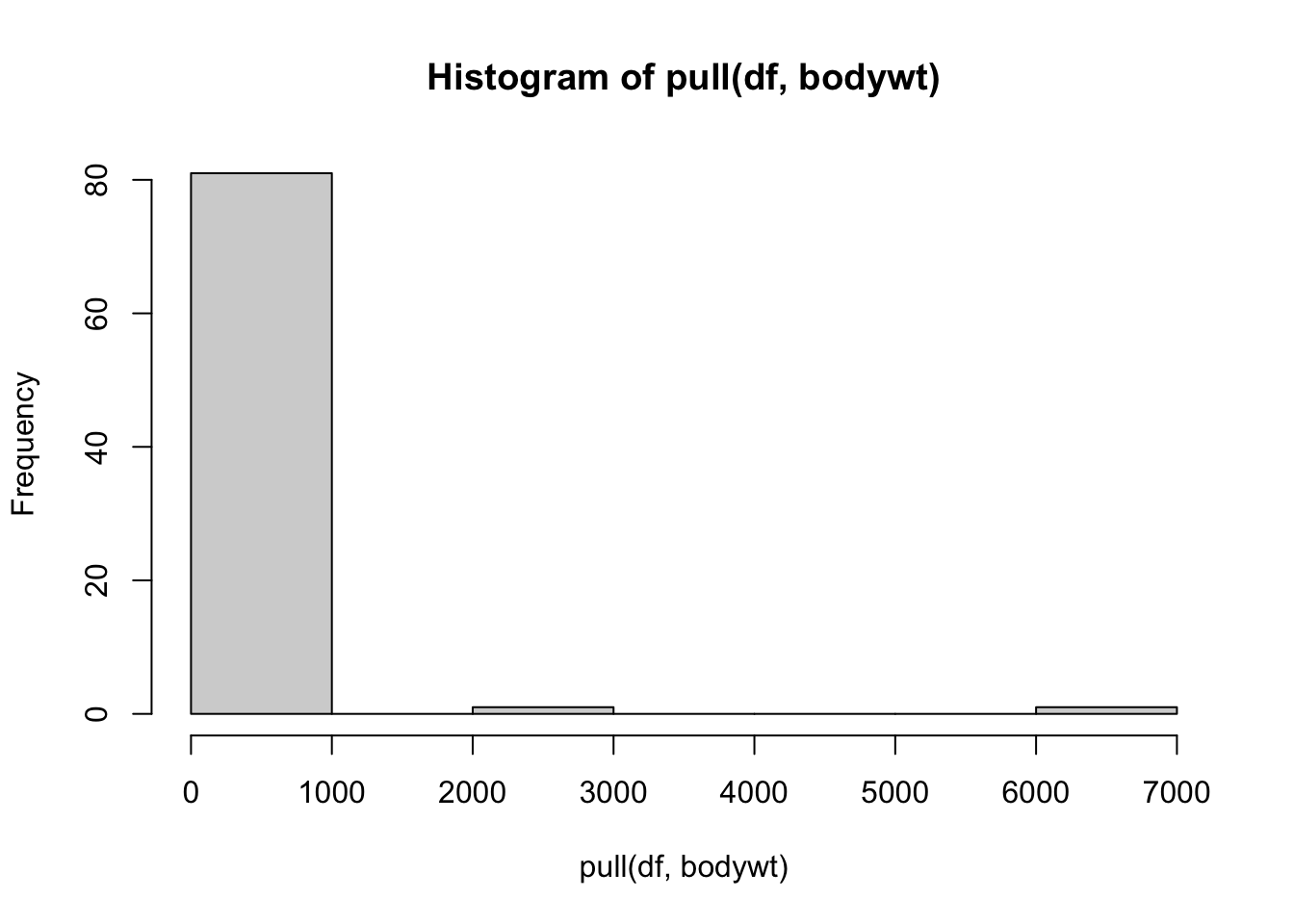
## # A tibble: 2 × 11
## name genus vore order conservation sleep_total sleep_rem sleep_cycle awake
## <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Asian … Elep… herbi Prob… en 3.9 NA NA 20.1
## 2 Africa… Loxo… herbi Prob… vu 3.3 NA NA 20.7
## # ℹ 2 more variables: brainwt <dbl>, bodywt <dbl>Looks like both data points are for elephants.
Therefore, we might consider performing an analysis both with and without the elephant data, to see if it influences the overall result.
5.5.5 Evaluating Relationships
Another important aspect of exploratory analysis is looking at relationships between variables.
Again visualizations can be very helpful.
We might want to look at the relationships between all of our continuous variables. A good way to do this is to use a visualization of correlation. As a reminder, correlation is a measure of the relationship or interdependence of two variables. In other words, how much do the values of one variable change with the values of another. Correlation can be either positive or negative and it ranges from -1 to 1, with 1 and -1 indicating perfect correlation (1 being positive and -1 being negative) and 0 indicating no correlation. We will describe this in greater detail when we look at associations.
Here are some very useful plots that can be generated using the GGally package and the PerformanceAnalytics package to examine if variables are correlated.
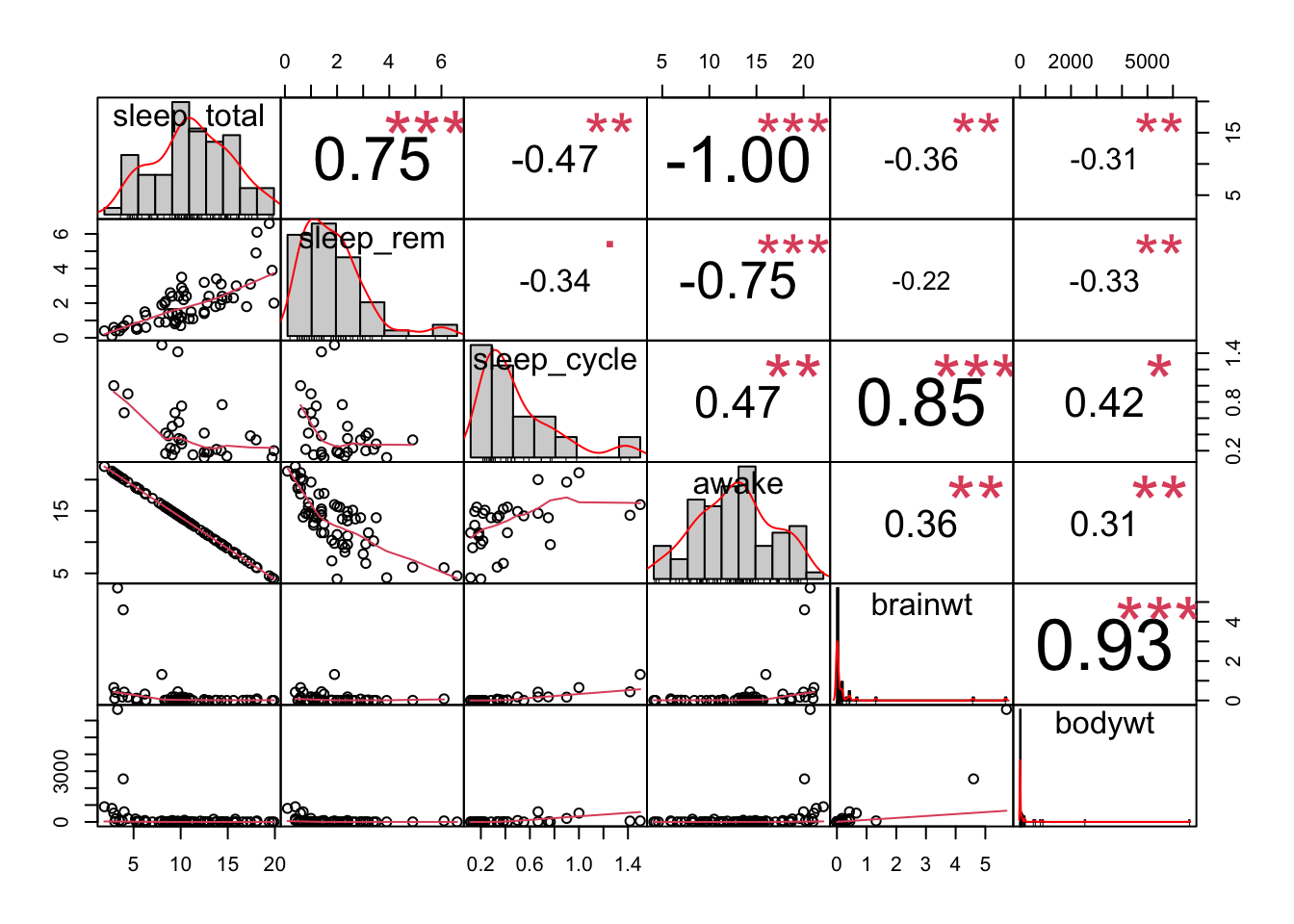
## Registered S3 method overwritten by 'GGally':
## method from
## +.gg ggplot2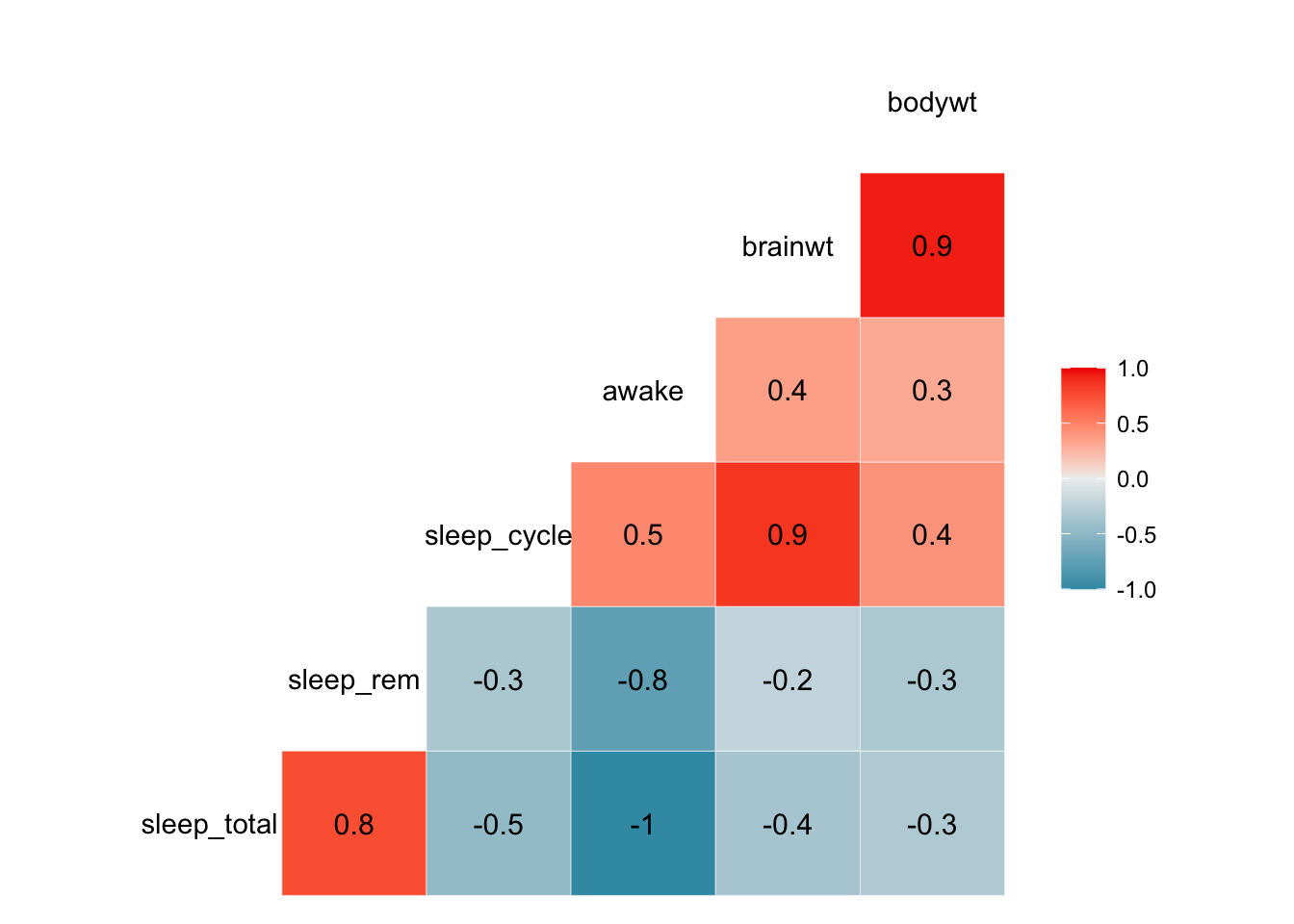
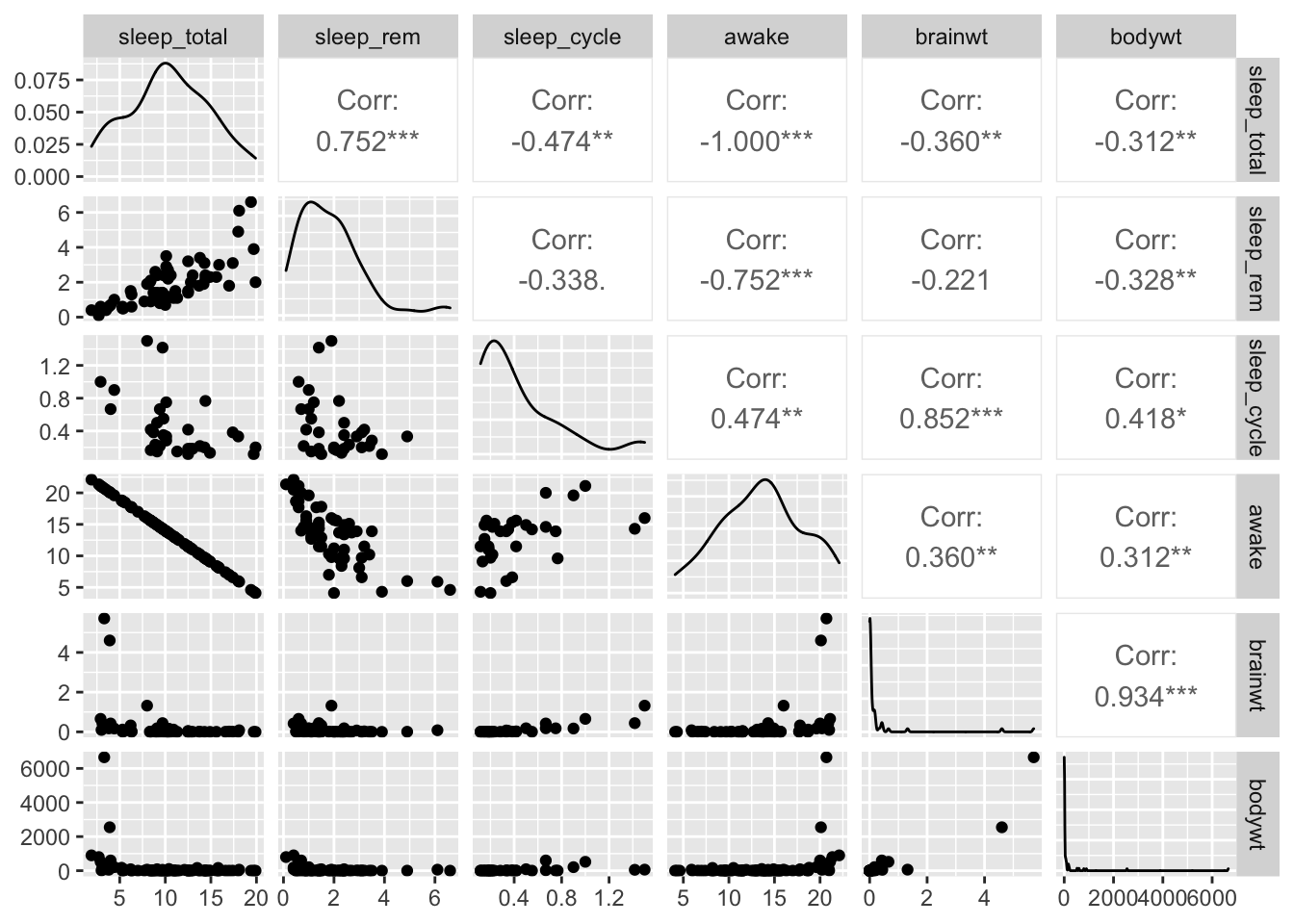
We can see from these plots that the awake variable and the sleep_total variable are perfectly correlated. This becomes important for choosing what to include in models when we try to perform prediction or inference analyses.
We may be especially interested in how brain weight (brain_wt) relates to body weight (body_wt). We might assume that these to variables might be related to one another.
Here is a plot of the these two variables including the elephant data:
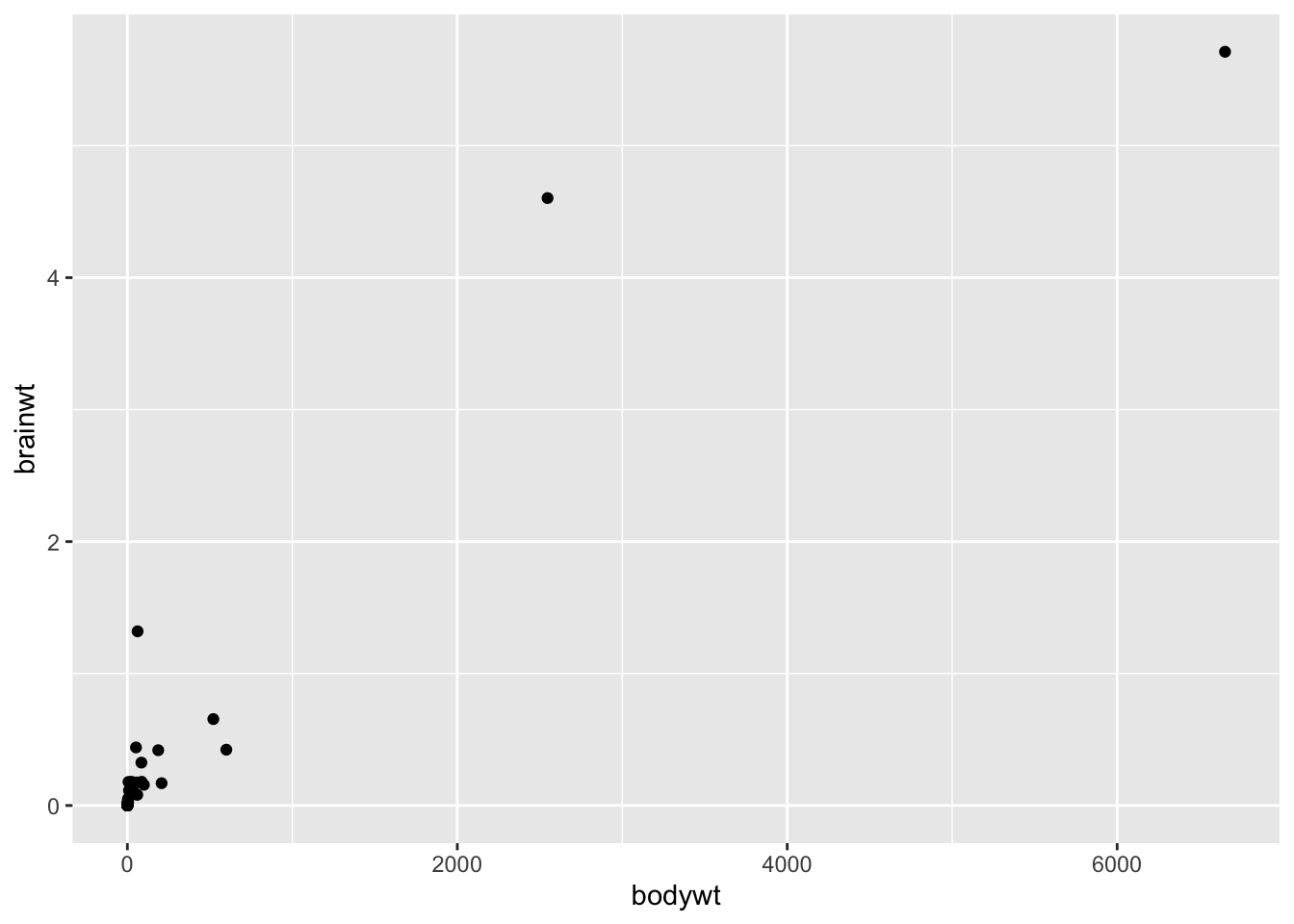
Clearly, including the elephant data points makes it hard to look at the other data points, it is possible that these points are driving the positive correlation that we get when we use all the data. Here is a plot of the relationship between these to variables excluding the elephant data and the very low body weight organisms:
library(ggplot2)
df %>%
filter(bodywt<2000 & bodywt >1) %>%
ggplot(aes(x = bodywt, y = brainwt)) +
geom_point()+
geom_smooth(method = "lm", se = FALSE)## `geom_smooth()` using formula = 'y ~ x'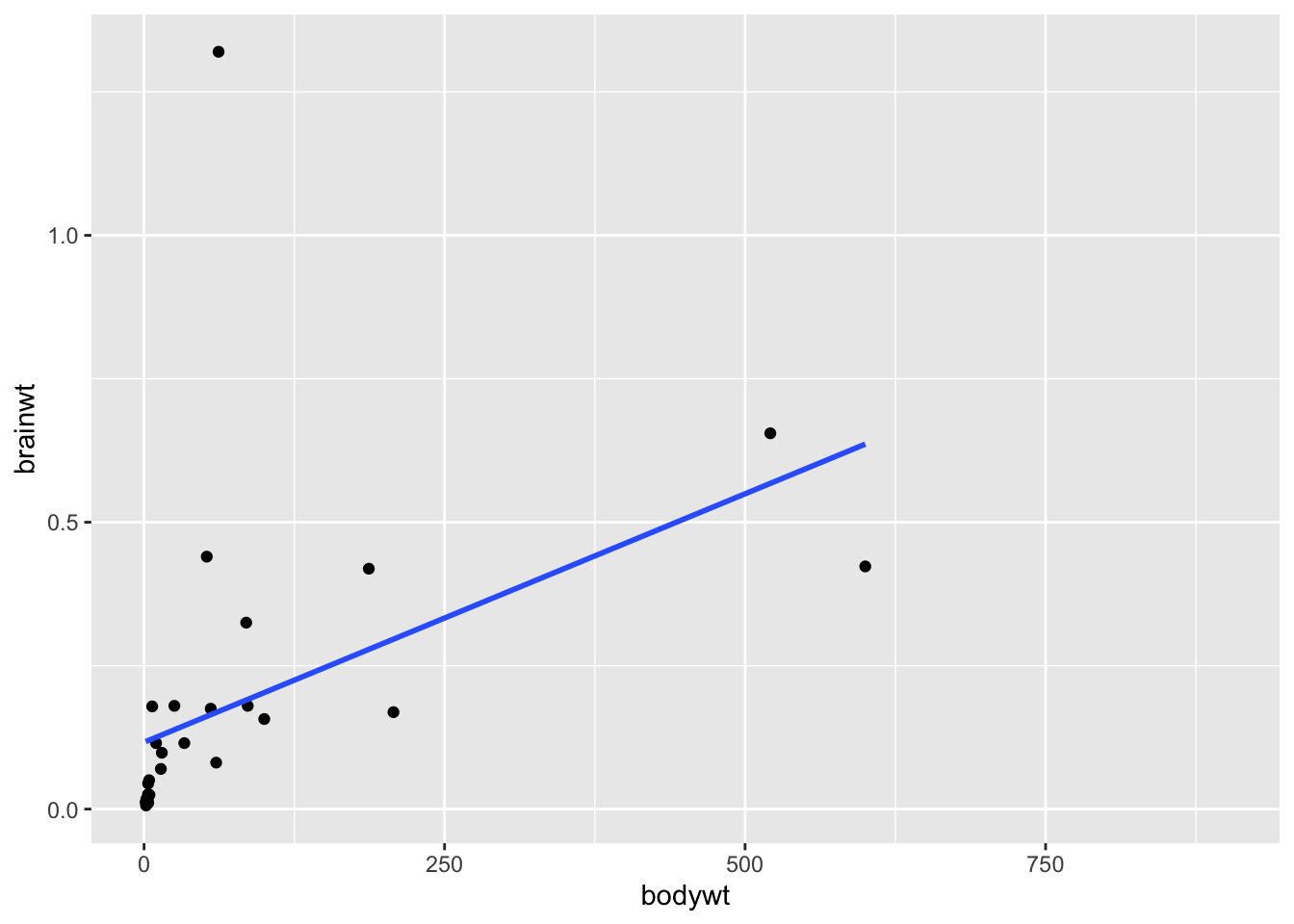
cor.test(pull(df %>% filter(bodywt<2000 & bodywt >1),bodywt),
pull(df %>%filter(bodywt<2000 & bodywt >1),brainwt))##
## Pearson's product-moment correlation
##
## data: pull(df %>% filter(bodywt < 2000 & bodywt > 1), bodywt) and pull(df %>% filter(bodywt < 2000 & bodywt > 1), brainwt)
## t = 2.7461, df = 28, p-value = 0.01042
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.1203262 0.7040582
## sample estimates:
## cor
## 0.4606273We can see from this plot that in general brainwt is correlated with bodywt. Or in other words, brainwt tends to increase with bodywt.
But it also looks like we have an outlier for our brainwt variable! There is a very high brainwt value that is greater than 1.
We can also see it in our histogram of this variable:
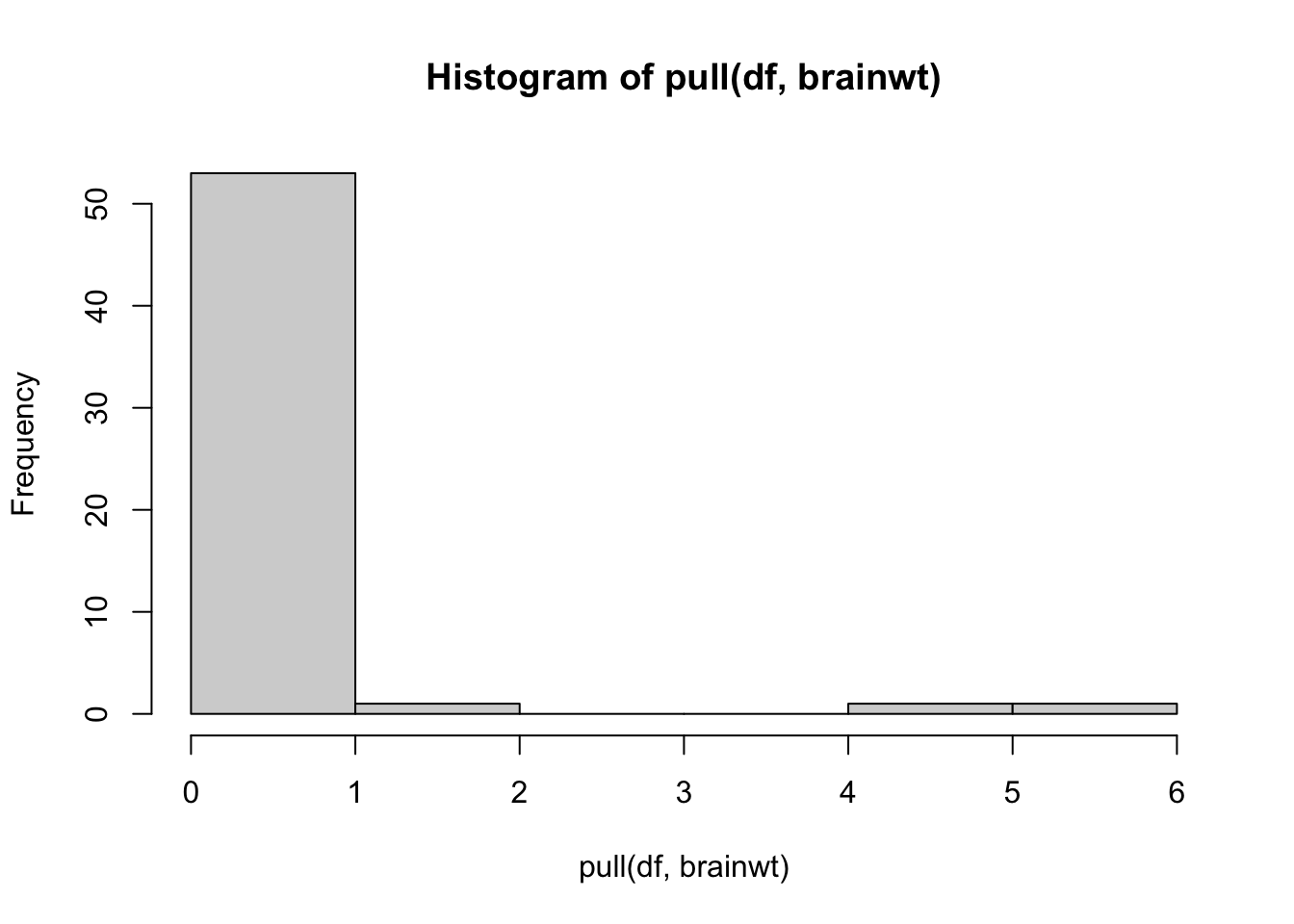
Let’s see which organism this is:
## # A tibble: 3 × 11
## name genus vore order conservation sleep_total sleep_rem sleep_cycle awake
## <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Asian … Elep… herbi Prob… en 3.9 NA NA 20.1
## 2 Human Homo omni Prim… <NA> 8 1.9 1.5 16
## 3 Africa… Loxo… herbi Prob… vu 3.3 NA NA 20.7
## # ℹ 2 more variables: brainwt <dbl>, bodywt <dbl>It is humans! Let’s see what the plot looks like without humans:
library(ggplot2)
df %>%
filter(bodywt<2000 & bodywt >1 & brainwt<1) %>%
ggplot(aes(x = bodywt, y = brainwt)) +
geom_point()+
geom_smooth(method = "lm", se = FALSE)## `geom_smooth()` using formula = 'y ~ x'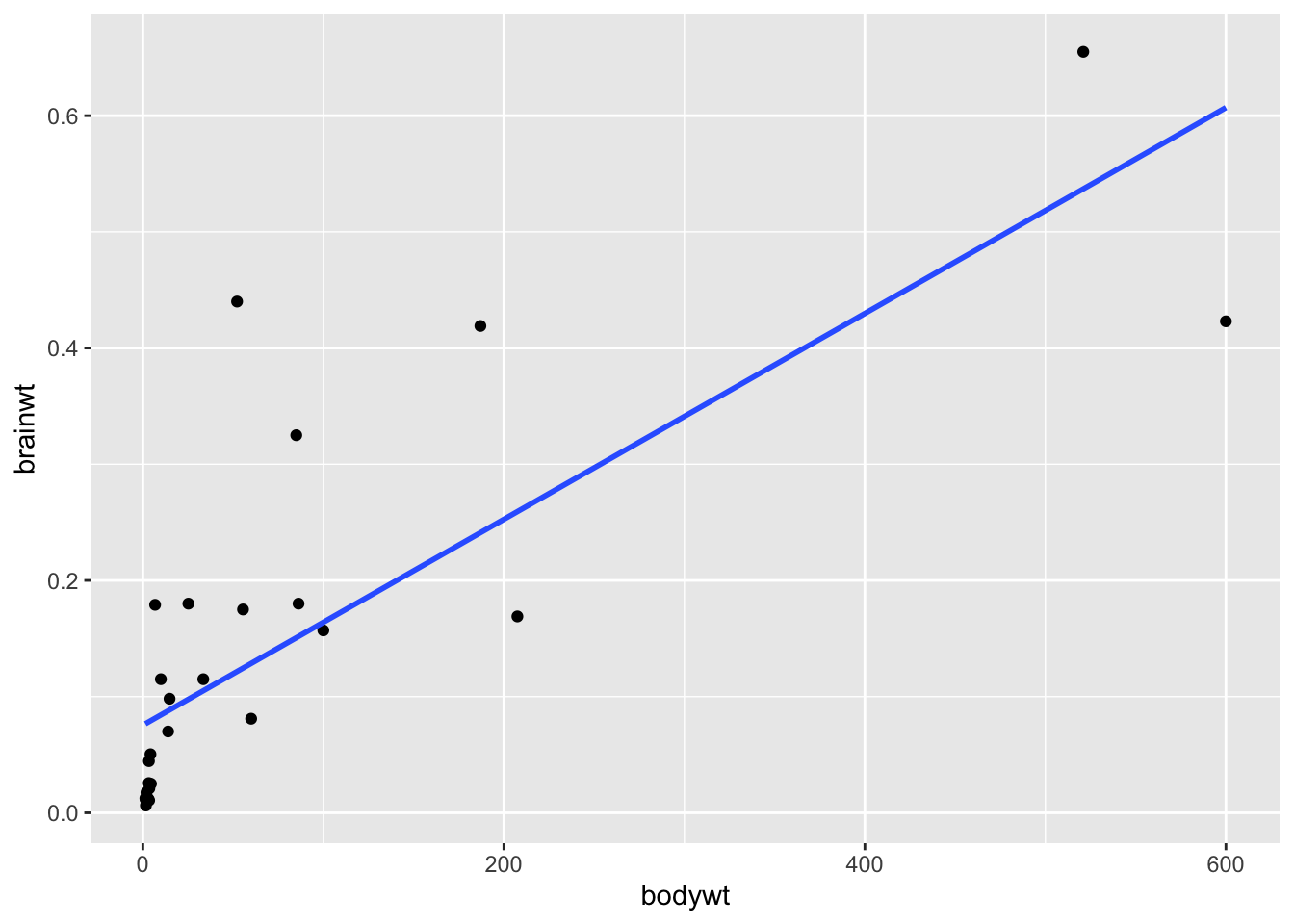
cor.test(pull(df %>% filter(bodywt<2000 & bodywt >1 & brainwt<1),bodywt),
pull(df %>%filter(bodywt<2000 & bodywt >1 & brainwt<1),brainwt))##
## Pearson's product-moment correlation
##
## data: pull(df %>% filter(bodywt < 2000 & bodywt > 1 & brainwt < 1), bodywt) and pull(df %>% filter(bodywt < 2000 & bodywt > 1 & brainwt < 1), brainwt)
## t = 6.6127, df = 27, p-value = 4.283e-07
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.5897381 0.8949042
## sample estimates:
## cor
## 0.7862926We can see from these plots that the brainwt variable seems to have a relationship (correlation value = 0.79) with bodywt and it increases with the bodywt variable, however this relationship is less strong when humans are included (correlation value = 0.46). This information would be important to keep in mind when trying to model this data to make inference or predictions about the animals included.
5.6 Inference
Inferential Analysis is what analysts carry out after they’ve described and explored their dataset. After understanding your dataset better, analysts often try to infer something from the data. This is done using statistical tests.
We discussed a bit about how we can use models to perform inference and prediction analyses. What does this mean?
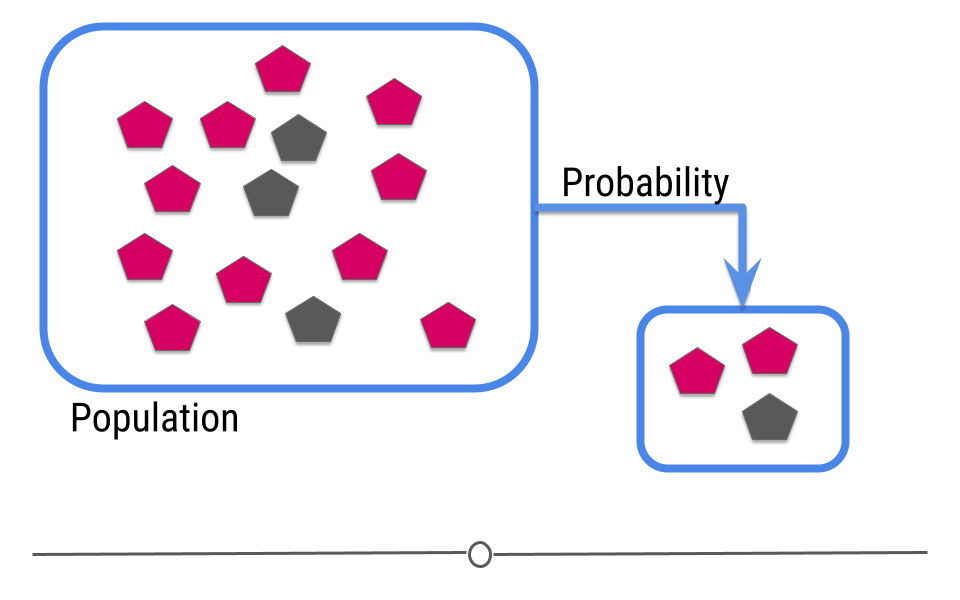
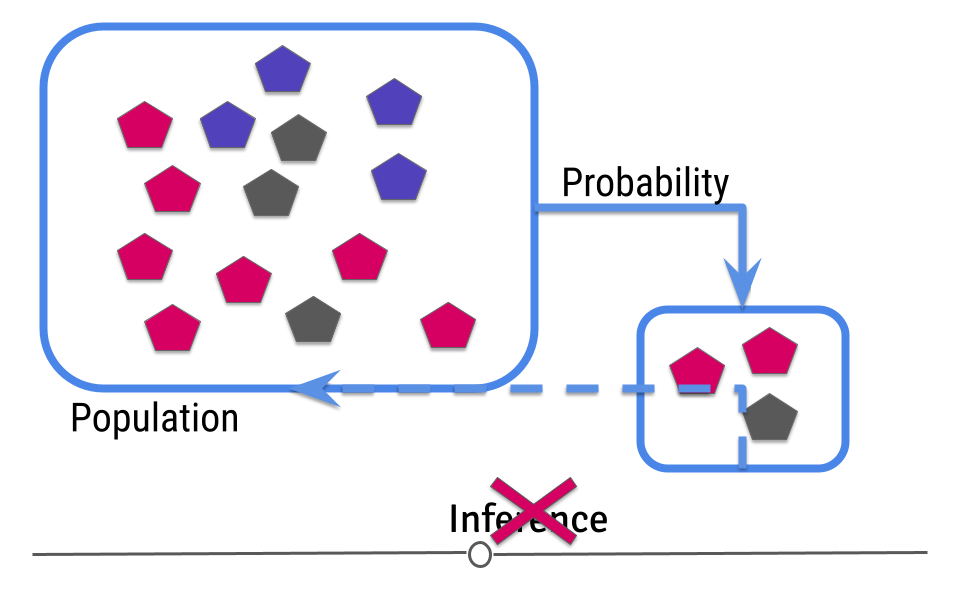
The goal of inferential analyses is to use a relatively small sample of data to infer or say something about the population at large. This is required because often we want to answer questions about a population. Let’s take a dummy example here where we have a population of 14 shapes. Here, in this graphic, the shapes represent individuals in the population and the colors of the shapes can be either pink or grey:
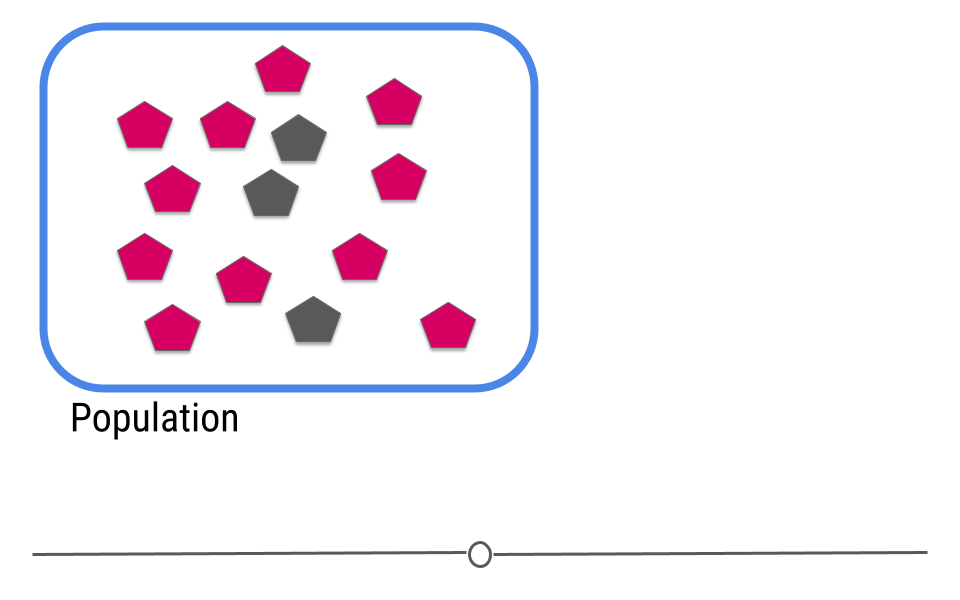
In this example we only have fourteen shapes in the population; however, in inferential data analysis, it’s not usually possible to sample everyone in the population. Consider if this population were everyone in the United States or every college student in the world. As getting information from every individual would be infeasible. Data are instead collected on a subset, or a sample of the individuals in the larger population.
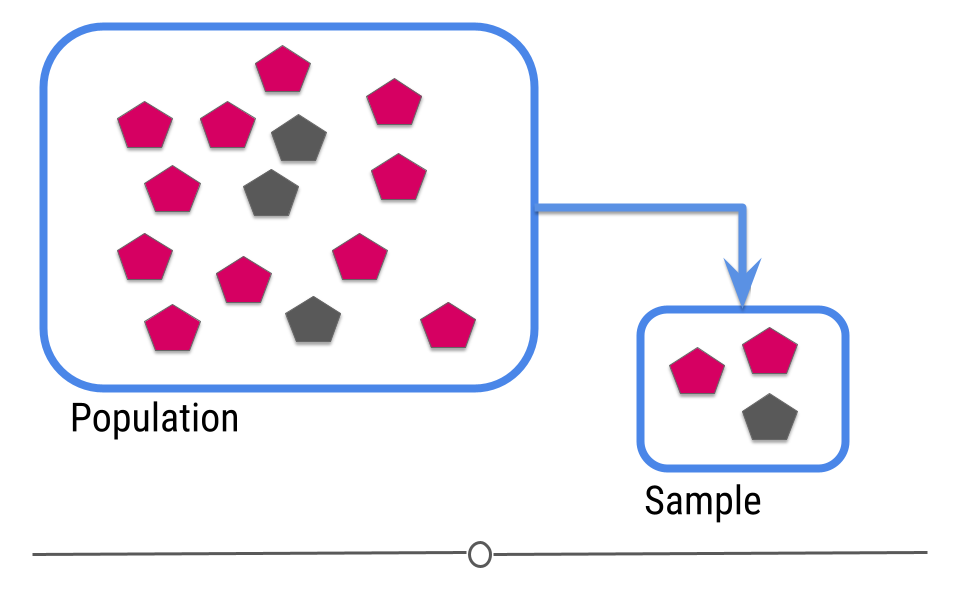
In our example, we’ve been showing you how many pink and how many gray shapes are in the larger population. However, in real life, we don’t know what the answer is in the larger population. That’s why we collected the sample!
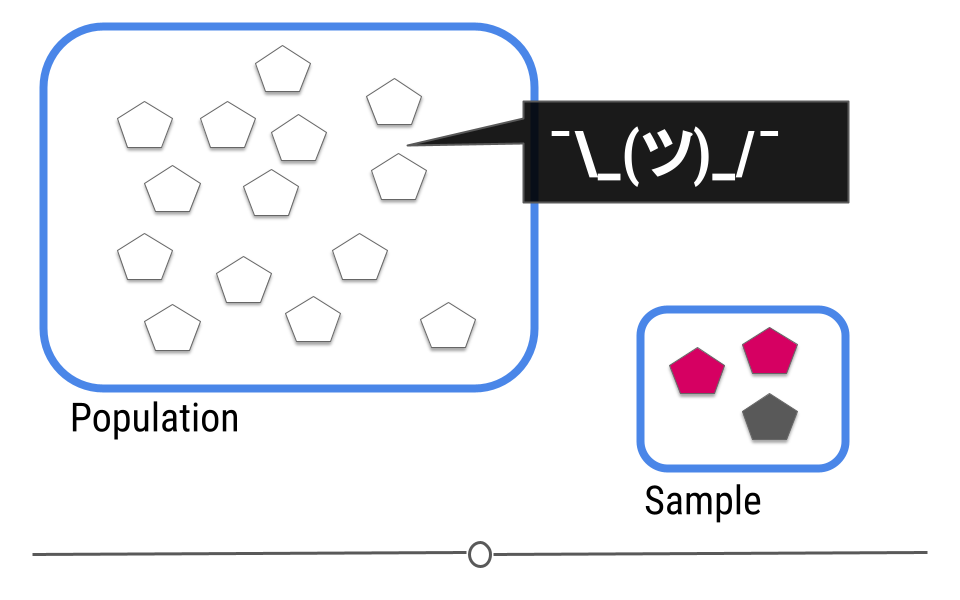
This is where inference comes into play. We analyze the data collected in our sample and then do our best to infer what the answer is in the larger population. In other words, inferential data analysis uses data from a sample to make its best guess as to what the answer would be in the population if we were able to measure every individual.
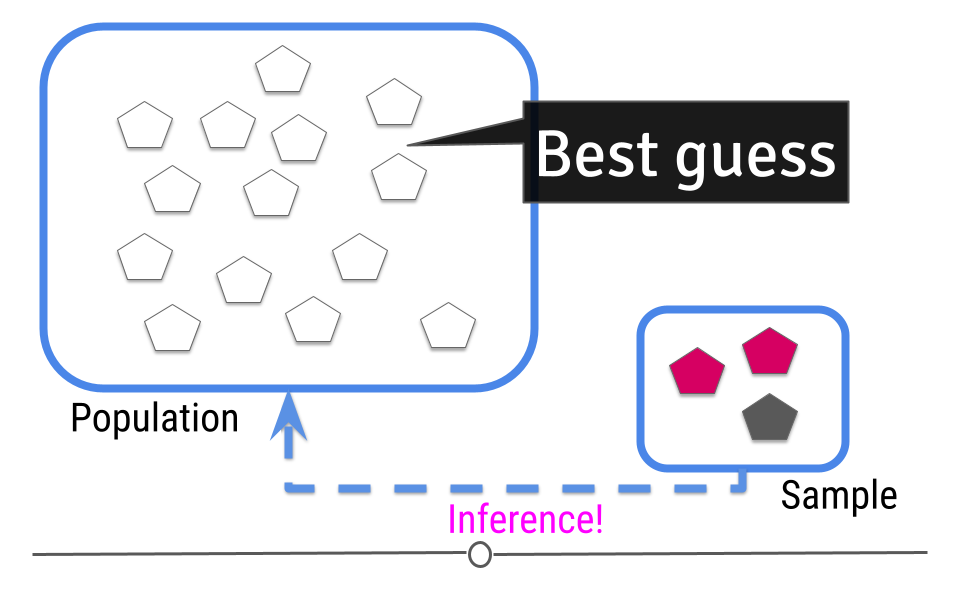
5.6.1 Uncertainty
Because we haven’t directly measured the population but have only been able to take measurements on a sample of the data, when making our inference we can’t be exactly sure that our inference about the population is exact. For example, in our sample one-third of the shapes are grey. We’d expect about one-third of the shapes in our population to be grey then too! Well, one-third of 14 (the number of shapes in our population) is 4.667. Does this mean four shapes are truly gray?
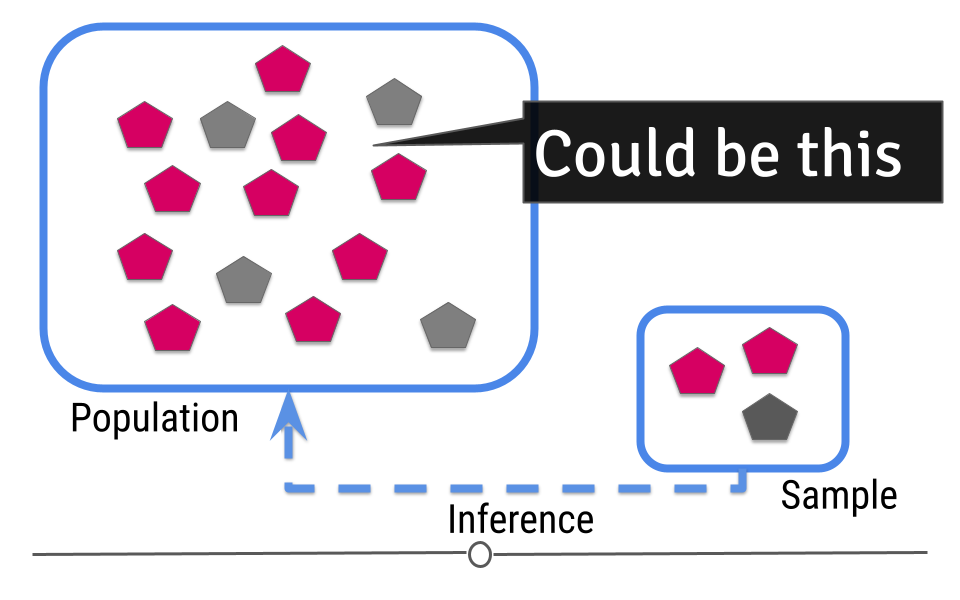
Or maybe five shapes in the population are grey?
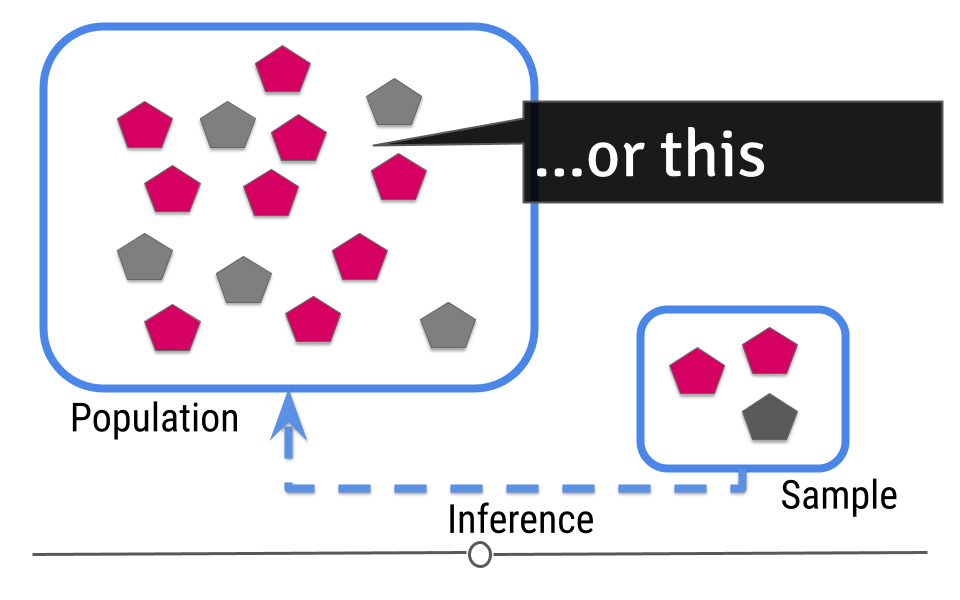
Given the sample we’ve taken, we can guess that 4-5 shapes in our population will be grey, but we aren’t certain exactly what that number is. In statistics, this “best guess” is known as an estimate. This means that we estimate that 4.667 shapes will be gray. But, there is uncertainty in that number. Because we’re taking our best guess at figuring out what that estimate should be, there’s also a measure of uncertainty in that estimate. Inferential data analysis includes generating the estimate and the measure of uncertainty around that estimate.
Let’s return back to the example where we know the truth in the population. Hey look! There were actually only three grey shapes after all. It is totally possible that if you put all those shapes into a bag and pulled three out that two would be pink and one would be grey. As statisticians, we’d say that getting this sample was probable (it’s within the realm of possibility). This really drives home why it’s important to add uncertainty to your estimate whenever you’re doing inferential analysis!
5.6.2 Random Sampling
Since you are moving from a small amount of data and trying to generalize to a larger population, your ability to accurately infer information about the larger population depends heavily on how the data were sampled.
The data in your sample must be representative of your larger population to be used for inferential data analysis. Let’s discuss what this means.
Using the same example, what if, in your larger population, you didn’t just have grey and pink shapes, but you also had blue shapes?
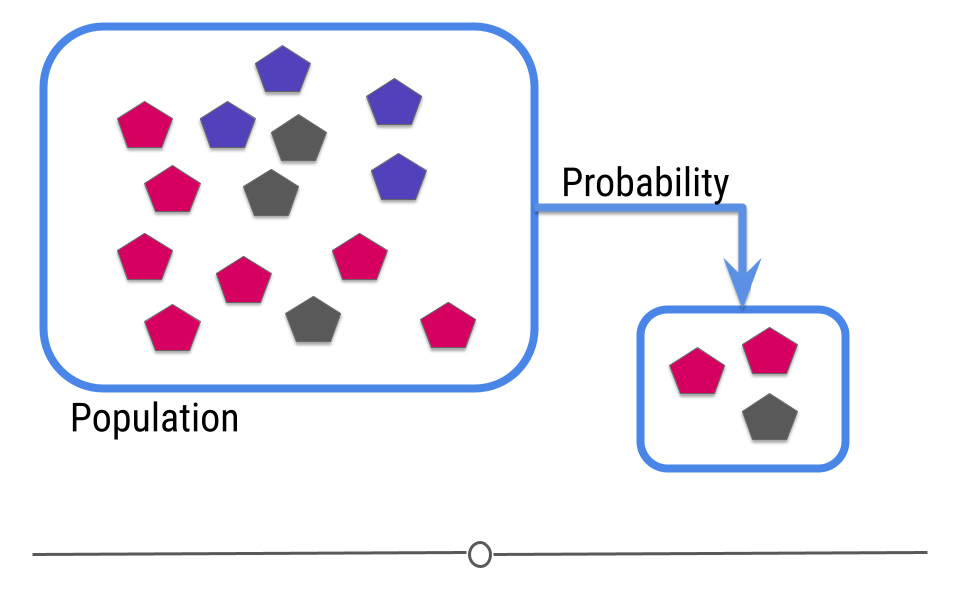
Well, if your sample only has pink and grey shapes, when you go to make an inference, there’s no way you’d infer that there should be blue shapes in your population since you didn’t capture any in your sample.
In this case, your sample is not representative of your larger population. In cases where you do not have a representative sample, you can not carry out inference, since you will not be able to correctly infer information about the larger population.
This means that you have to design your analysis so that you’re collecting representative data and that you have to check your data after data collection to make sure that you were successful.
You may at this point be thinking to yourself. “Wait a second. I thought I didn’t know what the truth was in the population. How can I make sure it’s representative?” Good point! With regards to the measurement you’re making (color distribution of the shapes, in this example), you don’t know the truth. But, you should know other information about the population. What is the age distribution of your population? Your sample should have a similar age distribution. What proportion of your population is female? If it’s half, then your sample should be comprised of half females. Your data collection procedure should be set up to ensure that the sample you collect is representative (very similar to) your larger population. Then, once the data are collected, your descriptive analysis should check to ensure that the data you’ve collected are in fact representative of your larger population. Randomly sampling your larger population helps ensure that the inference you make about the measurement of interest (color distribution of the shapes) will be the most accurate.
To reiterate: If the data you collect is not from a representative sample of the population, the generalizations you infer won’t be accurate for the population.
5.6.2.1 An example of inferential data analysis
Unlike in our previous examples, Census data wouldn’t be used for inferential analysis. By definition, a census already collects information on (functionally) the entire population. Thus, there is no population on which to infer. Census data are the rare exception where a whole population is included in the dataset. Further, using data from the US census to infer information about another country would not be a good idea because the US isn’t necessarily representative of the other country.
Instead, a better example of a dataset on which to carry out inferential analysis would be the data used in the study: The Effect of Air Pollution Control on Life Expectancy in the the United States: An Analysis of 545 US counties for the period 2000 to 2007. In this study, researchers set out to understand the effect of air pollution on everyone in the United States
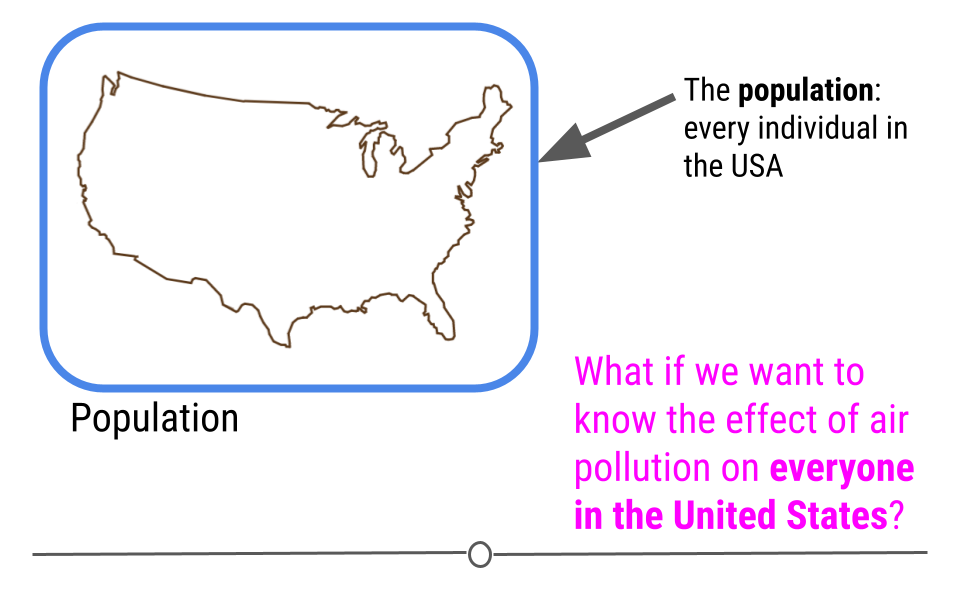
To answer this question, a subset of the US population was studied, and the researchers looked at the level of air pollution experienced and life expectancy. It would have been nearly impossible to study every individual in the United States year after year. Instead, this study used the data they collected from a sample of the US population to infer how air pollution might be impacting life expectancy in the entire US!
5.7 Linear Modeling
5.7.1 Linear Regression
Inferential analysis is commonly the goal of statistical modeling, where you have a small amount of information to extrapolate and generalize that information to a larger group. One of the most common approaches used in statistical modeling is known as linear regression. Here, we’ll discuss how to recognize when using linear regression is appropriate, how to carry out the analysis in R, and how to interpret the results from this statistical approach.
When discussing linear regression, we’re trying to describe (model) the relationship between a dependent variable and an independent variable.
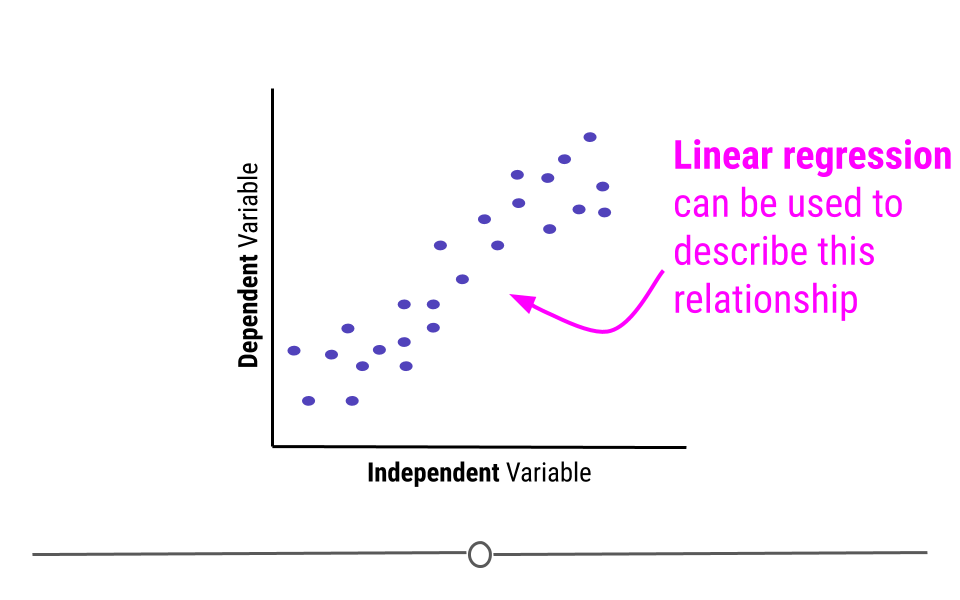
When visualizing a linear relationship, the independent variable is plotted along the bottom of the graph, on the x-axis and the dependent variable is plotted along the side of the plot, on the y-axis.
When carrying out linear regression, a best-fitting line is drawn through the data points to describe the relationship between the variables.
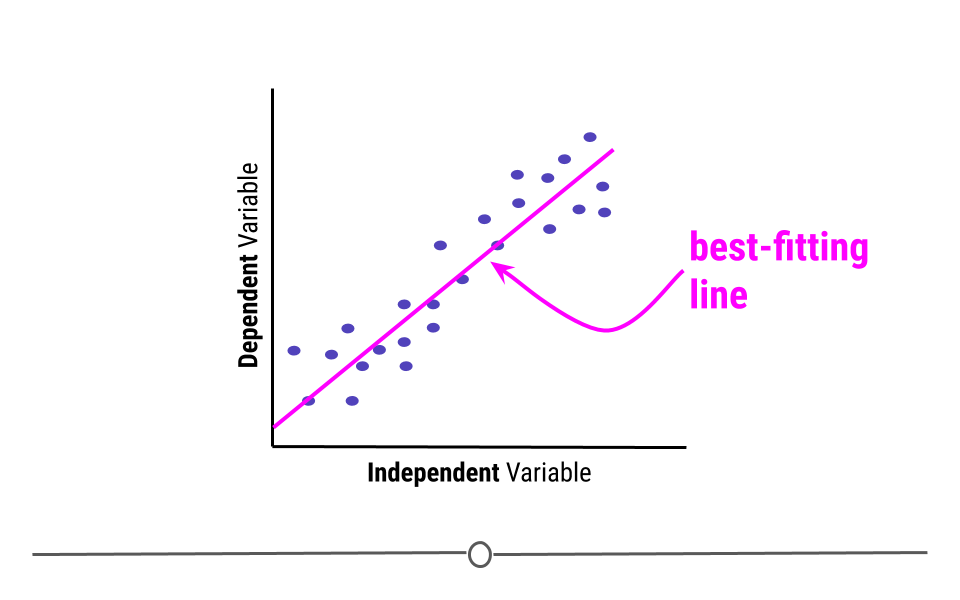
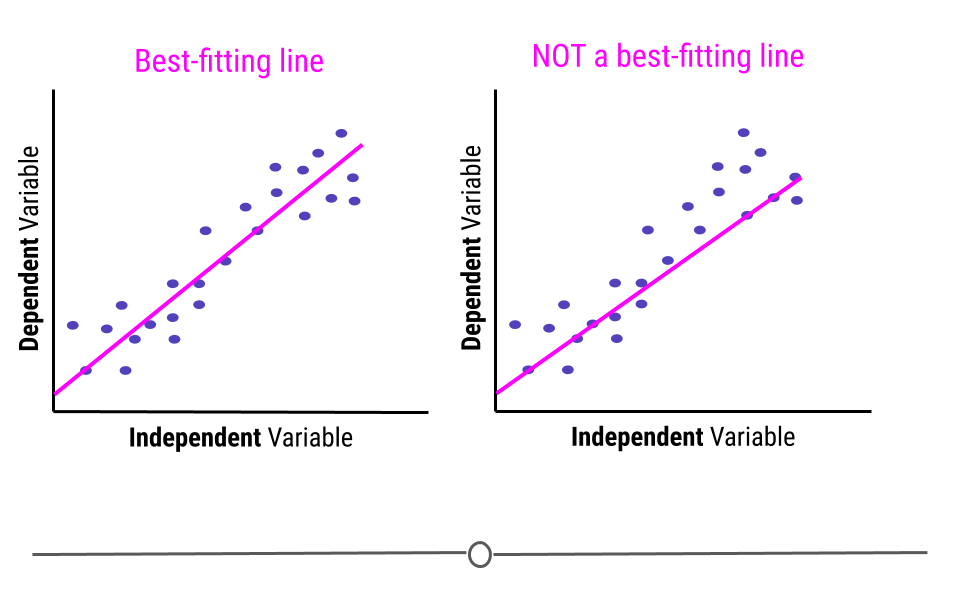
A best-fitting line, technically-speaking, minimizes the sum of the squared errors. In simpler terms, this means that the line that minimizes the distance of all the points from the line is the best-fitting line. Or, most simply, there are about the same number of points above the line as there are below the line. In total, the distance from the line for the points above the line will be the same as the distance from the points to the line below the line.
Note that the best fitting line does not have to go through any points to be the best-fitting line. Here, on the right, we see a line that goes through seven points on the plot (rather than the four the best-fitting line goes through, on the left). However, this is not a best-fitting line, as there are way more points above the line than there are below the line.
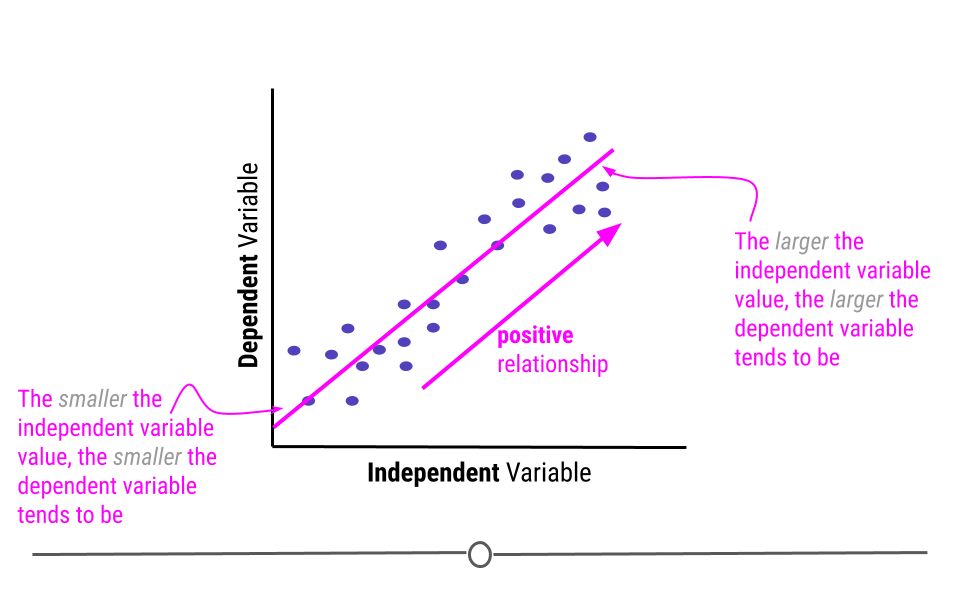
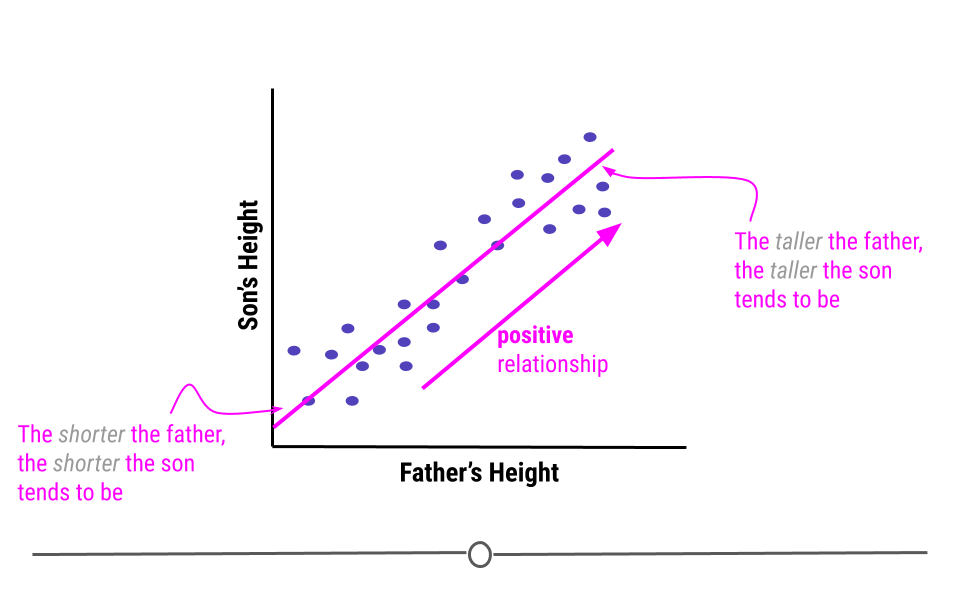
This line describes the relationship between the two variables. If you look at the direction of the line, it will tell you whether there is a positive or a negative relationship between the variables. In this case, the larger the value of the independent variable, the larger the value of the dependent variable. Similarly, the smaller the value of the independent variable, the smaller the value of the dependent variable. When this is the case, there is a positive relationship between the two variables.
An example of variables that have a positive relationship would be the height of fathers and their sons. In general, the taller a father is, the taller his son will be. And, the shorter a father is the more likely his son is to be short.
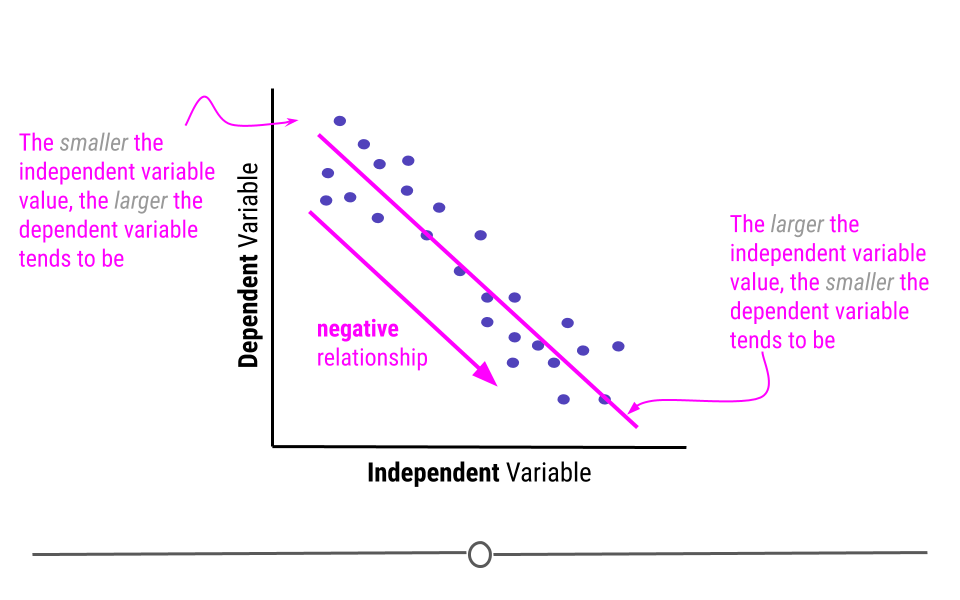
Alternatively, when the higher the value of the independent variable, the lower the value of the dependent variable, this is a negative relationship.
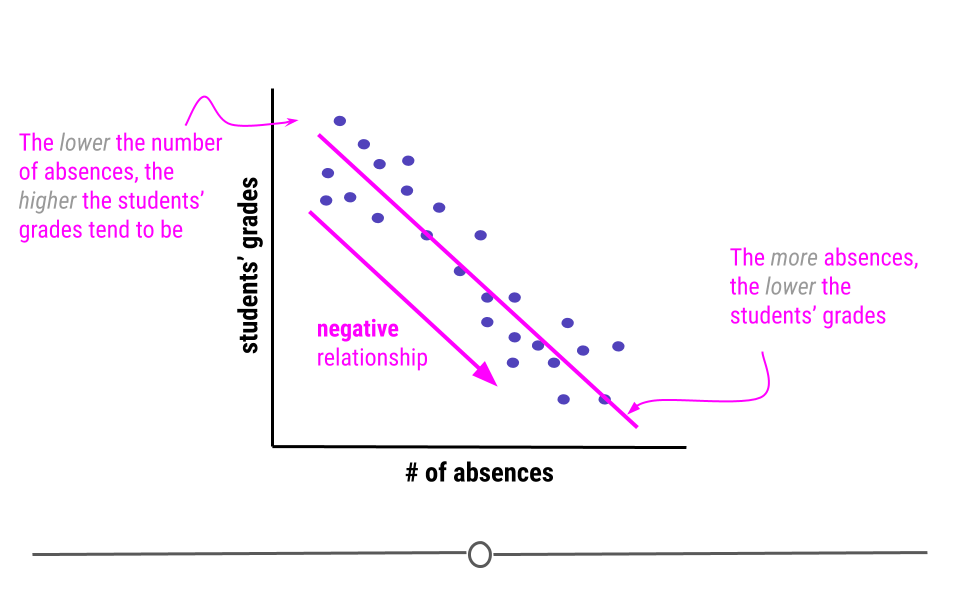
An example of variables that have a negative relationship would be the relationship between a students’ absences and their grades. The more absences a student has, the lower their grades tend to be.
Linear regression, in addition to to describing the direction of the relationship, it can also be used to determine the strength of that relationship.
This is because the assumption with linear regression is that the true relationship is being described by the best-fitting line. Any points that fall away from the line do so due to error. This means that if all the points fall directly on top of the line, there is no error. The further the points fall from the line, the greater the error. When points are further from the best-fitting line, the relationship between the two variables is weaker than when the points fall closer to the line.
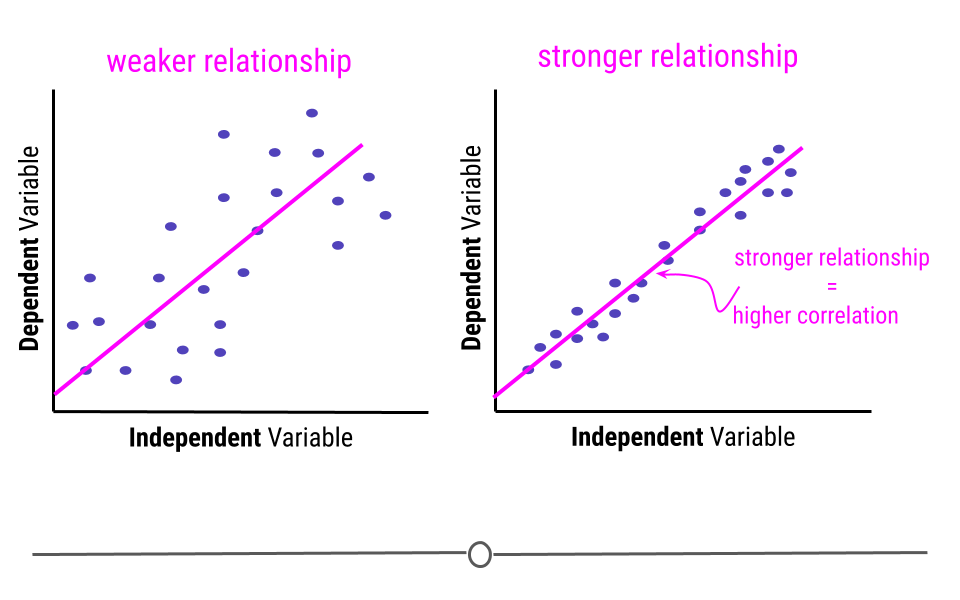
In this example, the pink line is exactly the same best-fitting line in each graph. However, on the left, where the points fall further from the line, the strength of the relationship between these two variables is weaker than on the right, where the points fall closer to the line, where the relationship is stronger. The strength of this relationship is measured using correlation. The closer the points are to the line the more correlated the two variables are, meaning the relationship between the two variables is stronger.
5.7.2 Assumptions
Thus far we have focused on drawing linear regression lines. Linear regression lines can be drawn on any plot, but just because you can do something doesn’t mean you actually should. When it comes to linear regression, in order to carry our any inference on the relationship between two variables, there are a few assumptions that must hold before inference from linear regression can be done.
The two assumptions of simple linear regression are linearity and homoscedasticity.
5.7.2.1 Linearity
The relationship between the two variables must be linear.
For example, what if we were plotting data from a single day and we were looking at the relationship between temperature and time. Well, we know that generally temperature increases throughout the day and then decreases in the evening. Here, we see some example data reflective of this relationship. The upside-down u-shape of the data suggests that the relationship is not in fact linear. While we could draw a straight line through these data, it would be inappropriate. In cases where the relationship between the variables cannot be well-modeled with a straight line, linear regression should not be used.
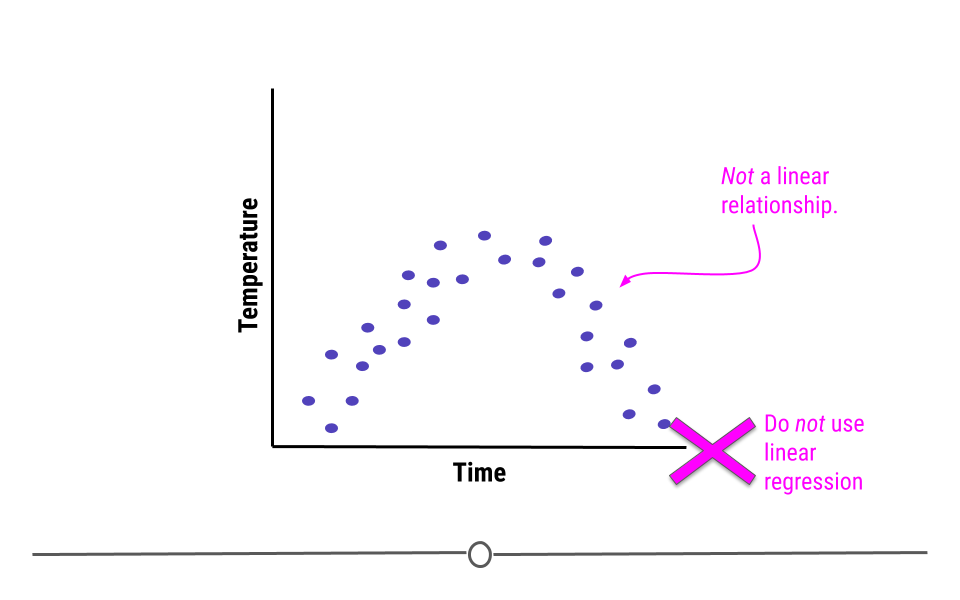
5.7.2.2 Homoscedasticity
In addition to displaying a linear relationship, the random variables must demonstrate homoscedasticity. In other words, the variance (distance from the line) must be constant throughout the variable.
If points at one end are much closer to the best-fitting line than points are at the other end, homoscedasticity has been violated and linear regression is not appropriate for the data.
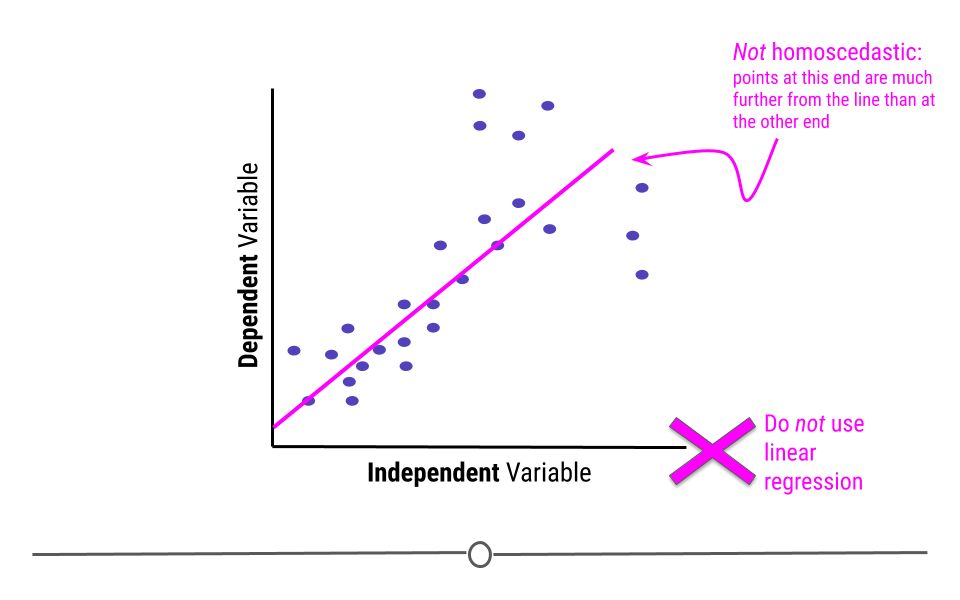
5.7.2.3 Normality of residuals
When we fit a linear regression, typically the data do not fall perfectly along the regression line. Rather, there is some distance from each point to the line. Some points are quite close to the line, while others are further away. Each point’s distance to the regression line can be calculated. This distance is the residual measurement.
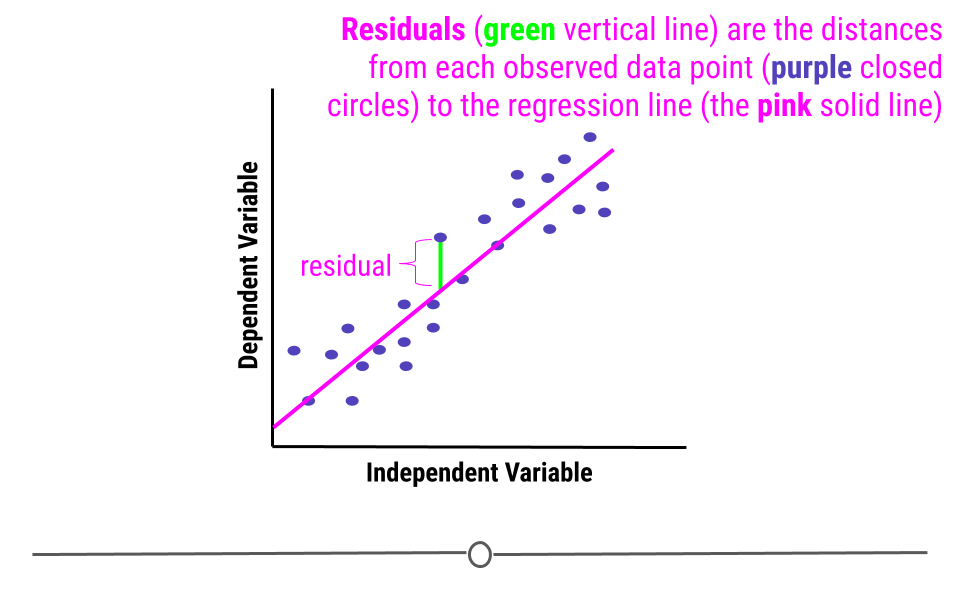
In linear regression, one assumption is that these residuals follow a Normal distribution. This means that if you were to calculate each residual (each point’s distance to the regression line) and then plot a histogram of all of those values - that plot should look like a Normal Distribution.
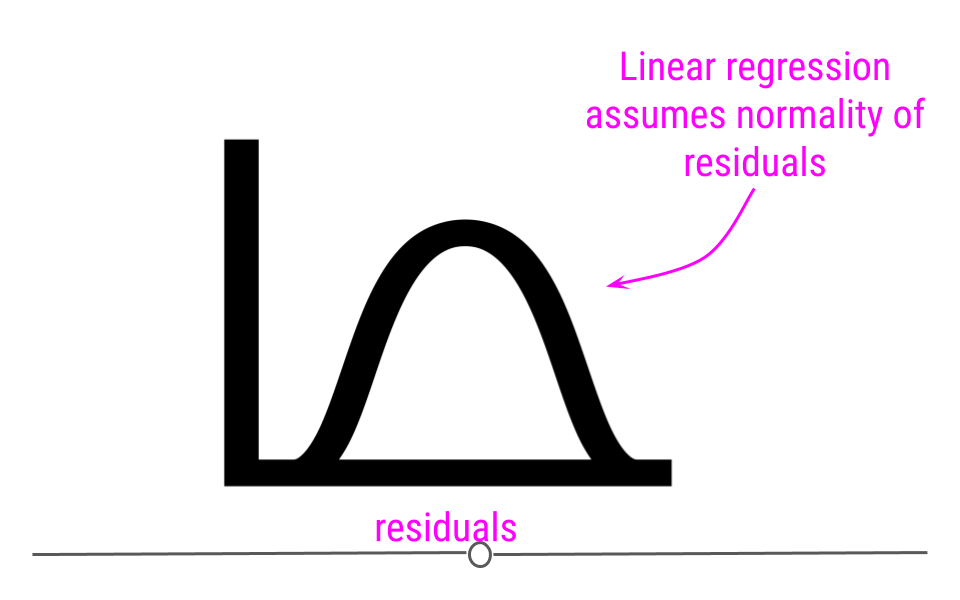
If you do not see normality of residuals, this can suggest that outlier values - observations more extreme than the rest of the data - may exist in your data. This can severely affect you regression results and lead you to conclude something that is untrue about your data.
Thus, it is your job, when running linear regression to check for:
- Non-linearity
- Heteroscedasticity
- Outlier values
- Normality of residuals
We’ll discuss how to use diagnostic plots below to check that these assumptions have been met and that outlier values are not severely affecting your results.
What can linear regression infer?
Now that we understand what linear regression is and what assumptions must hold for its use, when would you actually use it? Linear regression can be used to answer many different questions about your data. Here we’ll discuss specifically how to make inferences about the relationship between two numeric variables.
5.7.3 Association
Often when people are carrying out linear regression, they are looking to better understand the relationship between two variables. When looking at this relationship, analysts are specifically asking “What is the association between these two variables?” Association between variables describes the trend in the relationship (positive, neutral, or negative) and the strength of that relationship (how correlated the two variables are).
After determining that the assumptions of linear regression are met, in order to determine the association between two variables, one would carry out a linear regression. From the linear regression, one would then interpret the Beta estimate and the standard error from the model.
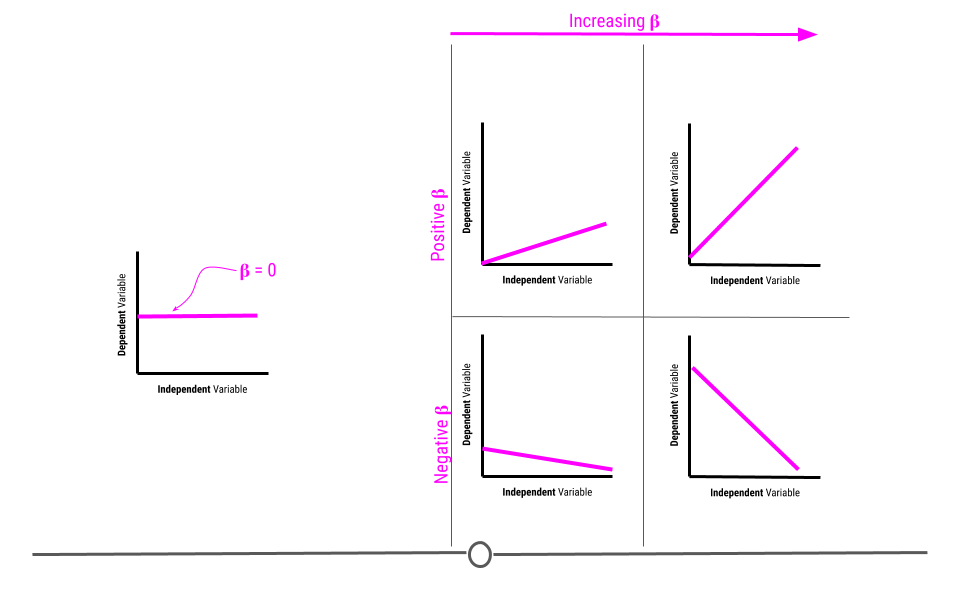
5.7.3.1 Beta estimate
The beta estimate determines the direction and strength of the relationship between the two variables.
A beta of zero suggests there is no association between the two variables. However, if the beta value is positive, the relationship is positive. If the value is negative, the relationship is negative. Further, the larger the number, the bigger the effect is. We’ll discuss effect size and how to interpret the value in more detail later in this lesson.
5.7.3.2 Standard error
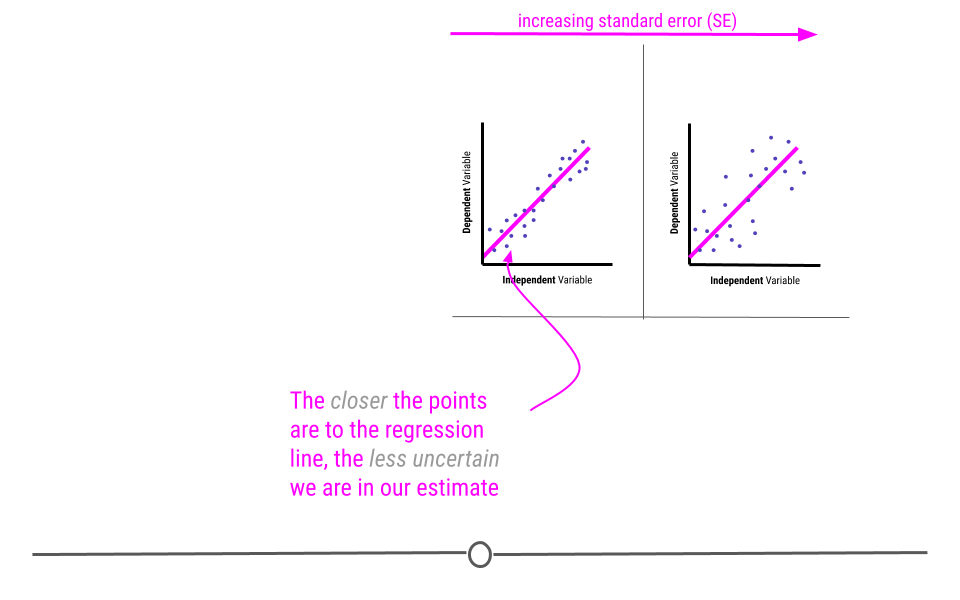
The standard error determines how uncertain the beta estimate is. The larger the standard error, the more uncertain we are in the estimate. The smaller the standard error, the less uncertain we are in the estimate.
Standard errors are calculated based on how well the best-fitting line models the data. The closer the points are to the line, the lower the standard error will be, reflecting our decreased uncertainty. However, as the points are further from the regression line, our uncertainty in the estimate will increase, and the standard error will be larger.
Remember when carrying out inferential data analysis, you will always want to report an estimate and a measure of uncertainty. For linear regression, this will be the beta estimate and the standard error.
You may have heard talk of p-values at some point. People tend to use p-values to describe the strength of their association due to its simplicity. The p-value is a single number that takes into account both the estimate (beta estimate) and the uncertainty in that estimate (SE). The lower a p-value the more significant the association is between two variables. However, while it is a simple value, it doesn’t tell you nearly as much information as reporting the estimates and standard errors directly. Thus, if you’re reporting p-values, it’s best to also include the estimate and standard errors as well.
That said, the general interpretation of a p-value is “the probability of getting the observed results (or results more extreme) by chance alone.” Since it’s a probability, the value will always be between 0 and 1. Then, for example, a p-value of 0.05, means that 5 percent of the time (or 1 in 20), you’d observe results this extreme simply by chance.
5.7.4 Association Testing in R
Now that we’ve discussed what you can learn from an association test, let’s look at an example in R. For this example we’ll use the trees dataset available in R, which includes girth, height, and volume measurements for 31 black cherry trees.
With this dataset, we’ll answer the question:
Can we infer the height of a tree given its girth?Presumably, it’s easier to measure a trees girth (width around) than it is to measure its height. Thus, here we want to know whether or not height and girth are associated.
In this case, since we’re asking if we can infer height from girth, girth is the independent variable and height is the dependent variable. In other words, we’re asking does height depend on girth?
First, before carrying out the linear regression to test for association and answer this question, we have to be sure linear regression is appropriate. We’ll test for linearity and homoscedasticity.
To do so, we’ll first use ggplot2 to generate a scatterplot of the variables of interest.
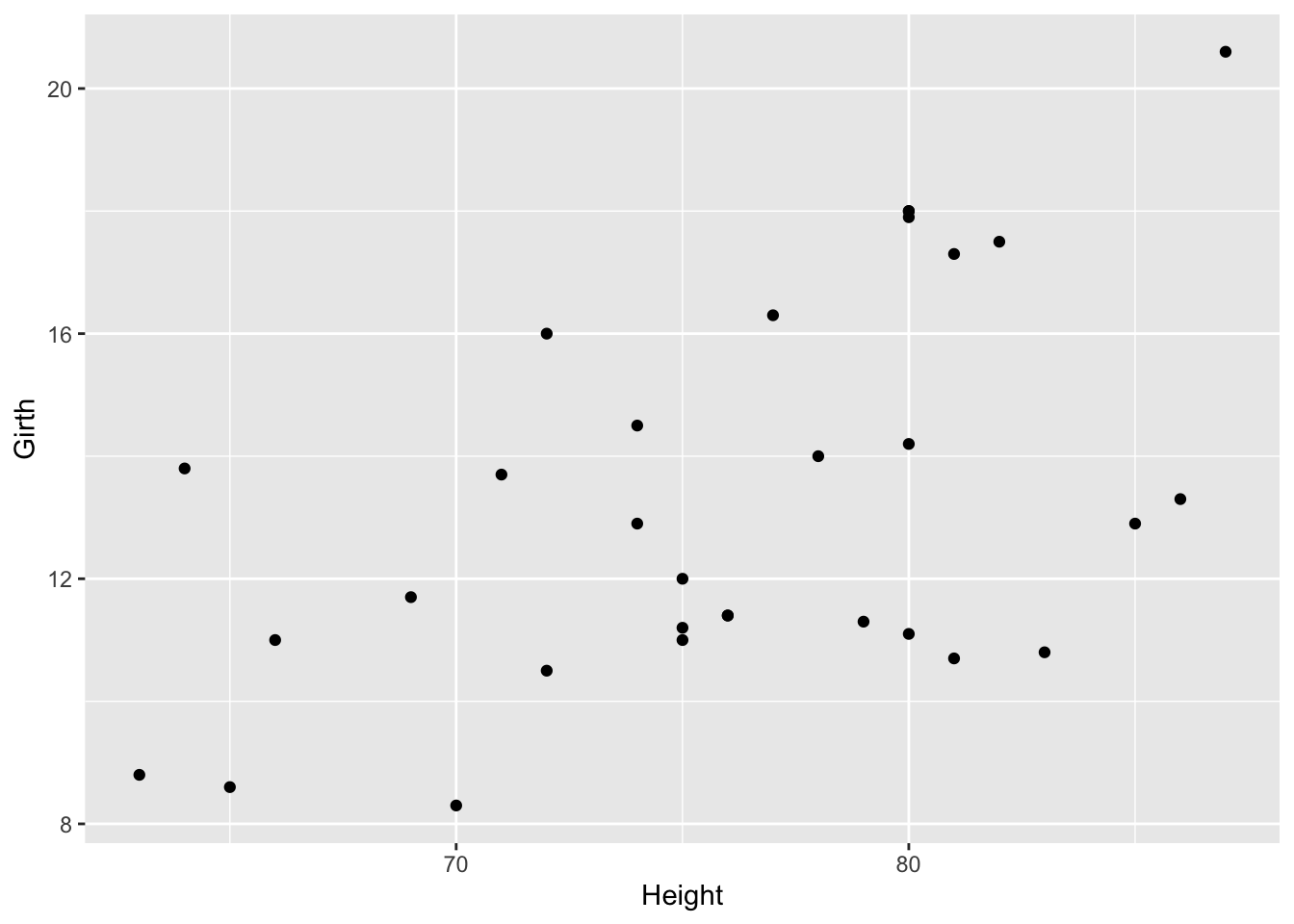
From the looks of this plot, the relationship looks approximately linear, but to visually make this a little easier, we’ll add a line of best first to the plot.
## `geom_smooth()` using formula = 'y ~ x'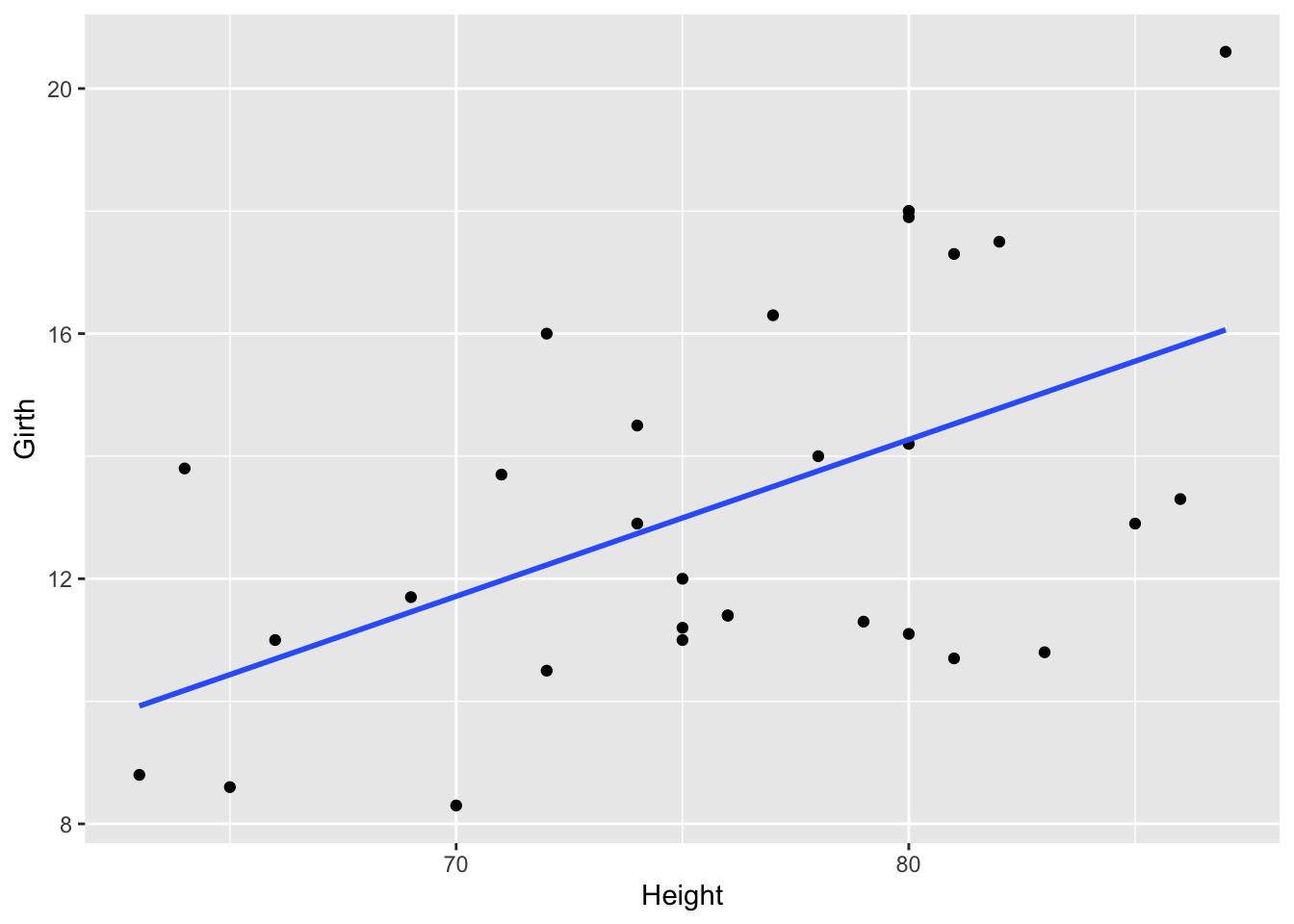
On this graph, the relationship looks approximately linear and the variance (distance from points to the line) is constant across the data. Given this, it’s appropriate to use linear regression for these data.
5.7.5 Fitting the Model
Now that that’s established, we can run the linear regression. To do so, we’ll use the lm() function to fit the model. The syntax for this function is lm(dependent_variable ~ independent_variable, data = dataset).
5.7.6 Model Diagnostics
Above, we discussed a number of assumptions of linear regression. After fitting a model, it’s necessary to check the model to see if the model satisfies the assumptions of linear regression. If the model does not fit the data well (for example, the relationship is nonlinear), then you cannot use and interpret the model.
In order to assess your model, a number of diagnostic plots can be very helpful. Diagnostic plots can be generated using the plot() function with the fitted model as an argument.
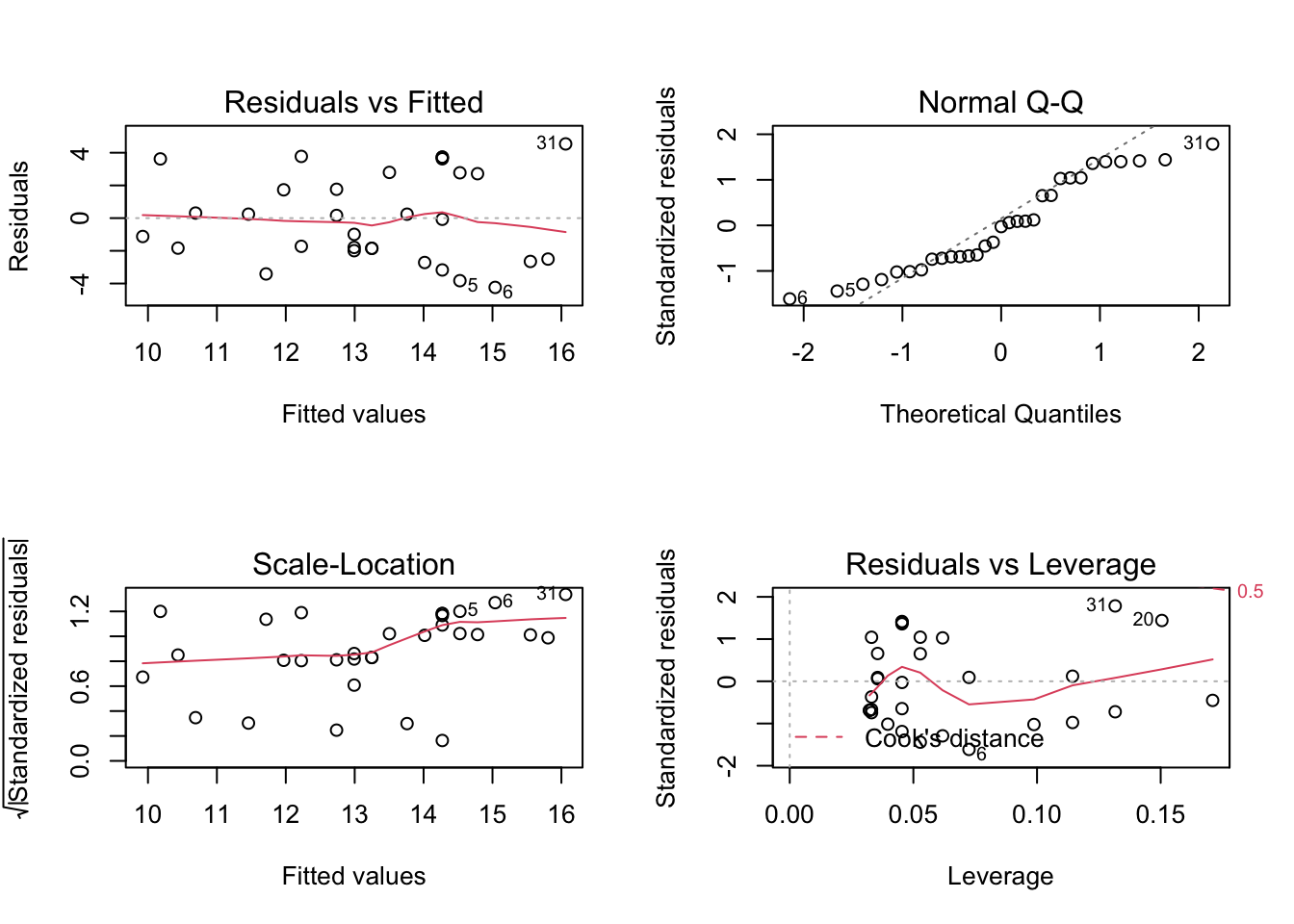
This generates four plots: 1) Residuals vs Fitted - checks linear relationship assumption of linear regression. A linear relationship will demonstrate a horizontal red line here. Deviations from a horizontal line suggest nonlinearity and that a different approach may be necessary.
Normal Q-Q - checks whether or not the residuals (the difference between the observed and predicted values) from the model are normally distributed. The best fit models points fall along the dashed line on the plot. Deviation from this line suggests that a different analytical approach may be required.
Scale-Location - checks the homoscedasticity of the model. A horizontal red line with points equally spread out indicates a well-fit model. A non-horizontal line or points that cluster together suggests that your data are not homoscedastic.
Residuals vs Leverage - helps to identify outlier or extreme values that may disproportionately affect the model’s results. Their inclusion or exclusion from the analysis may affect the results of the analysis. Note that the top three most extreme values are identified with numbers next to the points in all four plots.
5.7.7 Tree Girth and Height Example
In our example looking at the relationship between tree girth and height, we can first check linearity of the data by looking at the Residuals vs Fitted plot. Here, we do see a red line that is approximately horizontal, which is what we’re looking for. Additionally, we’re looking to be sure there is no clear pattern in the points on the plot - we want them to be random on this plot. Clustering of a bunch of points together or trends in this plot would indicate that the data do not have a linear relationship.
To check for homogeneity of the variance, we can turn to the Scale-Location plot. Here, we’re again looking for a horizontal red line. In this dataset, there’s a suggestion that there is some heteroscedasticity, with points not being equally far from the regression line across the observations.
While not discussed explicitly here in this lesson, we will note that when the data are nonlinear or the variances are not homogeneous (are not homoscedastic), transformations of the data can often be applied and then linear regression can be used.
QQ Plots are very helpful in assessing the normality of residuals. Normally distributed residuals will fall along the grey dotted line. Deviation from the line suggests the residuals are not normally distributed. Here, in this example, we do not see the points fall perfectly along the dotted line, suggesting that our residuals are not normally distributed.
A histogram (or densityplot) of the residuals can also be used for this portion of regression diagnostics. Here, we’re looking for a Normal distribution of the residuals.
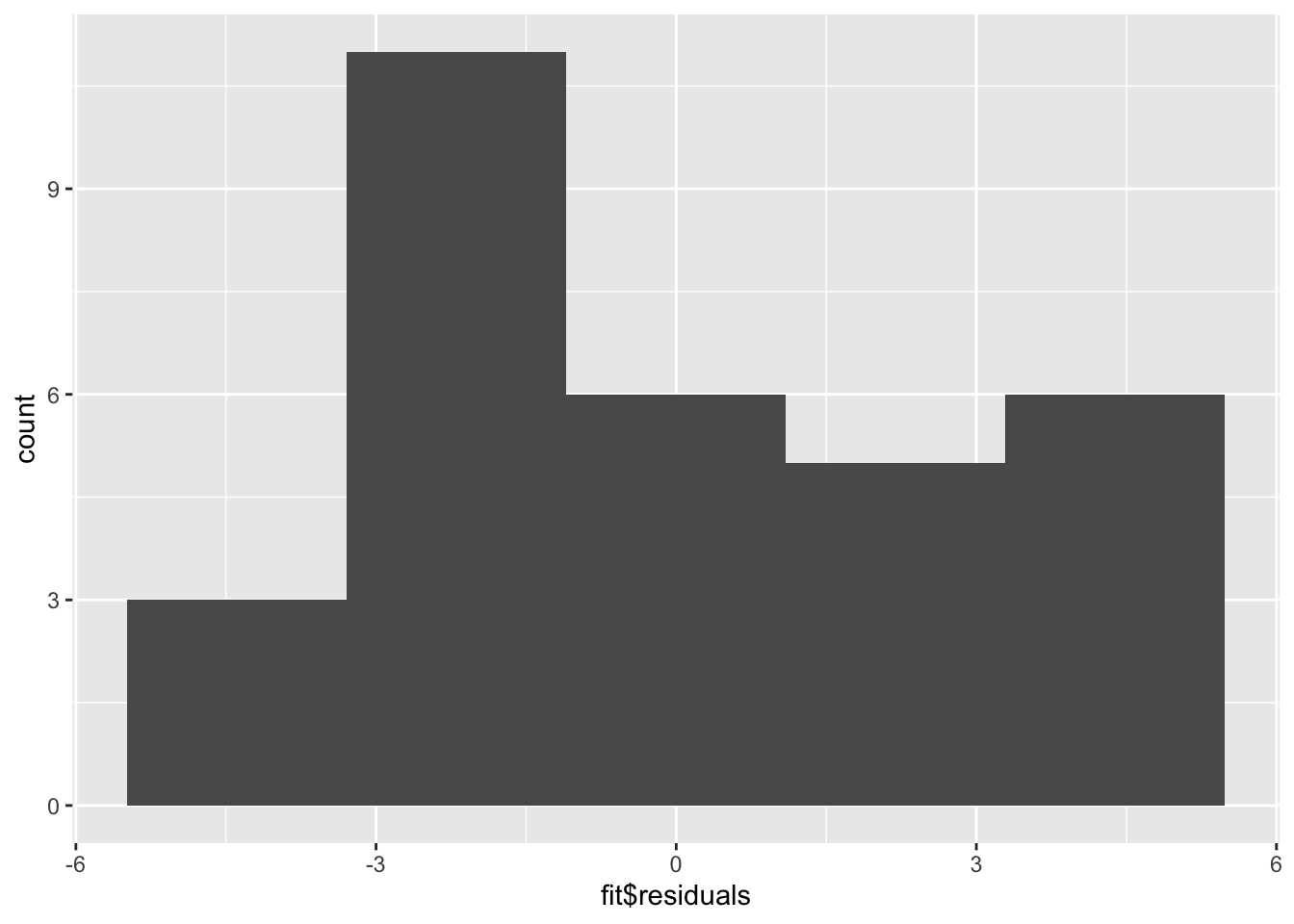
The QQ Plot and the histogram of the residuals will always give the same answer. Here, we see that with our limited sample size, we have fairly good Normally distributed residuals; and, the points do not fall wildly far from the dotted line.
Finally, whether or not outliers (extreme observations) are driving our results can be assessed by looking at the Residuals vs Leverage plot.
Generally speaking, standardized residuals greater than 3 or less than -3 are to be considered as outliers. Here, we do not see any values in that range (by looking at the y-axis), suggesting that there are no extreme outliers driving the results of our analysis.
5.7.8 Interpreting the Model
While the relationship in our example appears to be linear, does not indicate being driven by outliers, is approximately homoscedastic and has residuals that are not perfectly Normally distributed, but fall close to the line in the QQ plot, we can discuss how to interpret the results of the model.
The summary() function summarizes the model as well as the output of the model. We can see the values we’re interested in in this summary, including the beta estimate, the standard error (SE), and the p-value.
Specifically, from the beta estimate, which is positive, we confirm that the relationship is positive (which we could also tell from the scatterplot). We can also interpret this beta estimate explicitly.
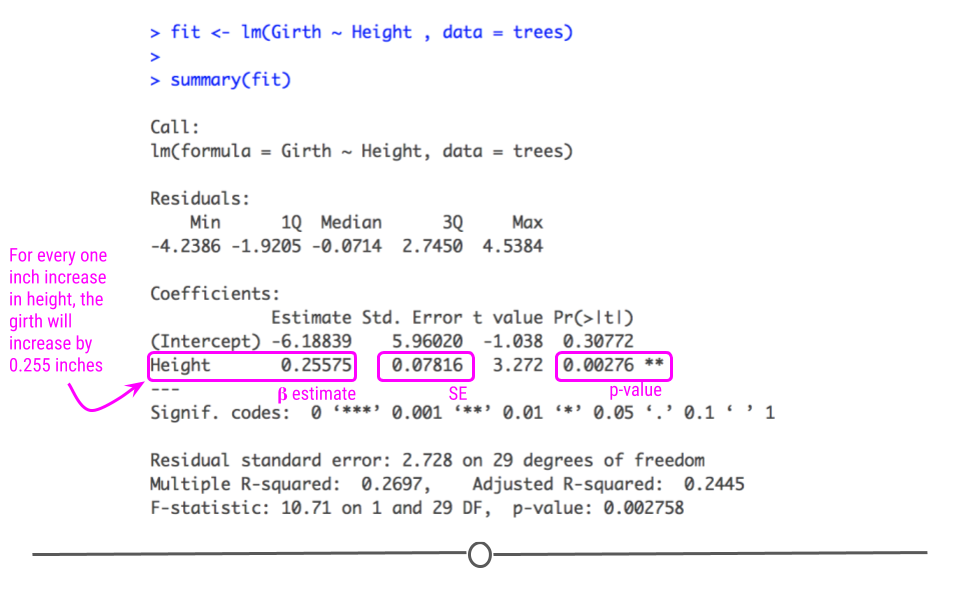
The beta estimate (also known as the beta coefficient or coefficient in the Estimate column) is the amount the dependent variable will change given a one unit increase in the independent variable. In the case of the trees, a beta estimate of 1.054, says that for every inch a tree’s girth increases, its height will increase by 1.054 inches. Thus, we not only know that there’s a positive relationship between the two variables, but we know by precisely how much one variable will change given a single unit increase in the other variable. Note that we’re looking at the second row in the output here, where the row label is “Girth”. This row quantifies the relationship between our two variables. The first row quantifies the intercept, or where the line crosses the y-axis.
The standard error and p-value are also included in this output. Error is typically something we want to minimize (in life and statistical analyses), so the smaller the error, the more confident we are in the association between these two variables.
The beta estimate and the standard error are then both considered in the calculation of the p-value (found in the column Pr[>|t|]). The smaller this value is, the more confident we are that this relationship is not due to random chance alone.
5.7.9 Variance Explained
Additionally, the strength of this relationship is summarized using the adjusted R-squared metric. This metric explains how much of the variance this regression line explains. The more variance explained, the closer this value is to 1. And, the closer this value is to 1, the closer the points in your dataset fall to the line of best fit. The further they are from the line, the closer this value will be to zero.
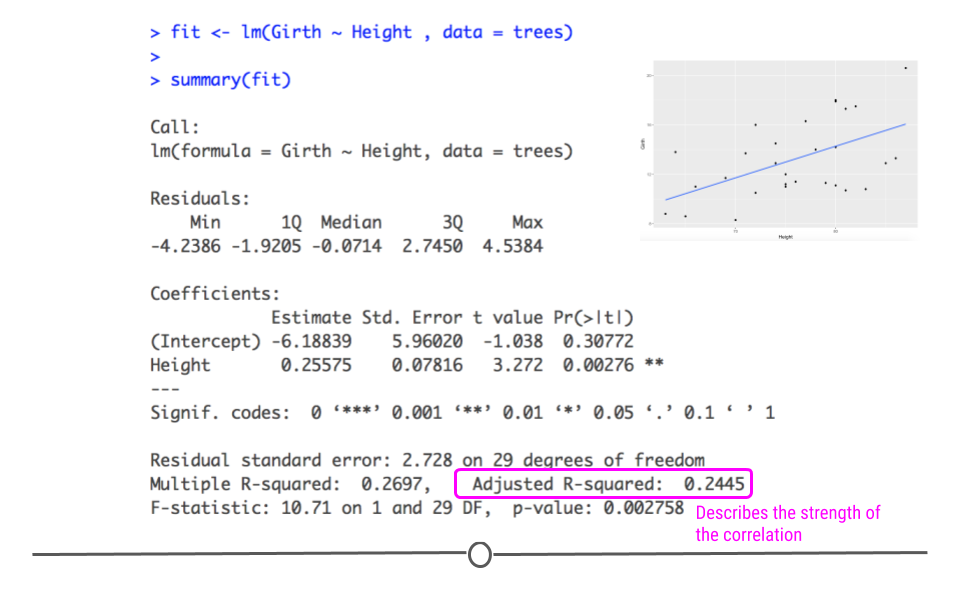
As we saw in the scatterplot, the data are not right up against the regression line, so a value of 0.2445 seems reasonable, suggesting that this model (this regression line) explains 24.45% of the variance in the data.
5.7.10 Using broom
Finally, while the summary() output are visually helpful, if you want to get any of the numbers out from that model, it’s not always straightforward. Thankfully, there is a package to help you with that! The tidy() function from the broom package helps take the summary output from a statistical model and organize it into a tabular output.
## # A tibble: 2 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 62.0 4.38 14.2 1.49e-14
## 2 Girth 1.05 0.322 3.27 2.76e- 3Note that the values haven’t changed. They’re just organized into an easy-to-use table. It’s helpful to keep in mind that this function and package exist as you work with statistical models.
Finally, it’s important to always keep in mind that the interpretation of your inferential data analysis is incredibly important. When you use linear regression to test for association, you’re looking at the relationship between the two variables. While girth can be used to infer a tree’s height, this is just a correlation. It does not mean that an increase in girth causes the tree to grow more. Associations are correlations. They are not causal.
For now, however, in response to our question, can we infer a black cherry tree’s height from its girth, the answer is yes. We would expect, on average, a tree’s height to increase 1.054 inches for every one inch increase in girth.
5.7.11 Correlation Is Not Causation
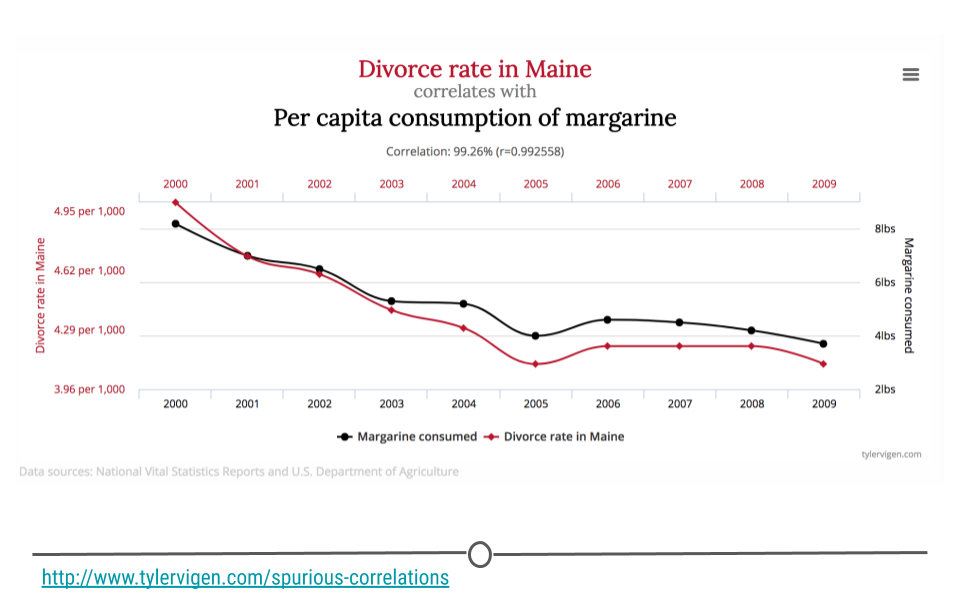
You’ve likely heard someone say before that “correlation is not causation,” and it’s true! In fact, there are entire websites dedicated to this concept. Let’s make sure we know exactly what that means before moving on. In the plot you see here, as the divorce rate in Maine decreases, so does per capita consumption of margarine. These two lines are clearly correlated; however, there isn’t really a strong (or any) argument to say that one caused the other. Thus, just because you see two things with the same trend does not mean that one caused the other. These are simply spurious correlations – things that trend together by chance. Always keep this in mind when you’re doing inferential analysis, and be sure that you never draw causal claims when all you have are associations.
In fact, one could argue that the only time you can make causal claims are when you have carried out a randomized experiment. Randomized experiments are studies that are designed and carried out by randomly assigning certain subjects to one treatment and the rest of the individuals to another treatment. The treatment is then applied and the results are then analyzed. In the case of a randomized experiment, causal claims can start to be made. Short of this, however, be careful with the language you choose and do not overstate your findings.
5.7.12 Confounding
Confounding in something to watch out for in any analysis you’re doing that looks at the relationship between two more more variables. So…what is confounding?
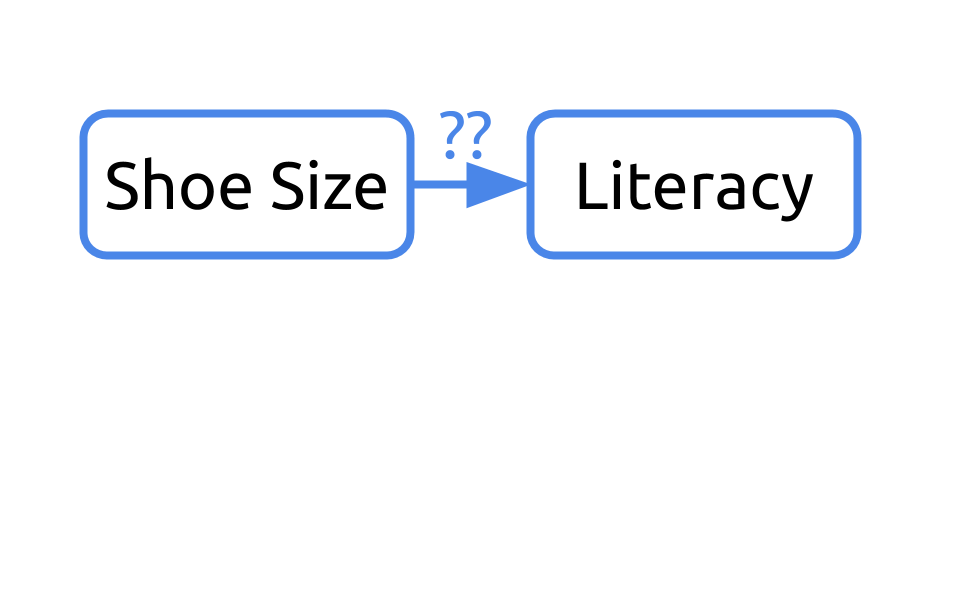
Let’s consider an example. What if we were interested in understanding the relationship between shoe size and literacy. To do so, we took a look at this small sample of two humans, one who wears small shoes and is not literate and one adult who wears big shoes and is literate.

If we were to diagram this question, we may ask “Can we infer literacy rates from shoe size?”
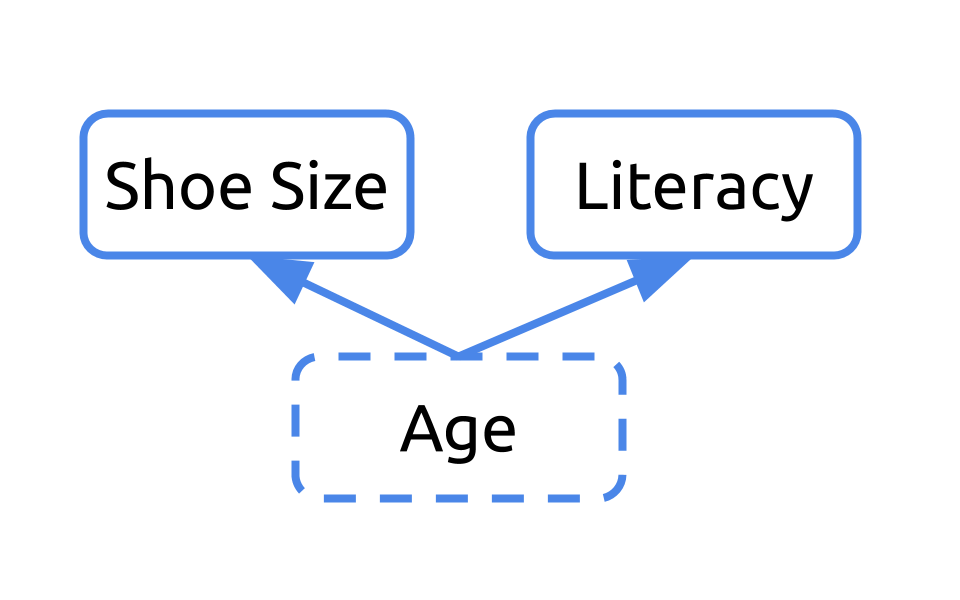
If we return to our sample, it’d be important to note that one of the humans is a young child and the other is an adult.

Our initial diagram failed to take into consideration the fact that these humans differed in their age. Age affects their shoe size and their literacy rates. In this example, age is a confounder.
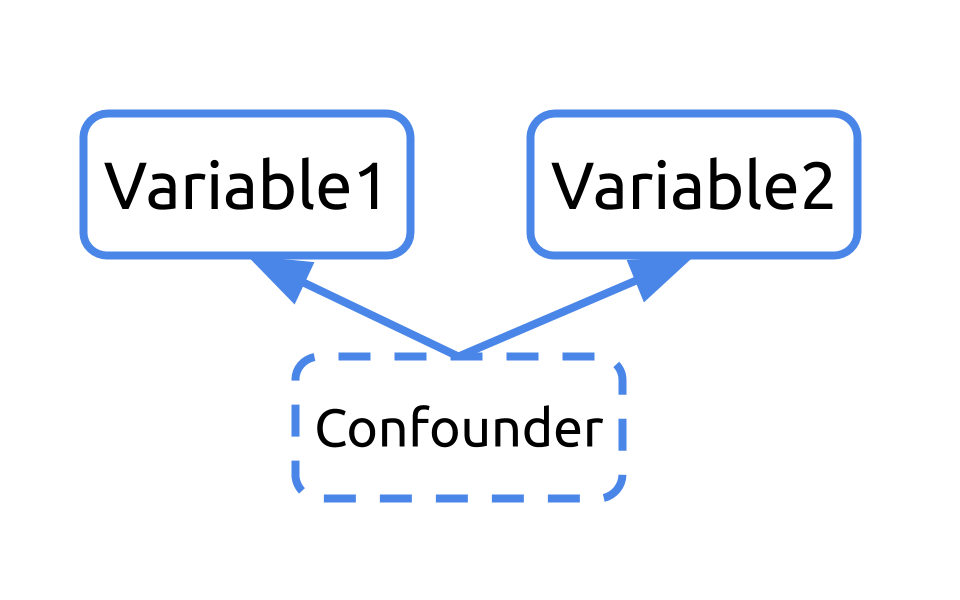
Any time you have a variable that affects both your dependent and independent variables, it’s a confounder. Ignoring confounders is not appropriate when analyzing data. In fact, in this example, you would have concluded that people who wear small shoes have lower literacy rates than those who wear large shoes. That would have been incorrect. In fact, that analysis was confounded by age. Failing to correct for confounding has led to misreporting in the media and retraction of scientific studies. You don’t want to be in that situation. So, always consider and check for confounding among the variables in your dataset.
5.8 Multiple Linear Regression
There are ways to effectively handle confounders within an analysis. Confounders can be included in your linear regression model. When included, the analysis takes into account the fact that these variables are confounders and carries out the regression, removing the effect of the confounding variable from the estimates calculated for the variable of interest.
This type of analysis is known as multiple linear regression, and the general format is: lm(dependent_variable ~ independent_variable + confounder , data = dataset).
As a simple example, let’s return to the mtcars dataset, which we’ve worked with before. In this dataset, we have data from 32 automobiles, including their weight (wt), miles per gallon (mpg), and Engine (vs, where 0 is “V-shaped” and 1 is “straight”).
Suppose we were interested in inferring the mpg a car would get based on its weight. We’d first look at the relationship graphically:
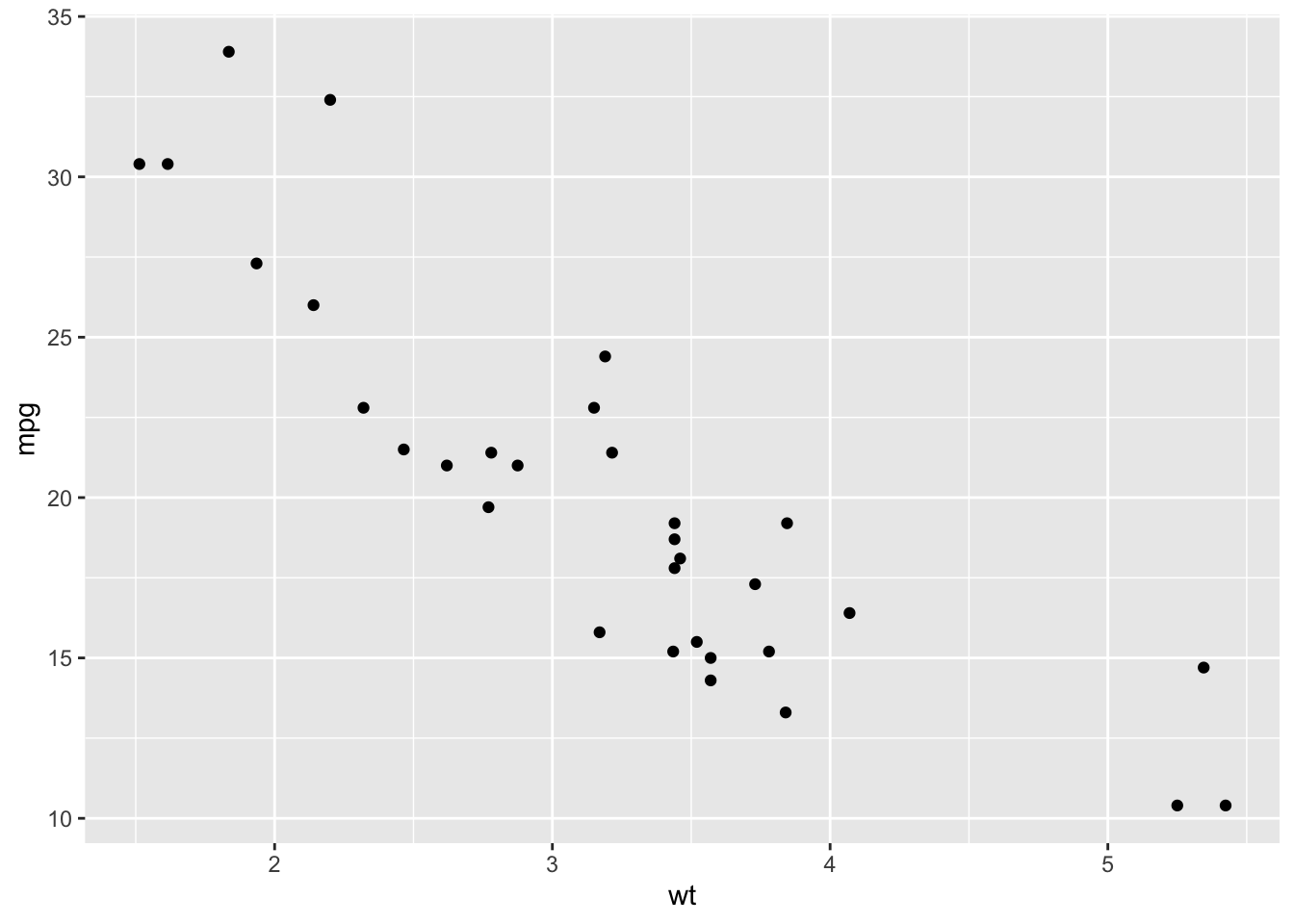
From the scatterplot, the relationship looks approximately linear and the variance looks constant. Thus, we could model this using linear regression:
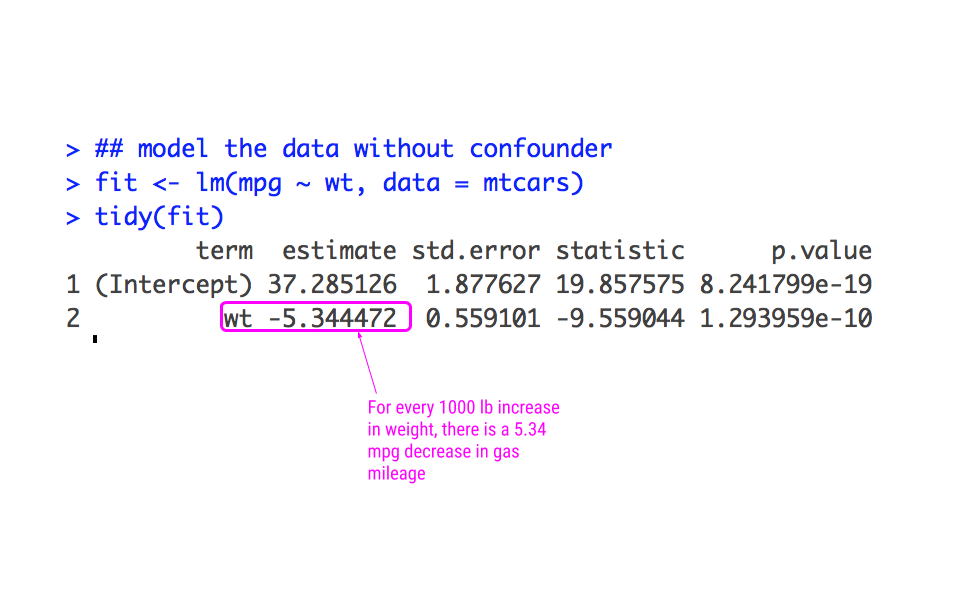
From this analysis, we would infer that for every increase 1000 lbs more a car weighs, it gets 5.34 miles less per gallon.
However, we know that the weight of a car doesn’t necessarily tell the whole story. The type of engine in the car likely affects both the weight of the car and the miles per gallon the car gets. Graphically, we could see if this were the case by looking at these scatterplots:
## look at the difference in relationship
## between Engine types
ggplot(mtcars, aes(wt, mpg)) +
geom_point() +
facet_wrap(~vs)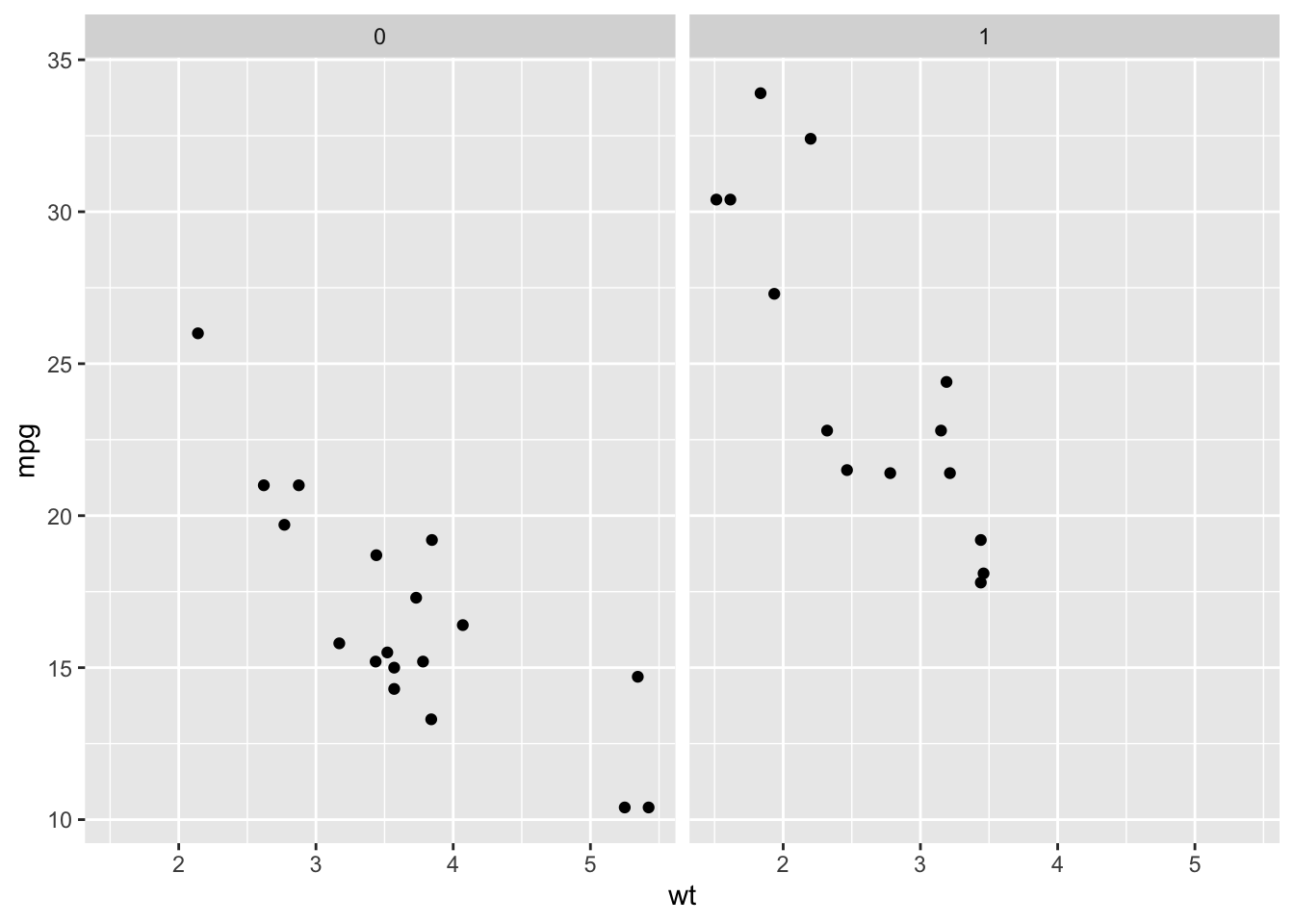
From this plot, we can see that V-shaped engines (vs= 0), tend to be heavier and get fewer miles per gallon while straight engines (vs = 1) tend to weigh less and get more miles per gallon. Importantly, however, we see that a car that weighs 3000 points (wt = 3) and has a V-Shaped engine (vs = 0) gets fewer miles per gallon than a car of the same weight with a straight engine (vs = 1), suggesting that simply modeling a linear relationship between weight and mpg is not appropriate.
Let’s then model the data, taking this confounding into account:
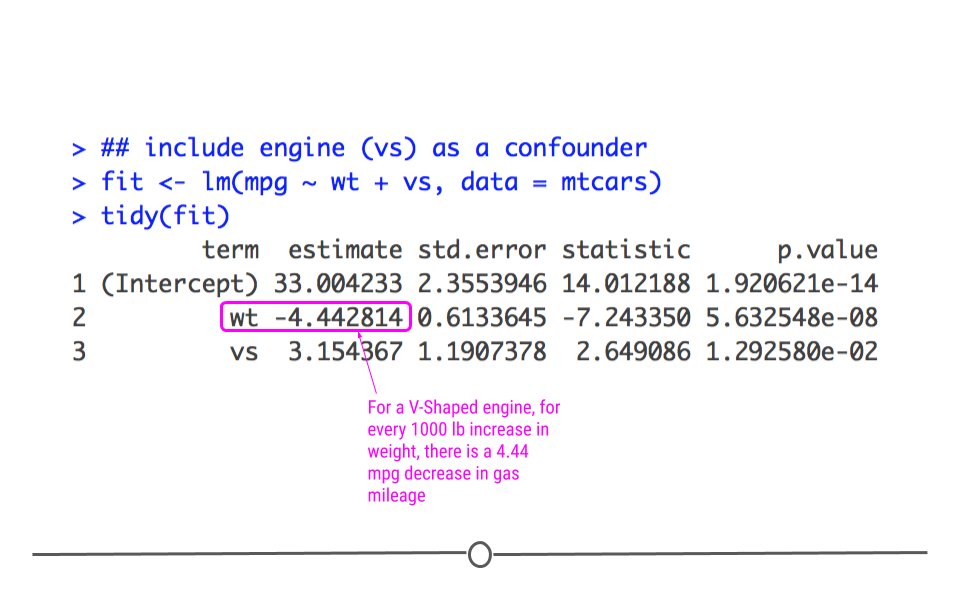
Here, we get a more accurate picture of what’s going on. Interpreting multiple regression models is slightly more complicated since there are more variables; however, we’ll practice how to do so now.
The best way to interpret the coefficients in a multiple linear regression model is to focus on a single variable of interest and hold all other variables constant. For instance, we’ll focus on weight (wt) while holding (vs) constant to interpret. This means that for a V-shaped engine, we expect to see a 4.44 miles per gallon decrease for every 1000 lb increase in weight.
We can similarly interpret the coefficients by focusing on the engines (vs). For example, for two cars that weigh the same, we’d expect a straight engine (vs = 1) to get 3.15 more miles per gallon than a V-Shaped engine (vs= 0).
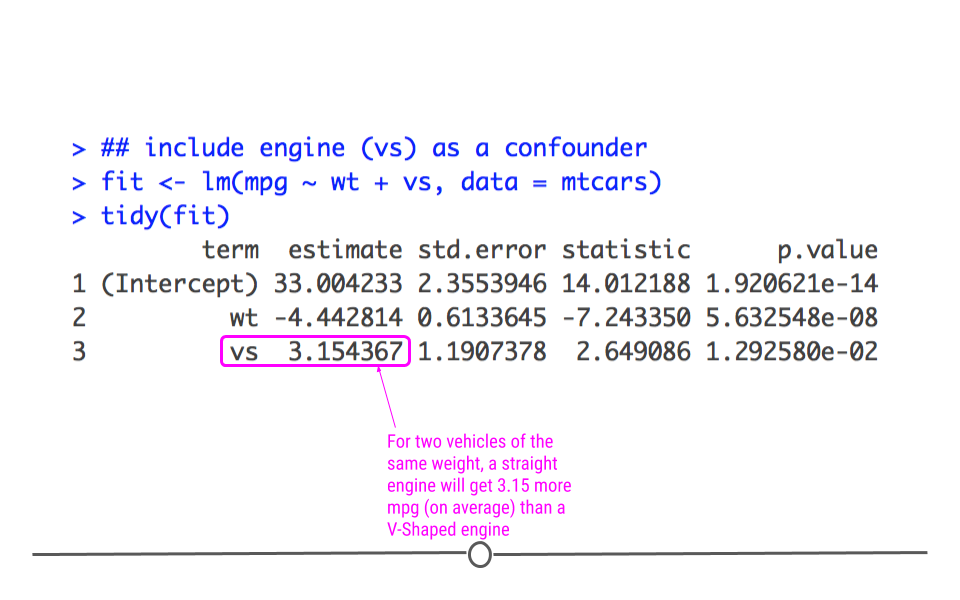
Finally, we’ll point out that the p-value for wt decreased in this model relative to the model where we didn’t account for confounding. This is because the model was not initially taking into account the engine difference. Frequently when confounders are accounted for, the p-value will increase, and that’s OK. What’s important is that the data are most appropriately modeled.
5.9 Beyond Linear Regression
While we’ve focused on linear regression in this lesson on inference, linear regression isn’t the only analytical approach out there. However, it is arguably the most commonly used. And, beyond that, there are many statistical tests and approaches that are slight variations on linear regression, so having a solid foundation and understanding of linear regression makes understanding these other tests and approaches much simpler.
For example, what if you didn’t want to measure the linear relationship between two variables, but instead wanted to know whether or not the average observed is different from expectation?
5.9.1 Mean Different From Expectation?
To answer a question like this, let’s consider the case where you’re interested in analyzing data about a single numeric variable. If you were doing descriptive statistics on this dataset, you’d likely calculate the mean for that variable. But, what if, in addition to knowing the mean, you wanted to know if the values in that variable were all within the bounds of normal variation. You could calculate that using inferential data analysis. You could use the data you have to infer whether or not the data are within the expected bounds.
For example, let’s say you had a dataset that included the number of ounces actually included in 100 cans of a soft drink. You’d expect that each can have exactly 12 oz of liquid; however, there is some variation in the process. So, let’s test whether or not you’re consistently getting shorted on the amount of liquid in your can.
In fact, let’s go ahead and generate the dataset ourselves!
## generate the dataset
set.seed(34)
soda_ounces <- rnorm(100, mean = 12, sd = 0.04)
head(soda_ounces)## [1] 11.99444 12.04799 11.97009 11.97699 11.98946 11.98178In this code, we’re specifying that we want to take a random draw of 100 different values (representing our 100 cans of soft drink), where the mean is 12 (representing the 12 ounces of soda expected to be within each can), and allowing for some variation (we’ve set the standard deviation to be 0.04).
We can see that the values are approximately, but not always exactly equal to the expected 12 ounces.
5.9.2 Testing Mean Difference From Expectation in R
To make an inference as to whether or not we’re consistently getting shorted, we’re going to use this sample of 100 cans. Note that we’re using this sample of cans to infer something about all cans of this soft drink, since we aren’t able to measure the number of ounces in all cans of the soft drink generated.
To carry out this statistical test, we’ll use a t-test.
Wait, we haven’t talked about that statistical test yet. So, let’s take a quick detour to discuss t-tests and how they relate to linear regression.
R has a built in t-test function: t.test().
However, I mentioned earlier that many statistical tests are simply extension of linear regression. In fact, a t-test is simply a linear model where we specify to only fit an intercept (where the data crosses the y-axis). In other words, this specifies to calculate the mean…which is exactly what we’re looking to do here with our t-test! We’ll compare these two approaches below.
However, before we can do so, we have to ensure that the data follow a normal distribution, since this is the primary assumption of the t-test.
library(ggplot2)
## check for normality
ggplot(as.data.frame(soda_ounces))+
geom_histogram(aes(soda_ounces), bins = 10)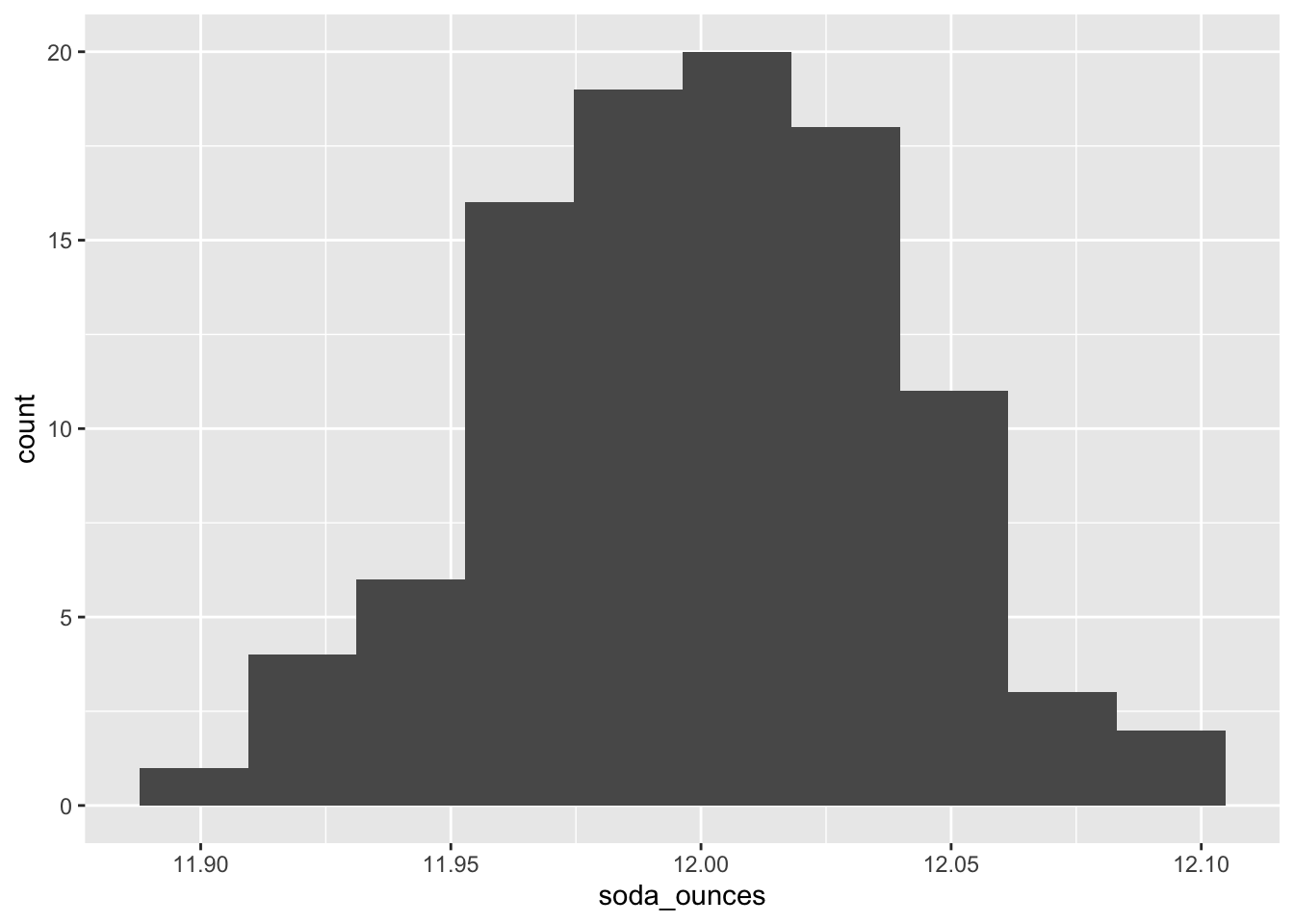
Here, we see that the data are approximately normally distributed.
A t-test will check whether the observed ounces differs from the expected mean (12 oz). As mentioned above, to run a t-test in R, most people use the built-in function: t.test().
##
## One Sample t-test
##
## data: soda_ounces
## t = -0.074999, df = 99, p-value = 0.9404
## alternative hypothesis: true mean is not equal to 12
## 95 percent confidence interval:
## 11.99187 12.00754
## sample estimates:
## mean of x
## 11.9997In the output from this function, we’ll focus on the 95 percent confidence interval. Confidence Intervals provide the range of values likely to contain the unknown population parameter. Here, the population parameter we’re interested in is the mean. Thus, the 95% Confidence Intervals provides us the range where, upon repeated sampling, the calculated mean would fall 95 percent of the time. More specifically, if the 95 percent confidence interval contains the expected mean (12 oz), then we can be confident that the company is not shorting us on the amount of liquid they’re putting into each can.
Here, since 12 is between 11.99187 and 12.00754, we can see that the amounts in the 100 sampled cans are within the expected variation. We could infer from this sample that the population of all cans of this soft drink are likely to have an appropriate amount of liquid in the cans.
However, as mentioned previously, t-tests are an extension of linear regression. We could also look to see whether or not the cans had the expected average of 12 oz in the data collected using lm().
# from linear regression
regression_output <- lm(soda_ounces ~ 1)
# calculate confidence interval
confint(regression_output)
Note that the confidence interval is the exact same here using lm() as above when we used t.test()! We bring this up not to confuse you, but to guide you away from trying to memorize each individual statistical test and instead understand how they relate to one another.
5.10 More Statistical Tests
Now that you’ve seen how to measure the linear relationship between variables (linear regression) and how to determine if the mean of a dataset differs from expectation (t-test), it’s important to know that you can ask lots of different questions using extensions of linear regression. These have been nicely summarized by Jonas Kristoffer Lindelov in is blog post Common statistical tests are linear models (or: how to teach stats).
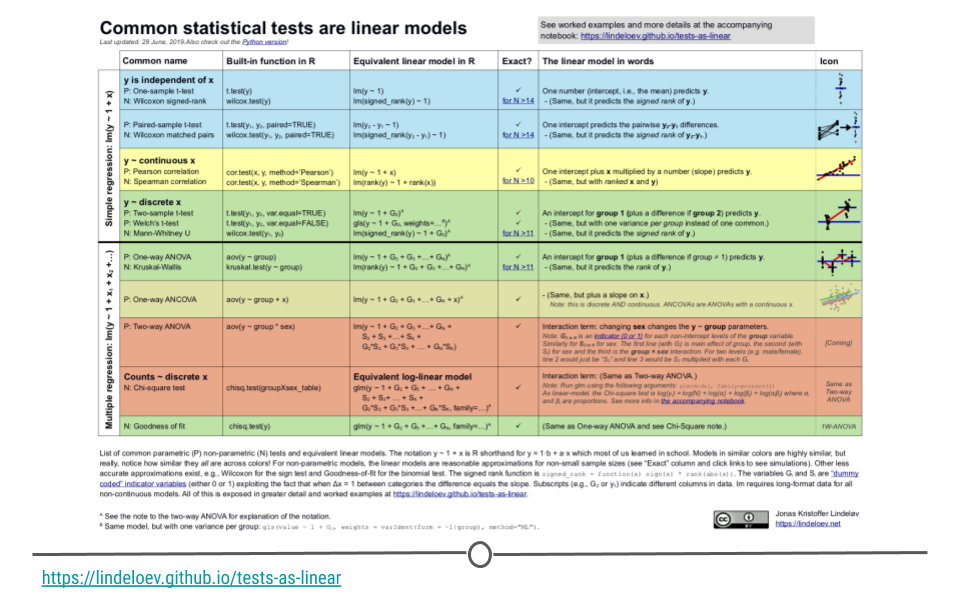
5.11 Hypothesis Testing
You may have noticed in the previous sections that we were asking a question about the data. We did so by testing if a particular answer to the question was true.
For example:
In the cherry tree analysis we asked “Can we infer the height of a tree given its girth?”
We expected that we could. Thus we had a statement that “tree height can be inferred by it’s girth or can be predicted by girth”In the car mileage analysis we asked “Can we infer the miles the car can go per gallon of gasoline based on the car weight?”
We expected that we could. Thus we had a statement that “car mileage can be inferred by car weight”
We took this further and asked “Can we infer the miles the car can go per gallon of gasoline based on the car weight and care engine type?”
We again expected that it did. Thus we had a statement that ” car mileage can be inferred by weight and engine type”
- In the soda can analysis we asked “Do soda cans really have 12 ounces of fluid”. We expected that often do. Thus we had a statement that “soda cans typically have 12 ounces, the mean amount is 12”.
A common problem in many data science problem involves developing evidence for or against certain testable statements like these statements above. These testable statements are called hypotheses. Typically, the way these problems are structured is that a statement is made about the world (the hypothesis) and then the data are used (usually in the form of a summary statistic) to support or reject that statement.
Recall that we defined a p-value as “the probability of getting the observed results (or results more extreme) by chance alone.” Often p-values are used to determine if one should accept or reject that statement.
Typically a p-value of 0.05 is used as the threshold, however remember that it is best to report more than just the p-value, but also estimates and standard errors among other statistics. Different statistical tests allow for testing different hypotheses.
5.11.1 TheInfer Package
The infer package simplifies inference analyses. Users can quickly calculate a variety of statistics and perform statistical tests including those that require resampling, permutation, or simulations using data that is in tidy format.
In fact users can even perform analyses based on specified hypotheses with the hypothesize() function.
We will perform the same analysis about soda cans that we just did with this package to illustrate how to use it.
Recall that we wanted to know if the observed ounces of soda can differs from the expected mean of 12 ounces. Also recall that we had measurements for 100 soda cans (we made up this data). We had a testable statement or hypothesis that “soda cans typically have 12 ounces, the mean amount is 12” and we wanted to know if this was true.
This type of hypothesis is called a null hypothesis because it is a statement that expects no difference or change. The alternative hypothesis is the complement statement. It would be that the mean is not 12.
OK, so now we will use the infer package to test if our null hypothesis is true.
First, we need to get our data into a tidy format. Thus we will use the as_tibble() function of the tidyr package.
## # A tibble: 100 × 1
## value
## <dbl>
## 1 12.0
## 2 12.0
## 3 12.0
## 4 12.0
## 5 12.0
## 6 12.0
## 7 12.0
## 8 12.0
## 9 12.0
## 10 12.0
## # ℹ 90 more rowsNow we will use the specify() function of the infer package to indicate that the value variable is our response variable that will be used in our hypothesis. This is as you might expect more important when we have multiple variables in our data. Then we can specify our null hypothesis with the hypothesize() function.
There are two options for the null argument of this function:
1) point - this option should be used when there is one variable in the hypothesis, such as “the mean of this data x”.
2) independence - this option should be used when there are two populations, such as ” the means of these two groups identical” or “this variable influences this other variable”.
Then if the point option is used, there are several additional arguments regarding what is being tested about that one variable. One can test a particular mu for mean, med for median, sigma for standard deviation, or p for the proportion of successes (for a categorical variable).
Our hypothesis was “the mean amount of soda ounces is 12” thus we will use the point option for our null argument and we will specify a mean with the mu argument as 12.
The major benefit of this package, besides allowing the user to think about the statistical analysis more than the programming required, is that the user can easily implement iterative methods like resampling.
What do we mean by this?
Resampling is a method where a random samples are drawn from the original data to create a dataset of the same size as the original data (but with some samples repeated) and this is done repetitively over and over. This process is called Bootstrapping. This provides more information about the confidence in our estimations from our sample about the true population that we are trying to investigate, as it gives us more of a sense of the range of values for statistics like mean and median might vary using other samples.
To perform resampling, users can use the generate() function with the type argument set to "bootsrap" and use the rep argument to specify how many bootstrap resamples to generate.
The calculate() function then allows for many different statistics to be calculated including:
mean
median
sum
sdfor standard deviation
propfor proportion for categorical variables
count
diff in means
diff in medians
diff in props
Chisq
F
slope
correlation
t
z
ratio of props
odds ratio
Finally, the get_confidence_interval() as you might guess calculates a confidence interval.
Now we will use these functions on our data.
library(infer)
set.seed(342)
CI <-soda_ounces %>%
specify(response = value) %>%
hypothesize(null = "point", mu = 12) %>%
generate(rep = 1000, type = "bootstrap") %>%
calculate(stat = "mean") %>%
get_confidence_interval()## Using `level = 0.95` to compute confidence interval.## # A tibble: 1 × 2
## lower_ci upper_ci
## <dbl> <dbl>
## 1 12.0 12.0We can see that our confidence interval is very similar but slightly different from the results we obtained using the t.test() function and the lm() function. This is because we used a different method to calculate the confidence interval based on the bootstrap samples. Furthermore, the results will vary every time the code is run because the bootstrap samples are randomly created each time (unless you set a seed with set.seed).
We can also make a visualization of the null distribution of the bootstrap samples using the visualize() function.
set.seed(342)
bootstrap_means <-soda_ounces %>%
specify(response = value) %>%
hypothesize(null = "point", mu = 12) %>%
generate(rep = 1000, type = "bootstrap") %>%
calculate(stat = "mean")
bootstrap_means %>%
visualize()
5.12 Prediction Modeling
While the goal in inference is to learn something about the population, when we’re talking about prediction, the focus is on the individual. The goal of predictive analysis and machine learning approaches is to train a model using data to make predictions about an individual.
In other words, the goal of predictive analysis is to use data you have now to make predictions about future data.
We spend a lot of time trying to predict things in daily life- the upcoming weather, the outcomes of sports events, and the outcomes of elections. Using historical polling data and trends and current polling, Nate Silver’s FiveThirtyEight builds models to predict the outcomes and the next US Presidential vote - and has been fairly accurate at doing so! FiveThirtyEight’s models accurately predicted the 2008 and 2012 elections and was widely considered an outlier in the 2016 US elections, as it was one of the few models to suggest Donald Trump had a chance of winning.
Predicting the outcome of elections is a key example of predictive analysis, where historical data (data they have now) are used to predict something about the future.
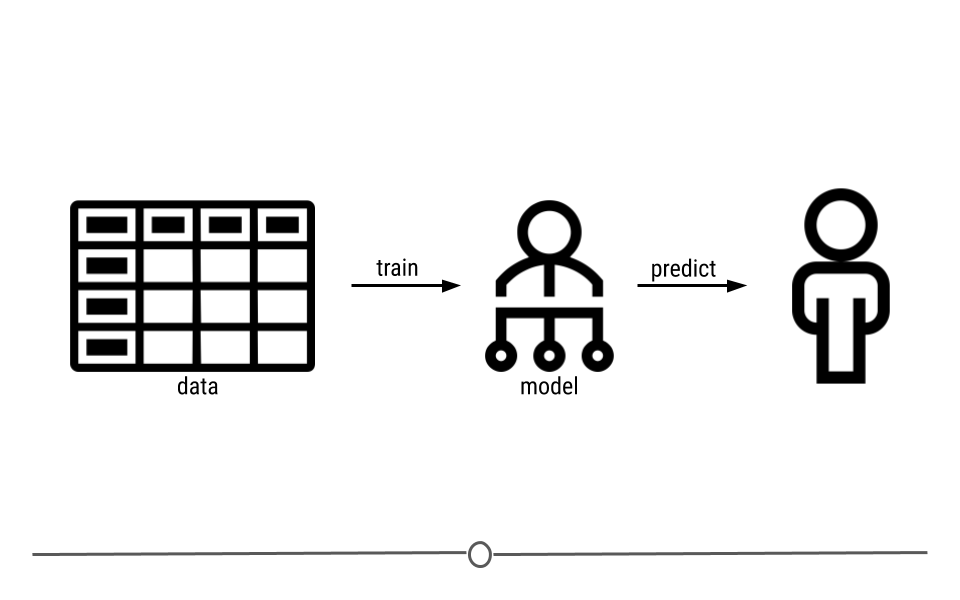
5.12.1 What is Machine Learning?
So far we’ve been discussing predictive analysis. But, you may have heard people on the news or in daily life talking about “machine learning.” The goal of machine learning in prediction is to build models (often referred to as algorithms) from the patterns in data that can be used for predictions in the future. Here, machine learning refers to using the relationships within a dataset to build a model that can be used for prediction.
That said, there is without a doubt an entire field of individuals dedicating themselves to machine learning. This lesson will just touch on the very basics within the field.
5.12.2 Machine Learning Steps
In order to make predictions for the future using data you have now, there are four general steps:
- Data Splitting - what data are you going to use to train your model? To tune your model? To test your model?
- Variable Selection - what variable(s) from the data you have now are you going to use to predict future outcomes?
- Model Selection - How are you going to model the data?
- Accuracy Assessment - How are you going to assess accuracy of your predictions?
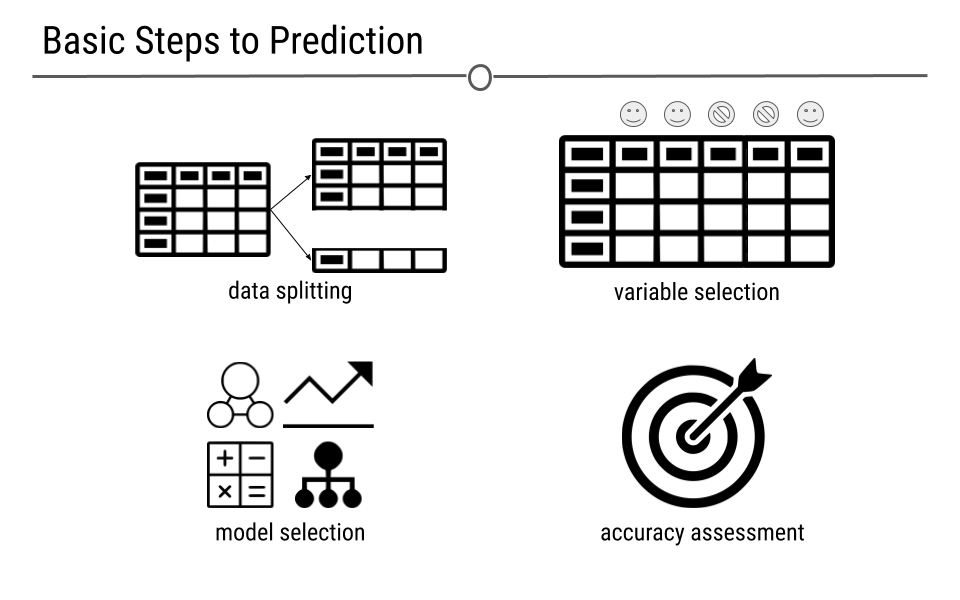
5.12.3 Data Splitting
For predictive analysis (or machine learning), you need data on which to train your model. These are the set of observations and corresponding variables that you’re going to use to build your predictive model. But, a predictive model is only worth something if in can predict accurately in a future dataset. Thus, often, in machine learning there are three datasets used to build a predictive model. The names for these datasets vary to some degree.
5.12.4 Train, Test, Validate
Many people use train, validate, and test. However, almost as many people use train, test, and validate, as evidenced by this Twitter poll:
In this lesson, we’ve decided to go with the terminology that fits the tidymodels terminology: train, test, validate.
5.12.5 Train
Training data are the data we described above. It is the data used to build your predictive model. These data are referred to as your training set.
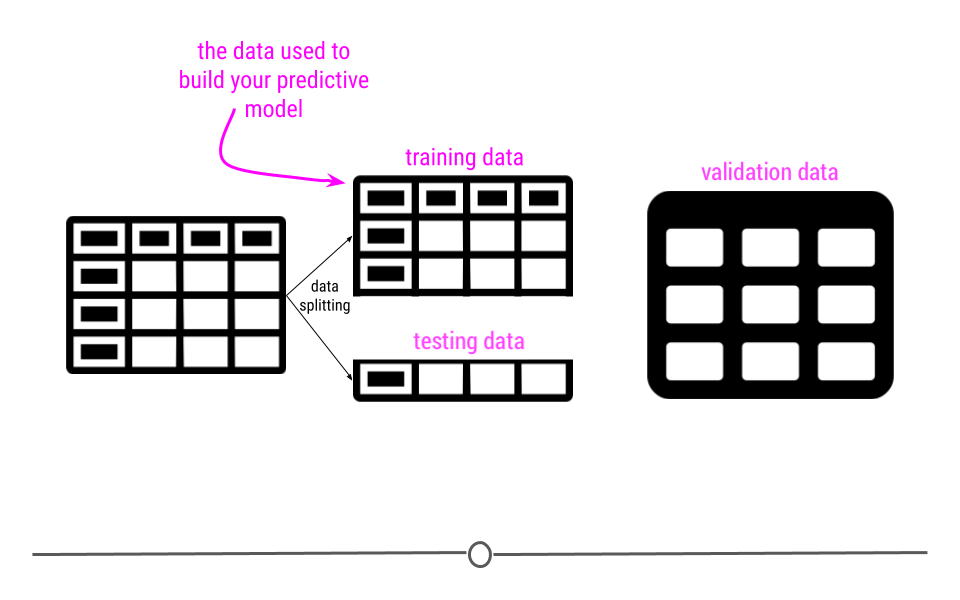
5.12.6 Test
Before getting started, your original dataset is often split. Some (often 70%-75%) of the observations in your dataset are used to train the model, while 25%-30% are held out.
These hold-out samples are used to see whether or not your predictive model accurately makes predictions in the set of samples not used to train the model.
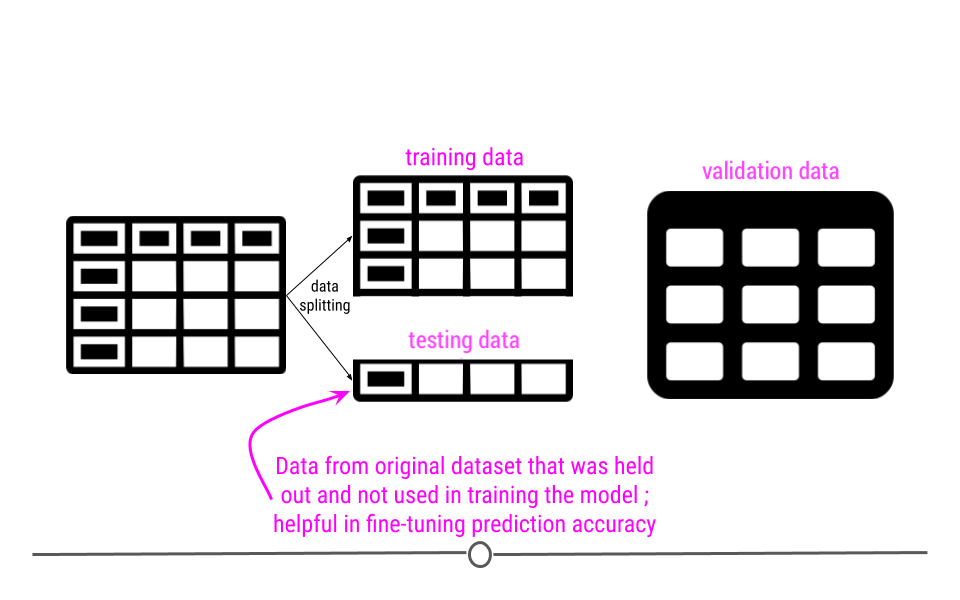
5.12.7 Validate
Finally, an independent dataset – one that is not from the same experiment or source as the data used to train and test your model are used to see whether or not your predictive model makes accurate predictions in a completely new dataset. Predictive models that can be generalized to and make accurate predictions in new datasets are the best predictive models.
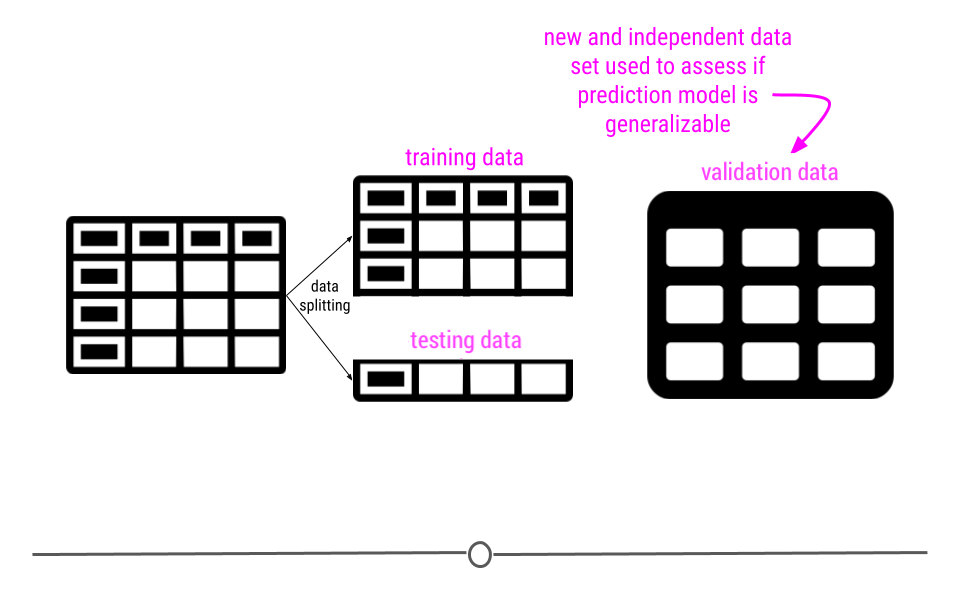
Ultimately, we want to create a model that will perform well with any new data that we try to use. In other words we want the model to be generalizable so we can use it again to make predictions with new data. We don’t want the model to only work well with the data that we used to train the model (this is called overfitting). Using a validation set helps us to assess how well our model might work with new data in the future. This is part of what we call out-of-sample testing, as we evaluate the performance of the model on independent data that was not a part of the sample used to train the model.
5.12.8 Variable Selection
For predictive analysis to be worth anything, you have to be able to predict an outcome accurately with the data you have on hand.
If all the data you have on hand are the heights of elephants in Asia, you’re likely not going to be able to predict the outcome of the next US election. Thus, the variables in the data you have on hand have to be related to the outcome you’re interested in predicting in some way (which is not the case for the heights of elephants and US elections).
Instead, to predict US elections, you’d likely want some data on outcomes of previous elections, maybe some demographic information about the voting districts, and maybe some information about the ages or professions of the people voting. All of these variables are likely to be helpful in predicting the outcome in a future election, but which ones are actually predictive? All of them? Some of them? The process of deciding which variables to use for prediction is called variable selection.
You ideally want to include the fewest variables in your model as possible. Only having a few variables in your model avoids you having to collect a ton of data or build a really complicated model. But, you want the model to be as accurate as possible in making predictions. Thus, there’s always a balance between minimizing the variables included (to only include the most predictive variables!) and maximizing your model’s predictive accuracy. In other words, like in inferential analysis, your ability to make accurate predictions is dependent on whether or not you have measurements on the right variables. If you aren’t measuring the right variables to predict an outcome, your predictions aren’t going to be accurate. Thus, variable selection, is incredibly important.
All that said, there are machine learning approaches that carry out variable selection for you, using all the data to determine which variables in the dataset are most helpful for prediction. Nevertheless, whether you are deciding on the variables to include or the computer is deciding for you, variable selection is important to accurate prediction.
5.12.8.1 Lack of Causality Reminder
As a reminder, as was discussed in the inferential analysis, just because one variable may predict another, it does not mean that one causes the other. In predictive analysis, you are taking advantage of the relationship between two variables, using one variable (or one set of variables) to predict a second variable. Just because one variable accurately predicts another variable does not mean that they are causally related.
5.12.9 Model Selection
Additionally, there are many ways to generate prediction models. Each model was developed for a different and specific purpose. However, regardless of which model you choose to use for prediction, it’s best to keep in mind that, in general, the more data you have and the simpler your model is, the best chance you have at accurately predicting future outcomes:
More data - The more observations you have and the more variables you have to choose from to include in your model, the more likely you are to generate an accurate predictive model. Note, however, large datasets with lots of missing data or data that have been incorrectly entered are not better than small, complete, and accurate datasets. Having a trustworthy dataset to build your model is critical.
Simple Models - If you can accurately predict an individual’s height by only considering that person’s parents height, then go for it. There’s no need to include other variables if a single variable generates accurate predictions. A simple model that predicts accurately (regardless of the dataset in which you’re predicting) is better than a complicated model.
5.12.10 Regression vs. Classification
Before we jump into discussing the various models you can use for predictive analysis, it’s important to first note the difference between regression and classification. Regression is used when you’re trying to predict a continuous variable. For example if you’re trying to predict an individual’s age, you would use regression. On the other hand, classification is used for categorical variables, as it predicts which group an individual belongs to. An example of a classification would be predicting someone’s education level, as there are only a limited number of groups into which one would be.
With regards to machine learning, certain methods can be used for both regression and classification, while others are designed exclusively for one or the other.
In this lesson we’ll discuss one regression model and one classification model. However, there are literally hundreds of models available for predictive modeling. Thus, it’s important to keep in mind that we’re really just scratching the surface here.
5.12.10.1 Linear Regression
Just like in the previous lesson in inferential analysis, linear regression is an incredibly powerful method in machine learning! The concept here is the same as it was in the last lesson: we’re going to capitalize on the linear relationship between variables. However, instead of using linear regression to estimate something about a larger population, we’re going to use linear regression for prediction of a continuous variable.
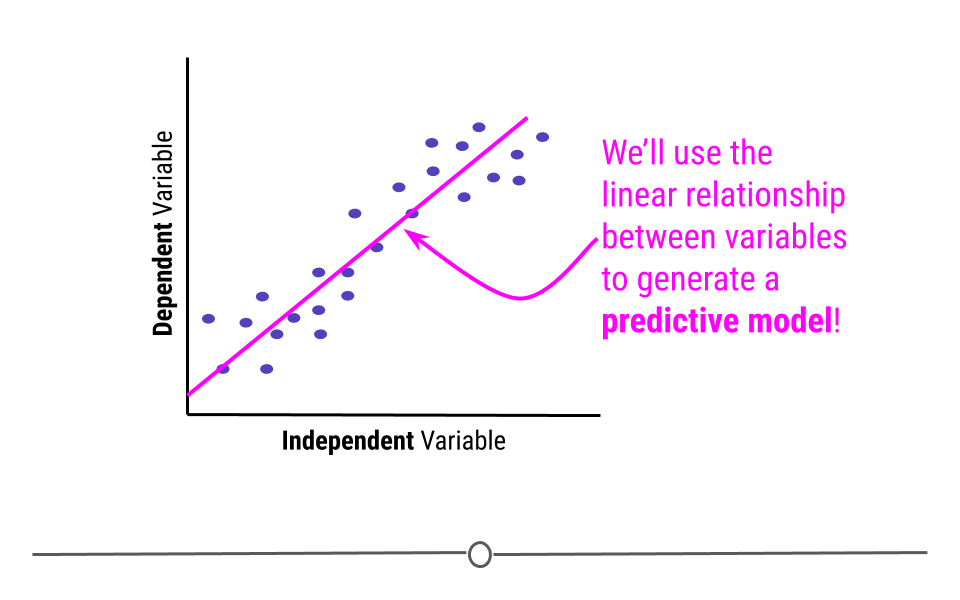
To better understand this, let’s use a conceptual example. Consider trying to predict a child’s age from their height. You’d likely expect that a taller child was older. So, let’s imagine that we’re looking here at the training data. We see the expected relationship between height and age in this scatterplot.
Using the training data, linear regression is then carried out to model the relationship.
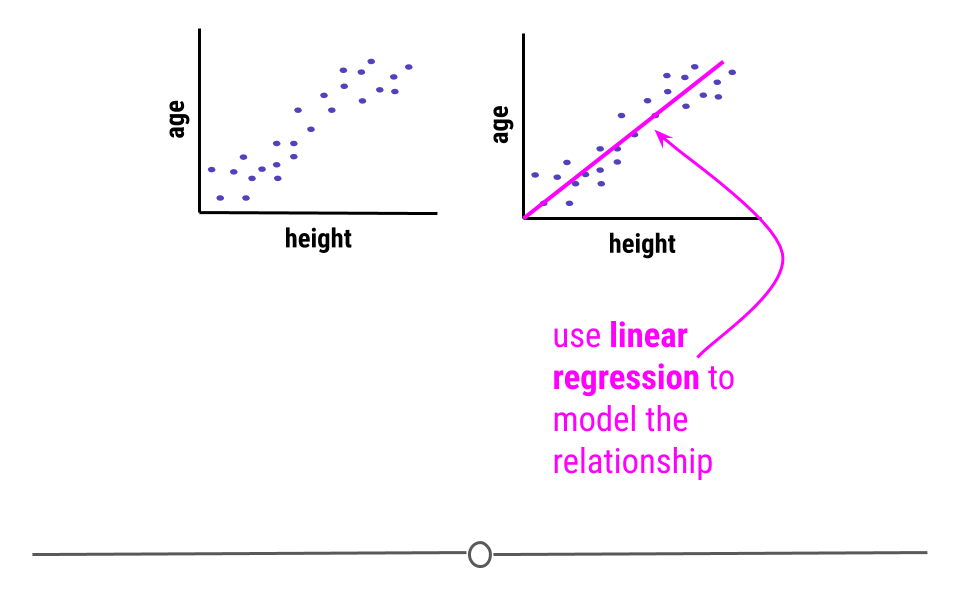
Now that we have our model, we no longer care about the individual data points in the training data. We’ll simply use the linear regression model to make our predictions.
Then, in the future when we know a child’s height, we can return to our linear regression, supply it with the new child’s height and it will return the child’s age using the model we’ve built.
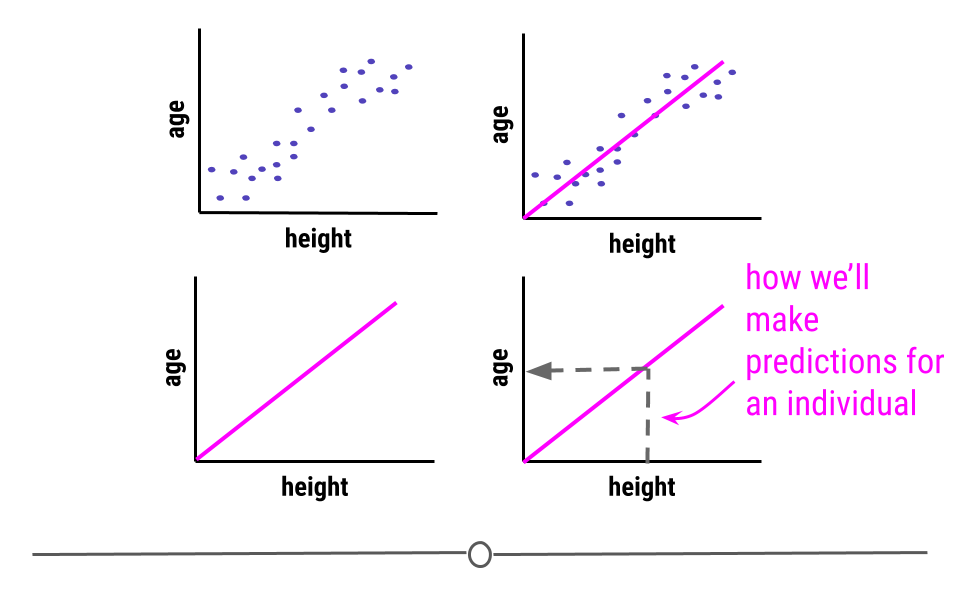
Conceptually, this is what will happen whenever we use linear regression for machine learning. However, it will be carried out mathematically, rather than graphically. This means you won’t have to look on the graph to see your predictions. You’ll just have to run a few lines of code that will carry out the necessary calculations to generate predictions.
Additionally, here we’re using a single variable (height) to model age. Clearly, there are other variables (such as a child’s sex) that could affect this prediction. Often, regression models will include multiple predictor variables that will improve prediction accuracy of the outcome variable.
5.12.10.2 Classification and Regression Trees (CART)
Alternatively, when trying to predict a categorical variable, you’ll want to look at classification methods, rather than regression (which is for continuous variables). In these cases you may consider using a classification and regression tree (CART) for prediction. While not the only classification method for machine learning, CARTs are a basic and commonly-used approach to prediction for categorical variables.
Conceptually, when using a CART for prediction, a decision tree is generated from the training data. A decision tree branches the data based on variables within the data. For example, if we were trying to predict an individual’s education level, we would likely use a dataset with information about many different people’s income level, job title, and the number of children they have. These variables would then be used to generate the tree.
For example, maybe the first branch would separate individuals who make less than 40,000 dollars a year. All of those in the training data who made less than 40K would go down the left-hand branch, while everyone else would go down the right-hand branch.
At each level, the data will continue to be split, using the information in the training data.
Finally, a full decision tree will be constructed, such that there will be a label for the variable we’re trying to predict at the end of each branch.
This CART will then be used for prediction in future samples. Thus, if you follow the path along the decision tree, for this example CART, an individual who made more than $40,000 a year, was in a manual labor profession, and had children, this CART would predict that that individual’s education level was “High School.”
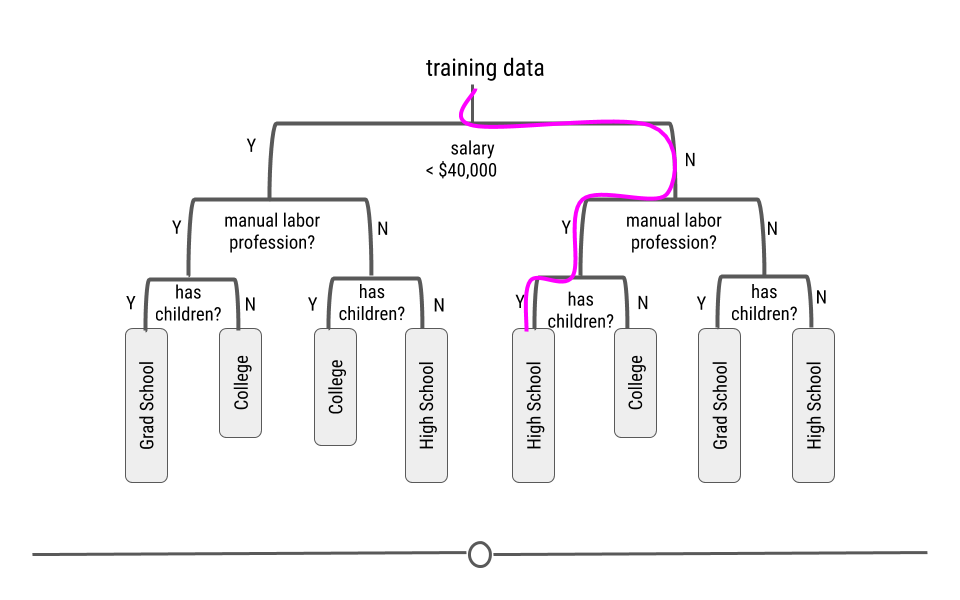
Again, this is conceptually and graphically how a CART works; however, when generating a CART yourself, it again only takes a few lines of code to generate the model and carry out the necessary math.
5.12.11 Model Accuracy
A common saying is that prediction is hard, especially about the future. This is true in predictive analysis. Thus, it’s important to always carefully evaluate the accuracy of your model and to never overstate how well you are able to make predictions.
Generally, if your predictions are correct, you’re doing well! If your predictions are wrong, you’re not doing as well. But, how do we define “well”?
5.12.11.1 Error Rates
To assess whether or not our predictive models are doing well, we calculate error rates. There are metrics used to measure model performance, however, the two most common ways to assess how well our predictive models are doing are:
- RMSE (Root-mean-square Error)
- Accuracy
We’ll note here that in order to assess error, you have to know the truth (the actual value) in addition to the predicted value. Thus, RMSE and accuracy are assessed in the training and tuning data, where you know the actual value as well as the predicted value.
5.12.11.1.1 RMSE
The root-mean-square error (RMSE) is a measure used to assess prediction error for continuous variables. Generally, we want to minimize error in prediction. Thus, a small RMSE is better than a large RMSE.
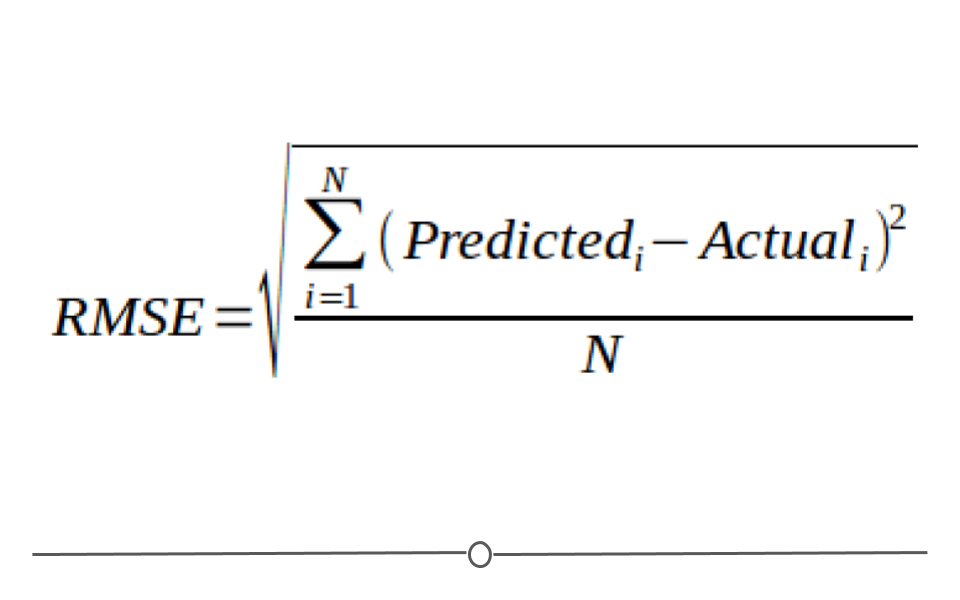
Mathematically speaking, the RMSE is the square root of the variance. From earlier, we know that variance has something to do with how confident we are in our estimate. Since we’re trying to determine how close our predictions are to the actual value, this seems like a good place to start.
When we look at the equation, we can see that the difference between the predicted and actual values is calculated (Predicted - Actual) and that this value is then squared (Predicted - Actual)^2. These differences squared are then added for every individual in your dataset (that’s what the sigma, or big E says). This value (the sum of all the errors squared) is then divided by the number of individuals in your dataset (N). This square root of this value is then taken. This is how RMSE is calculated.
We went through that description because we want to point out that when differences are squared (Predicted - Actual)^2, outliers, or samples whose prediction was far off from their actual value are going to increase the RMSE a lot. Thus, a few outliers can lead to really high RMSE values, even if all the other predictions were pretty good. This means it’s important to check to see if a few outliers (meaning a few bad predictions) are leading to a high RMSE value.
5.12.11.2 Accuracy
Alternatively, to assess error in the prediction of categorical variables, accuracy is frequently used. Accuracy looks to determine the number of predictions that match their actual values.

The closer this value is to 100%, the better your predictive model was. The closer to 0%, the worse your model’s predictions are.
Accuracy is a helpful way to assess error in categorical variables, but it can be used for numeric values too. However, it will only account a prediction “correct” if it matches exactly. In the case of age, if a sample’s age is 10 and the model predicts it to be 10, the model will say it’s been predicted correctly. However, if a sample’s age is 10 and it is predicted to be 9, it will be counted as incorrect, even though it was close. A prediction off by a year will be marked just as incorrect as a sample predicted off by 50 years. Due to this, RMSE is often opted for instead of accuracy for continuous variables.
It is also important to realize that having low RMSE or high accuracy with your training does not necessarily indicate that your model is generalizable. It indicates that your model works well with your training data. However if your model fits your training data too well it may not be very good at predicting with new data. This is why we have a subset of the original data to use to test our model.
5.13 The tidymodels Ecosystem
There are incredibly helpful packages available in R thanks to the work of Max Kuhn at RStudio. As mentioned above, there are hundreds of different machine learning algorithms. Max’s R packages have put many of them into a single framework, allowing you to use many different machine learning models easily. Additionally, he has written a very helpful book about predictive modeling. There are also many helpful links about each of the packages. Max previously developed the caret package (short for Classification And Regression Training) which has been widely used. Here you can see some of the discussion about the difference between caret and tidymodels.
In this rstudio community thread you can see that Max stated that “The tidyverse is more about modular packages that are designed to play well with one another. The main issue with caret is that, being all in one package, it is very difficult to extend it into areas that people are interested in…The bottom line is that the tidymodels set should do what caret does and more.” We will describe some of the advantages of the tidymodels packages.
5.13.1 Benefits of tidymodels
The two major benefits of tidymodels are:
- Standardized workflow/format/notation across different types of machine learning algorithms
Different notations are required for different algorithms as the algorithms have been developed by different people. This would require the painstaking process of reformatting the data to be compatible with each algorithm if multiple algorithms were tested.
- Can easily modify preprocessing, algorithm choice, and hyperparameter tuning making optimization easy
Modifying a piece of the overall process is now easier than before because many of the steps are specified using the tidymodels packages in a convenient manner. Thus the entire process can be rerun after a simple change to preprocessing without much difficulty.
5.13.2 Packages of tidymodels
We will focus on the following packages although there are many more in the tidymodels ecosystem:
rsamples- to split the data into training and testing sets (as well as cross validation sets - more on that later!)
recipes- to prepare the data with preprocessing (assign variables and preprocessing steps)
parsnip- to specify and fit the data to a model
yardstickandtune- to evaluate model performance
workflows- combining recipe and parsnip objects into a workflow (this makes it easier to keep track of what you have done and it makes it easier to modify specific steps)tuneanddials- model optimization (more on what hyperparameters are later too!)
broom- to make the output from fitting a model easier to read
Here you can see a visual of how these packages work together in the process of performing a machine learning analysis:
To illustrate how to use each of these packages, we will work through some examples.
These are the major steps that we will cover in addition to some more advanced methods:
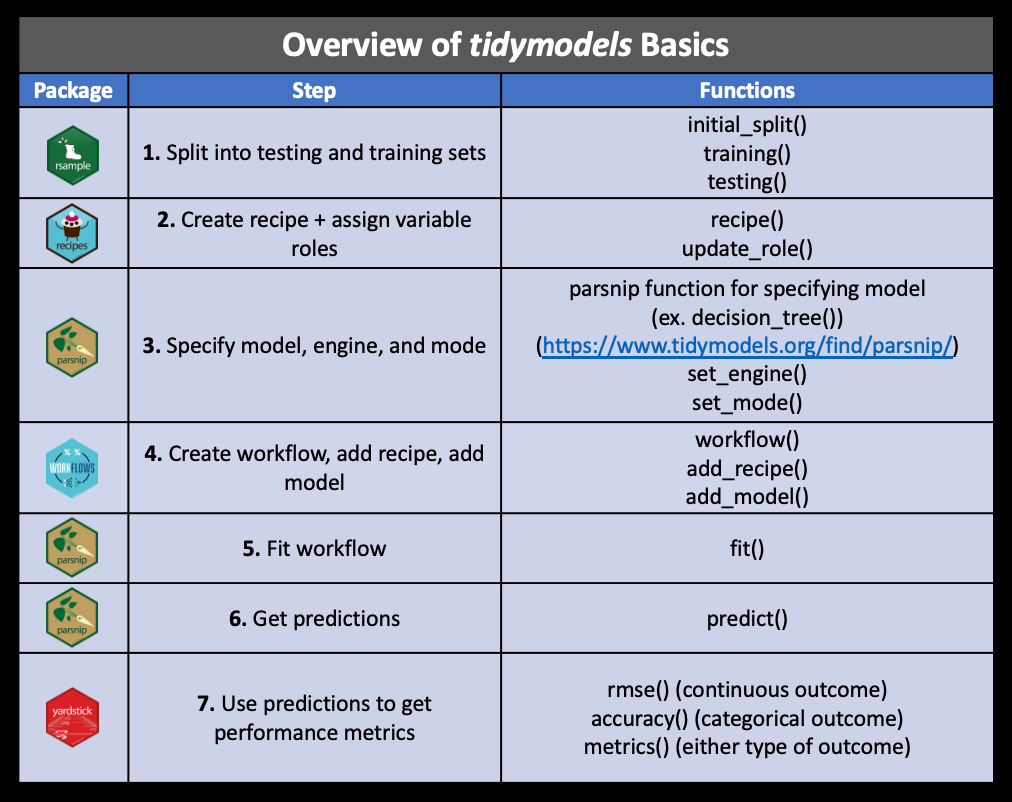
Other tidymodels packages include:

[source]
applicablecompares new data points with the training data to see how much the new data points appear to be an extrapolation of the training data
baguetteis for speeding up bagging pipelines
butcheris for dealing with pipelines that create model objects that take up too much memory
discrimhas more model options for classification
embedhas extra preprocessing options for categorical predictors
hardhathelps you to make new modeling packages
corrrhas more options for looking at correlation matrices
ruleshas more model options for prediction rule ensembles
text recipeshas extra preprocessing options for using text data
tidypredictis for running predictions inside SQL databases
modeldbis also for working within SQL databases and it allows fordplyrandtidyevaluse within a database
tidyposteriorcompares models using resampling statistics
Most of these packages offer advanced modeling options and we will not be covering how to use them.
5.13.3 Example of Continuous Variable Prediction
For this example, we’ll keep it simple and use a dataset you’ve seen before: the iris dataset. This way you can focus on the syntax used in the tidymodels packages and the steps of predictive analysis. In this example, we’ll attempt to use the data in the iris dataset to predict Sepal.Length.
5.13.3.1 Step 1: Example of Data Splitting with rsample
As mentioned above, one of the first steps is to take your dataset and split it into a training set and a testing set. To do this, we’ll load the rsample package and use the initial_split() function to split the dataset.
We can specify what proportion of the data we would like to use for training using the prop argument.
Since the split is performed randomly, it is a good idea to use the set.seed() function in base R to ensure that if your rerun your code that your split will be the same next time.
## <Training/Testing/Total>
## <100/50/150>This results in printing the number of training data rows, the number testing data rows, and the total rows - each is printed with the “/” as a division between the values. Here the training set is called the analysis set, while the testing set is called the assess set.
We can see that about 70% of our observations are in the training dataset and the other 30% are in the tuning dataset, as we specified.
We can then extract the training and testing datasets by using the training() and testing() functions, also of the rsample package.
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.2 3.5 1.5 0.2 setosa
## 2 5.7 2.6 3.5 1.0 versicolor
## 3 6.3 3.3 6.0 2.5 virginica
## 4 6.5 3.2 5.1 2.0 virginica
## 5 6.3 3.4 5.6 2.4 virginica
## 6 6.4 2.8 5.6 2.2 virginica## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.6 3.4 1.4 0.3 setosa
## 3 5.4 3.7 1.5 0.2 setosa
## 4 4.8 3.4 1.6 0.2 setosa
## 5 5.8 4.0 1.2 0.2 setosa
## 6 5.7 4.4 1.5 0.4 setosa5.13.3.2 Step 2: Example of preparing for preprocessing the data with recipes
After splitting the data, the next step is to process the training and testing data so that the data are are compatible and optimized to be used with the model. This involves assigning variables to specific roles within the model and preprocessing like scaling variables and removing redundant variables. This process is also called feature engineering.
To do this in tidymodels, we will create what’s called a “recipe” using the recipes package, which is a standardized format for a sequence of steps for preprocessing the data. This can be very useful because it makes testing out different preprocessing steps or different algorithms with the same preprocessing very easy and reproducible.
Creating a recipe specifies how a dataframe of predictors should be created - it specifies what variables to be used and the preprocessing steps, but it does not execute these steps or create the dataframe of predictors.
5.13.3.2.1 Step 1: Specify variables with the recipe() function
The first thing to do to create a recipe is to specify which variables we will be using as our outcome and predictors using the recipe() function. In terms of the metaphor of baking, we can think of this as listing our ingredients. Translating this to the recipes package, we use the recipe() function to assign roles to all the variables.
We can do so in two ways:
- Using formula notation
- Assigning roles to each variable
Let’s look at the first way using formula notation, which looks like this:
outcome(s) ~ predictor(s)
If in the case of multiple predictors or a multivariate situation with two outcomes, use a plus sign:
outcome1 + outcome2 ~ predictor1 + predictor2
If we want to include all predictors we can use a period like so:
outcome_variable_name ~ .
Let’s make our first recipe with the iris data! We will first try to predict Sepal.Length in our training data based on Sepal.Width and the Species. Thus, Sepal.Length is our outcome variable and Sepal.Width and Species are our predictor variables.
First we can specify our variables using formula notation:
##
## Attaching package: 'recipes'## The following object is masked from 'package:stringr':
##
## fixed## The following object is masked from 'package:stats':
##
## step## ## ── Recipe ──────────────────────────────────────────────────────────────────────## ## ── Inputs## Number of variables by role## outcome: 1
## predictor: 2Alternatively, we could also specify the outcome and predictor(s) by assigning roles to the variables by using the update_role() function. Please see here for examples of the variety of roles variables can take.
We first need to use the recipe() function with this method to specify what data we are using.
first_recipe <- recipe(training_iris) %>%
recipes::update_role(Sepal.Length, new_role = "outcome") %>%
recipes::update_role(Sepal.Width, new_role = "predictor") %>%
recipes::update_role(Species, new_role = "predictor")
first_recipe## ## ── Recipe ──────────────────────────────────────────────────────────────────────## ## ── Inputs## Number of variables by role## outcome: 1
## predictor: 2
## undeclared role: 2We can view our recipe using the base summary() function.
## # A tibble: 5 × 4
## variable type role source
## <chr> <list> <chr> <chr>
## 1 Sepal.Length <chr [2]> outcome original
## 2 Sepal.Width <chr [2]> predictor original
## 3 Petal.Length <chr [2]> <NA> original
## 4 Petal.Width <chr [2]> <NA> original
## 5 Species <chr [3]> predictor original5.13.3.2.2 Step 2: Specify the preprocessing steps with step*() functions
Next, we use the step*() functions from the recipe package to specify preprocessing steps.
This link and this link show the many options for recipe step functions.
There are step functions for a variety of purposes:
- Imputation – filling in missing values based on the existing data
- Transformation – changing all values of a variable in the same way, typically to make it more normal or easier to interpret
- Discretization – converting continuous values into discrete or nominal values - binning for example to reduce the number of possible levels (However this is generally not advisable!)
- Encoding / Creating Dummy Variables – creating a numeric code for categorical variables (More on Dummy Variables and one-hot encoding)
- Data type conversions – which means changing from integer to factor or numeric to date etc.
- Interaction term addition to the model – which means that we would be modeling for predictors that would influence the capacity of each other to predict the outcome
- Normalization – centering and scaling the data to a similar range of values
- Dimensionality Reduction/ Signal Extraction – reducing the space of features or predictors to a smaller set of variables that capture the variation or signal in the original variables (ex. Principal Component Analysis and Independent Component Analysis)
- Filtering – filtering options for removing variables (ex. remove variables that are highly correlated to others or remove variables with very little variance and therefore likely little predictive capacity)
- Row operations – performing functions on the values within the rows (ex. rearranging, filtering, imputing)
- Checking functions – Sanity checks to look for missing values, to look at the variable classes etc.
All of the step functions look like step_*() with the * replaced with a name, except for the check functions which look like check_*().
There are several ways to select what variables to apply steps to:
- Using
tidyselectmethods:contains(),matches(),starts_with(),ends_with(),everything(),num_range()
- Using the type:
all_nominal(),all_numeric(),has_type() - Using the role:
all_predictors(),all_outcomes(),has_role() - Using the name - use the actual name of the variable/variables of interest
Let’s try adding a preprocessing step to our recipe.
We might want to potentially one-hot encode some of our categorical variables so that they can be used with certain algorithms like a linear regression require numeric predictors.
We can do this with the step_dummy() function and the one_hot = TRUE argument.
One-hot encoding means that we do not simply encode our categorical variables numerically, as our numeric assignments can be interpreted by algorithms as having a particular rank or order.
Instead, binary variables made of 1s and 0s are used to arbitrarily assign a numeric value that has no apparent order.
## ## ── Recipe ──────────────────────────────────────────────────────────────────────## ## ── Inputs## Number of variables by role## outcome: 1
## predictor: 2
## undeclared role: 2## ## ── Operations## • Dummy variables from: Species5.13.3.3 Step 3: Example of optionally performing the preprocessing to see how it influences the data
Optionally one can use the prep() function of the recipes package to update the recipe for manually performing the preprocessing to see how this influences the data. This step is however not required when using the workflows package. The preprocessed training data can than be viewed by using the bake() function with the new_data = NULL argument, while preprocessed testing data can be viewed using the bake() function and specifying that the testing data is the new_data.
The prep() function estimates parameters (estimating the required quantities and statistics required by the steps for the variables) for preprocessing and updates the variables roles, as sometimes predictors may be removed, this allows the recipe to be ready to use on other datasets.
It does not necessarily actually execute the preprocessing itself, however we will specify using the retain argument for it to do this so that we can take a look at the preprocessed data.
There are some important arguments to know about:
training- you must supply a training dataset to estimate parameters for preprocessing operations (recipe steps) - this may already be included in your recipe - as is the case for usfresh- iffresh=TRUE, - will retrain and estimate parameters for any previous steps that were already prepped if you add more steps to the recipeverbose- ifverbose=TRUE, shows the progress as the steps are evaluated and the size of the preprocessed training setretain- ifretain=TRUE, then the preprocessed training set will be saved within the recipe (as template). This is good if you are likely to add more steps and do not want to rerun theprep()on the previous steps. However this can make the recipe size large. This is necessary if you want to actually look at the preprocessed data.
Let’s try out the prep() function:
## oper 1 step dummy [training]
## The retained training set is ~ 0.01 Mb in memory.## ## ── Recipe ──────────────────────────────────────────────────────────────────────## ## ── Inputs## Number of variables by role## outcome: 1
## predictor: 2
## undeclared role: 2## ## ── Training information## Training data contained 100 data points and no incomplete rows.## ## ── Operations## • Dummy variables from: Species | Trained## [1] "var_info" "term_info" "steps" "template"
## [5] "retained" "requirements" "ptype" "tr_info"
## [9] "orig_lvls" "fit_times" "last_term_info"There are also lots of useful things to checkout in the output of prep().
You can see:
- the
stepsthat were run
- the original variable info (
var_info)
- the updated variable info after preprocessing (
term_info) - the new
levelsof the variables - the original levels of the variables (
orig_lvls) - info about the training dataset size and completeness (
tr_info)
We can see these using the $ notation:
## # A tibble: 5 × 4
## variable type role source
## <chr> <list> <chr> <chr>
## 1 Sepal.Length <chr [2]> outcome original
## 2 Sepal.Width <chr [2]> predictor original
## 3 Petal.Length <chr [2]> <NA> original
## 4 Petal.Width <chr [2]> <NA> original
## 5 Species <chr [3]> predictor originalNow we can use bake to see the preprocessed training data.
Note: this used to require the juice() function.
Since we are using our training data we need to specify that we don’t have new_data with new_data = NULL.
## Rows: 100
## Columns: 7
## $ Sepal.Length <dbl> 5.2, 5.7, 6.3, 6.5, 6.3, 6.4, 6.8, 7.9, 6.2, 7.1, 5…
## $ Sepal.Width <dbl> 3.5, 2.6, 3.3, 3.2, 3.4, 2.8, 3.2, 3.8, 2.9, 3.0, 2…
## $ Petal.Length <dbl> 1.5, 3.5, 6.0, 5.1, 5.6, 5.6, 5.9, 6.4, 4.3, 5.9, 4…
## $ Petal.Width <dbl> 0.2, 1.0, 2.5, 2.0, 2.4, 2.2, 2.3, 2.0, 1.3, 2.1, 1…
## $ Species_setosa <dbl> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, …
## $ Species_versicolor <dbl> 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, …
## $ Species_virginica <dbl> 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, …We can see that the Species variable has been replaced by 3 variables representing the 3 different species numerically with zeros and ones.
Now we do the same for our testing data using bake(). You generally want to leave your testing data alone, but it is good to look for issues like the introduction of NA values if you have complicated preprocessing steps and you want to make sure this performs as you expect.
## Rows: 50
## Columns: 7
## $ Sepal.Length <dbl> 5.1, 4.6, 5.4, 4.8, 5.8, 5.7, 5.1, 4.6, 5.1, 5.2, 4…
## $ Sepal.Width <dbl> 3.5, 3.4, 3.7, 3.4, 4.0, 4.4, 3.5, 3.6, 3.3, 3.4, 3…
## $ Petal.Length <dbl> 1.4, 1.4, 1.5, 1.6, 1.2, 1.5, 1.4, 1.0, 1.7, 1.4, 1…
## $ Petal.Width <dbl> 0.2, 0.3, 0.2, 0.2, 0.2, 0.4, 0.3, 0.2, 0.5, 0.2, 0…
## $ Species_setosa <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
## $ Species_versicolor <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ Species_virginica <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …Great! Now back to the typical steps.
5.13.3.4 Step 4: Example of specifying the model with parsnip
So far we have used the packages rsample to split the data and recipes to assign variable types, and to specify and prep our preprocessing (as well as to optionally extract the preprocessed data).
We will now use the parsnip package (which is similar to the previous caret package - and hence why it is named after the vegetable) to specify our model.
There are four things we need to define about our model:
- The type of model (using specific functions in parsnip like
rand_forest(),logistic_reg()etc.)
- The package or engine that we will use to implement the type of model selected (using the
set_engine()function) - The mode of learning - classification or regression (using the
set_mode()function) - Any arguments necessary for the model/package selected (using the
set_args()function - for example themtry =argument for random forest which is the number of variables to be used as options for splitting at each tree node)
Let’s walk through these steps one by one. For our case, we are going to start our analysis with a linear regression but we will demonstrate how we can try different models.
The first step is to define what type of model we would like to use.
See here for modeling options in parsnip.
We want to do a linear regression so we will use the linear_reg() function of the parsnip package.
## Linear Regression Model Specification (regression)
##
## Computational engine: lmOK. So far, all we have defined is that we want to use a linear regression. Now let’s tell parsnip more about what we want.
We would like to use the ordinary least squares method to fit our linear regression.
So we will tell parsnip that we want to use the lm package to implement our linear regression (there are many options actually such as rstan glmnet, keras, and sparklyr). See here for a description of the differences and using these different engines with parsnip.
We will do so by using the set_engine() function of the parsnip package.
## Linear Regression Model Specification (regression)
##
## Computational engine: lmSome packages can do either classification or regression, so it is a good idea to specify which mode you intend to perform.
Here, we aim to predict a continuous variable, thus we want to perform a regression analysis.
You can do this with the set_mode() function of the parsnip package, by using either set_mode("classification") or set_mode("regression").
Lin_reg_model <-
Lin_reg_model %>%
parsnip::set_engine("lm") %>%
parsnip::set_mode("regression")
Lin_reg_model## Linear Regression Model Specification (regression)
##
## Computational engine: lm5.13.3.5 Step 5: Example of fitting the model
We can use the parsnip package with a newer package called workflows to fit our model.
The workflows package allows us to keep track of both our preprocessing steps and our model specification. It also allows us to implement fancier optimizations in an automated way and it can also handle post-processing operations.
We begin by creating a workflow using the workflow() function in the workflows package.
Next, we use add_recipe() (our preprocessing specifications) and we add our model with the add_model() function – both functions from the workflows package.
Note: We do not need to actually prep() our recipe before using workflows - this was just optional so we could take a look at the preprocessed data!
iris_reg_wflow <-workflows::workflow() %>%
workflows::add_recipe(first_recipe) %>%
workflows::add_model(Lin_reg_model)
iris_reg_wflow## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: linear_reg()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 1 Recipe Step
##
## • step_dummy()
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Linear Regression Model Specification (regression)
##
## Computational engine: lmAh, nice. Notice how it tells us about both our preprocessing steps and our model specifications.
Next, we “prepare the recipe” (or estimate the parameters) and fit the model to our training data all at once. Printing the output, we can see the coefficients of the model.
## ══ Workflow [trained] ══════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: linear_reg()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 1 Recipe Step
##
## • step_dummy()
##
## ── Model ───────────────────────────────────────────────────────────────────────
##
## Call:
## stats::lm(formula = ..y ~ ., data = data)
##
## Coefficients:
## (Intercept) Sepal.Width Species_setosa Species_versicolor
## 4.4406 0.7228 -1.9013 -0.5232
## Species_virginica
## NA5.13.3.6 Step 6: Example of assessing the model performance
Recall that often for regression analysis we use the RMSE to assess model performance.
To get this we first need to get the predicted (also called “fitted”) values.
We can get these values using the pull_workflow_fit() function of the workflows package. These values are in the $fit$fitted.values slot of the output. Alternatively, we can use the predict() function with the workflow and the training data specified as the new_data.
FALSE Warning: `pull_workflow_fit()` was deprecated in workflows 0.2.3.
FALSE ℹ Please use `extract_fit_parsnip()` instead.
FALSE This warning is displayed once every 8 hours.
FALSE Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
FALSE generated.FALSE 1 2 3 4 5 6
FALSE 5.069194 5.796771 6.825955 6.753671 6.898239 6.464535FALSE Warning in predict.lm(object = object$fit, newdata = new_data, type =
FALSE "response", : prediction from rank-deficient fit; consider predict(.,
FALSE rankdeficient="NA")FALSE # A tibble: 100 × 1
FALSE .pred
FALSE <dbl>
FALSE 1 5.07
FALSE 2 5.80
FALSE 3 6.83
FALSE 4 6.75
FALSE 5 6.90
FALSE 6 6.46
FALSE 7 6.75
FALSE 8 7.19
FALSE 9 6.01
FALSE 10 6.61
FALSE # ℹ 90 more rowsTo get more information about the prediction for each sample, we can use the augment() function of the broom package. This requires using the preprocessed training data from bake() (or with previous versions juice()), as well as the predicted values from either of the two previous methods.
wf_fitted_values <-
broom::augment(wf_fit$fit, data = preproc_train) %>%
select(Sepal.Length, .fitted:.std.resid)
head(wf_fitted_values)FALSE # A tibble: 6 × 6
FALSE Sepal.Length .fitted .hat .sigma .cooksd .std.resid
FALSE <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
FALSE 1 5.2 5.07 0.0336 0.459 0.000738 0.292
FALSE 2 5.7 5.80 0.0340 0.459 0.000409 -0.216
FALSE 3 6.3 6.83 0.0362 0.456 0.0129 -1.17
FALSE 4 6.5 6.75 0.0315 0.458 0.00259 -0.565
FALSE 5 6.3 6.90 0.0429 0.455 0.0201 -1.34
FALSE 6 6.4 6.46 0.0317 0.459 0.000169 -0.144# other option:
# wf_fitted_values <-
# broom::augment(predict(iris_reg_wflow_fit, new_data = training_iris),
# data = preproc_train) %>%
# select(Sepal.Length, .fitted:.std.resid)
#
# head(wf_fitted_values)Nice, now we can see what the original value for Sepal.Length right next to the predicted .fitted value, as well as standard errors and other metrics for each value.
Now we can use the rmse() function of the yardstick package to compare the truth, which is the Sepal.Length variable, to the predicted or estimate variable which in the previous output is called .fitted.
## # A tibble: 1 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 rmse standard 0.447We can see that our RMSE was 0.4472046. This is fairly low, so our model did pretty well.
We can also make a plot to visualize how well we predicted Sepal.Length.
wf_fitted_values %>%
ggplot(aes(x = Sepal.Length, y = .fitted)) +
geom_point() +
geom_smooth(method = "lm") +
labs( x = "True Sepal Length", y = "Predicted Sepal Length")## `geom_smooth()` using formula = 'y ~ x'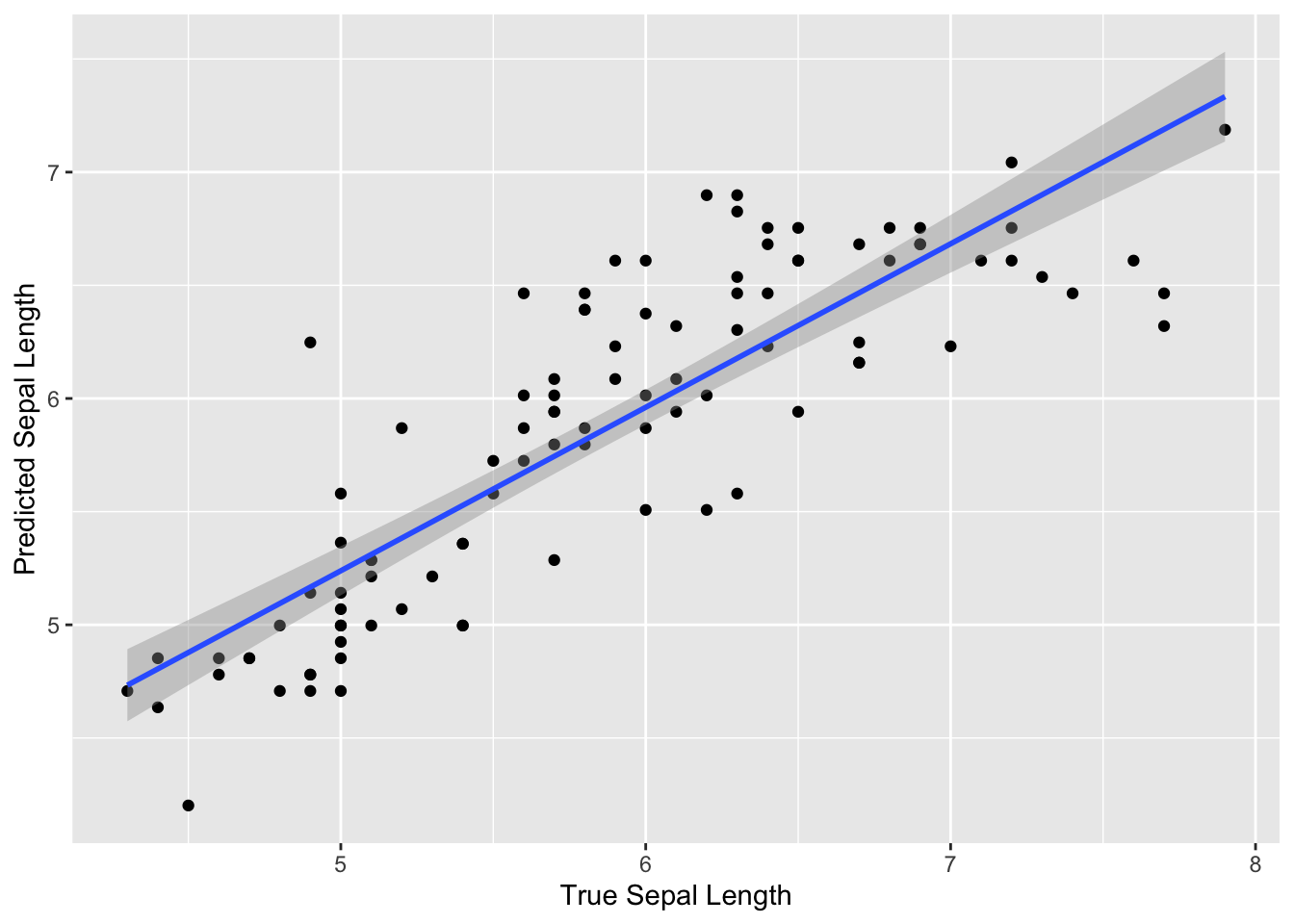
We can see that overall our model predicted the sepal length fairly well, as the predicted values are fairly close to the true values. We can also see that the predictions were similar to the truth for the full range of true sepal length values.
Typically we might modify our preprocessing steps or try a different model until we were satisfied with the performance on our training data. Assuming we are satisfied, we could then perform a final assessment of our model using the testing data.
With the workflows package, we can use the splitting information for our original data split_iris to fit the final model on the full training set and also on the testing data using the last_fit() function of the tune package. No preprocessing steps are required.
We can do this by using the last_fit() function of the tune package.
FALSE → A | warning: prediction from rank-deficient fit; consider predict(., rankdeficient="NA")FALSE There were issues with some computations A: x1
FALSE There were issues with some computations A: x1FALSE FALSE # Resampling results
FALSE # Manual resampling
FALSE # A tibble: 1 × 6
FALSE splits id .metrics .notes .predictions .workflow
FALSE <list> <chr> <list> <list> <list> <list>
FALSE 1 <split [100/50]> train/test split <tibble> <tibble> <tibble> <workflow>
FALSE
FALSE There were issues with some computations:
FALSE
FALSE - Warning(s) x1: prediction from rank-deficient fit; consider predict(., rankdefic...
FALSE
FALSE Run `show_notes(.Last.tune.result)` for more information.We can then use the collect_metrics() function of the tune package to get the RMSE:
## # A tibble: 2 × 4
## .metric .estimator .estimate .config
## <chr> <chr> <dbl> <chr>
## 1 rmse standard 0.403 Preprocessor1_Model1
## 2 rsq standard 0.733 Preprocessor1_Model1We can see that our RMSE is pretty similar for the testing data as well.
5.13.4 Example of Categorical Variable Prediction
Now we are going to show an example of using the tidymodels packages to perform prediction of a categorical variable.
Again, we will use the iris dataset. However, this time the will predict the identity of the flower species (which is categorical) based on the other variables.
We have already split our data into testing and training sets, so we don’t necessarily need to do that again.
However, we can stratify our split by a particular feature of the data using the strata argument of the initial_split() function.
This is useful to make sure that there is good representation of each species in our testing and training data.
## <Training/Testing/Total>
## <99/51/150>## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.2 3.5 1.5 0.2 setosa
## 2 5.7 2.6 3.5 1.0 versicolor
## 3 6.3 3.3 6.0 2.5 virginica
## 4 6.5 3.2 5.1 2.0 virginica
## 5 6.3 3.4 5.6 2.4 virginica
## 6 6.4 2.8 5.6 2.2 virginica## Species n
## 1 setosa 32
## 2 versicolor 32
## 3 virginica 36## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.6 3.4 1.4 0.3 setosa
## 3 5.4 3.7 1.5 0.2 setosa
## 4 4.8 3.4 1.6 0.2 setosa
## 5 5.8 4.0 1.2 0.2 setosa
## 6 5.7 4.4 1.5 0.4 setosa## Species n
## 1 setosa 18
## 2 versicolor 18
## 3 virginica 14Great, indeed we have good representation of all 3 species in both the training and testing sets.
This time we will also show an example of how to perform what is called cross validation. This process allows us to get a better estimate about the performance of our model using just our training data by splitting it into multiple pieces to assess the model fit over and over. This is helpful for making sure that our model will be generalizable, meaning that it will work well with a variety of new datasets. Recall that using an independent validation set is part of what we call out-of-sample testing to get a sense of how our model might perform with new datasets. Cross validation helps us to get a sense of this using our training data, so that we can build a better more generalizable model.
By creating subsets of the data, we can test the model performance on each subset which is also a type of out-of-sample testing, as we are not using the entire training dataset, but subsets of the data which may have different properties than that of the full training dataset or each other. For example certain subsets may happen to have unusual values for a particular predictor that are muted by the larger training dataset. With each round of cross validation we perform training and testing on subsets of the training data. This gives us estimates of the out-of-sample performance, where the out-of-sample error or generalization error indicates how often predictions are incorrect in the smaller testing subsets of the training data.
Cross validation is also helpful for optimizing what we call hyperparameters.
Hyperparameters are aspects about the model that we need to specify. Often packages will choose a default value, however it is better to use the training data to see what value appears to yield the best model performance.
For example, the different options at each split in a decision tree is called a node. The minimum number of data points for a node to be split further when creating a decision tree model is a hyperparameter.
Recall from our example of a decision tree:
If there were only 3 people who made more than 40,000 and our hyperparameter for the minimum number of data points to continue creating new branches was 6, then this side of the tree would stop here.
We will show how to optimize this using cross validation, this process is also called “tuning”, as we are tuning or adjusting the hyperparameter until we see the best performance with our training data.
The first thing we need to do to perform this process is split our training data into cross validation samples.
Technically creating our testing and training set out of our original training data is sometimes considered a form of cross validation, called the holdout method.
The reason we do this is so we can get a better sense of the accuracy of our model using data that we did not train on.
However, we can do a better job of optimizing our model for accuracy if we also perform another type of cross validation on just the newly defined training set that we just created.
There are many cross validation methods and most can be easily implemented using the rsample package. See here for options.
Here, we will use a very popular method called either v-fold or k-fold cross validation.
This method involves essentially preforming the holdout method iteratively with the training data.
First, the training set is divided into \(v\) (or often called called \(k\)) equally sized smaller pieces. The number of \(v\) subsets to use is also a bit arbitrary, although generally speaking using 10 folds is good practice, but this depends on the variability and size of your dataset.
We are going to use 4 folds for the sake of expediency and simplicity.
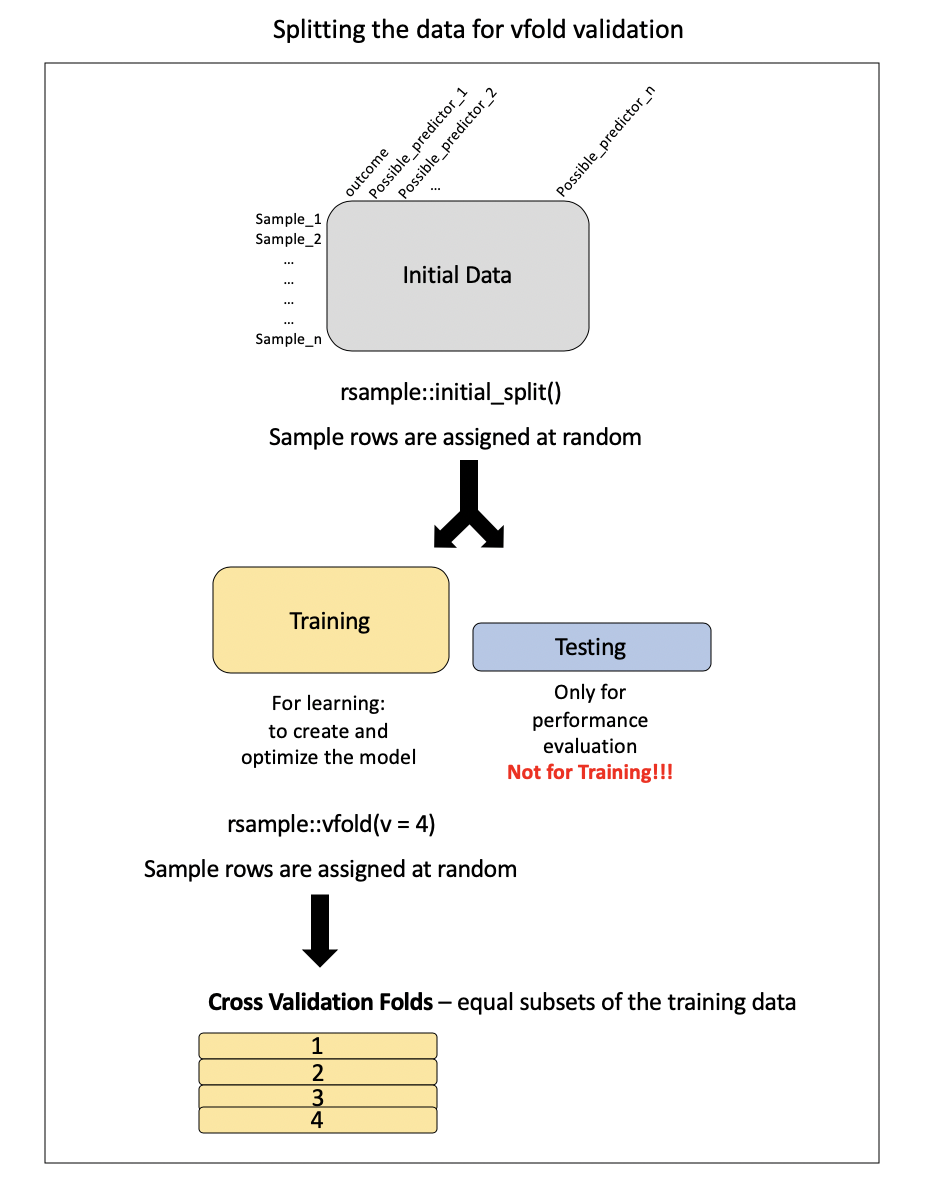
The model will be trained on \(v\)-1 subsets of the data iteratively (removing a different \(v\) until all possible \(v\)-1 sets have been evaluated), while one fold will be saved to act as a test set. This will give us a sense of the out-of-sample (meaning not the entire training sample) performance of the model.
In the case of tuning, multiple values for the hyperparameter are tested to determine what yields the best model performance.
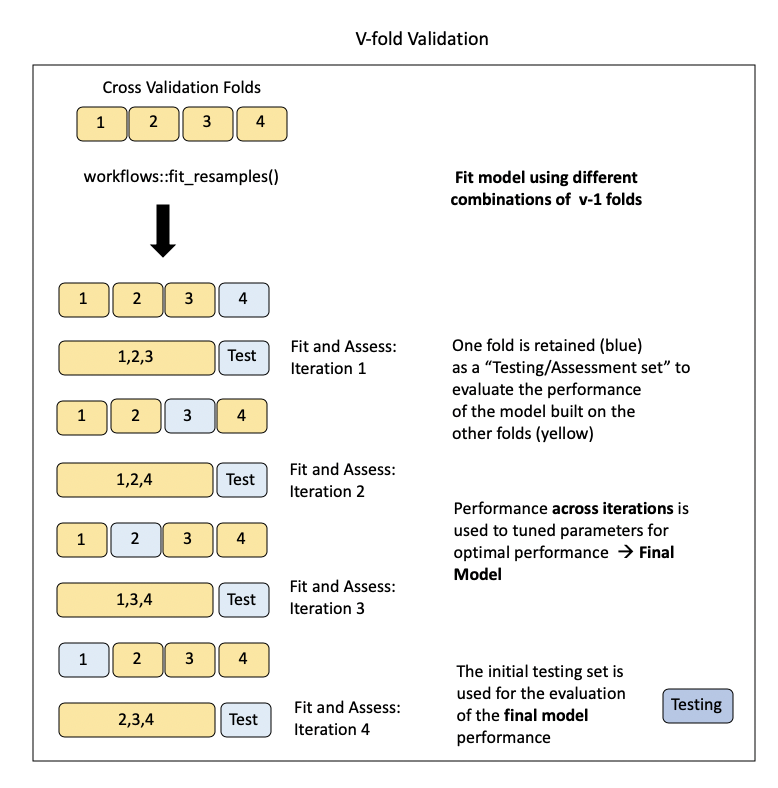
5.13.4.1 Example of creating cross validation samples with rsample
The vfold_cv() function of the rsample package can be used to parse the training data into folds for \(v\)-fold cross validation.
- The
vargument specifies the number of folds to create. - The
repeatsargument specifies if any samples should be repeated across folds - default isFALSE - The
strataargument specifies a variable to stratify samples across folds - just like ininitial_split().
Again, because these are created at random, we need to use the base set.seed() function in order to obtain the same results each time.
Remember that only the training data is used to create the cross validation samples.
## # 4-fold cross-validation
## # A tibble: 4 × 2
## splits id
## <list> <chr>
## 1 <split [75/25]> Fold1
## 2 <split [75/25]> Fold2
## 3 <split [75/25]> Fold3
## 4 <split [75/25]> Fold4## [[1]]
## <Analysis/Assess/Total>
## <75/25/100>
##
## [[2]]
## <Analysis/Assess/Total>
## <75/25/100>
##
## [[3]]
## <Analysis/Assess/Total>
## <75/25/100>
##
## [[4]]
## <Analysis/Assess/Total>
## <75/25/100>Now we can see that we have created 4 folds of the data and we can see how many values were set aside for testing (called assessing for cross validation sets) and training (called analysis for cross validation sets) within each fold.
First we will just use cross validation to get a better sense of the out-of-sample performance of our model using just the training data. Then we will show how to modify this to perform tuning.
If we want to take a look at the cross validation splits we can do so like this:
first_fold <-vfold_iris$splits[[1]]
head(as.data.frame(first_fold, data = "analysis")) # training set of this fold## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.2 3.5 1.5 0.2 setosa
## 2 5.7 2.6 3.5 1.0 versicolor
## 3 6.3 3.3 6.0 2.5 virginica
## 4 6.4 2.8 5.6 2.2 virginica
## 5 6.8 3.2 5.9 2.3 virginica
## 6 7.9 3.8 6.4 2.0 virginica## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 6.5 3.2 5.1 2.0 virginica
## 2 6.3 3.4 5.6 2.4 virginica
## 3 5.9 3.0 4.2 1.5 versicolor
## 4 5.8 2.7 5.1 1.9 virginica
## 5 5.1 3.8 1.6 0.2 setosa
## 6 6.0 2.7 5.1 1.6 versicolor5.13.4.2 Example of creating another recipe, model and workflow
We also need to create a new recipe with different variables assigned to different roles. This time we want to use Species as the outcome. We can use the . notation to indicate that we want to use the rest of the variables as predictors. Thus we will create a new cat_recpipe where we are using a categorical variable as the outcome.
This time we will also not have any preprocessing steps for simplicity sake, thus our recipe is actually already finished.
Now our next step is to specify our model. Again the modeling options for parsnip are here. We will be using a Classification And Regression Tree (CART), which we discussed previously. This method can be used for either classification or regression (categorical or continuous outcome variables). Thus it is important that we set the mode for classification. We will use the rpart package as our engine. To tune using this model we would need to specify it here as well. We will show that in just a bit.
library(rpart)
cat_model <- parsnip::decision_tree() %>%
parsnip::set_mode("classification") %>%
parsnip::set_engine("rpart")
cat_model## Decision Tree Model Specification (classification)
##
## Computational engine: rpartGreat! Now we will make a workflow for this.
iris_cat_wflow <-workflows::workflow() %>%
workflows::add_recipe(cat_recipe) %>%
workflows::add_model(cat_model)
iris_cat_wflow## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: decision_tree()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 0 Recipe Steps
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Decision Tree Model Specification (classification)
##
## Computational engine: rpartSo our next step is to fit and tune the model with our training data cross validation subsets.
5.13.4.3 Example of assessing model performance with cross validation using tune
First we will demonstrate how we could fit the model using our entire training dataset like we did previously and use yardstick to check the accuracy this time instead of RMSE.
## ══ Workflow [trained] ══════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: decision_tree()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 0 Recipe Steps
##
## ── Model ───────────────────────────────────────────────────────────────────────
## n= 100
##
## node), split, n, loss, yval, (yprob)
## * denotes terminal node
##
## 1) root 100 64 virginica (0.32000000 0.32000000 0.36000000)
## 2) Petal.Length< 2.6 32 0 setosa (1.00000000 0.00000000 0.00000000) *
## 3) Petal.Length>=2.6 68 32 virginica (0.00000000 0.47058824 0.52941176)
## 6) Petal.Length< 4.85 33 2 versicolor (0.00000000 0.93939394 0.06060606) *
## 7) Petal.Length>=4.85 35 1 virginica (0.00000000 0.02857143 0.97142857) *The output is a bit different for categorical variables. We can also see variable importance from the model fit, which shows which variables were most important for classifying the data values. This lists a score for each variable which shows the decrease in error when splitting by this variable relative to others.
## Petal.Length Petal.Width Sepal.Length Sepal.Width
## 60.85957 55.73558 42.94372 19.08610We can see that Petal.Width was the most important for predicting Species.
Recall that since we are using a categorical outcome variable, we want to use accuracy to assess model performance. Thus, we can use the accuracy() function of the yardstick package instead of the rmse() function to assess the model. We first need to get the predicted values using the predict() function, as these are not in the fit output.
pred_species<-predict(iris_cat_wflow_fit, new_data = training_iris)
yardstick::accuracy_vec(
truth = training_iris$Species, estimate = pred_species$.pred_class)## [1] 0.97It looks like 97% of the time our model correctly predicted the right species.
We can also see which species were correctly predicted using count function.
## Species n
## 1 setosa 32
## 2 versicolor 32
## 3 virginica 36## # A tibble: 3 × 2
## .pred_class n
## <fct> <int>
## 1 setosa 32
## 2 versicolor 33
## 3 virginica 35We can see that one extra versicolor iris was predicted, and one fewer virginica iris.
To see exactly which rows resulted in incorrect predictions, we can bind the predicted species to the training data like so. This can be helpful to see if there is something particular about the incorrectly predicted values that might explain why they are incorrectly predicted.
predicted_and_truth <-bind_cols(training_iris,
predicted_species = pull(pred_species, .pred_class))
head(predicted_and_truth)## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.2 3.5 1.5 0.2 setosa
## 2 5.7 2.6 3.5 1.0 versicolor
## 3 6.3 3.3 6.0 2.5 virginica
## 4 6.5 3.2 5.1 2.0 virginica
## 5 6.3 3.4 5.6 2.4 virginica
## 6 6.4 2.8 5.6 2.2 virginica
## predicted_species
## 1 setosa
## 2 versicolor
## 3 virginica
## 4 virginica
## 5 virginica
## 6 virginicaHowever, to fit the model to our cross validation folds we can use the fit_resamples() function of the tune package, by specifying our workflow object and the cross validation fold object we just created.
See here for more information.
We can now take a look at various performance metrics based on the fit of our cross validation “resamples”.
To do this we will use the collect_metrics function of the tune package. This will show us the mean of the accuracy estimate of the different cross validation folds.
## # Resampling results
## # 4-fold cross-validation
## # A tibble: 4 × 4
## splits id .metrics .notes
## <list> <chr> <list> <list>
## 1 <split [75/25]> Fold1 <tibble [3 × 4]> <tibble [0 × 3]>
## 2 <split [75/25]> Fold2 <tibble [3 × 4]> <tibble [0 × 3]>
## 3 <split [75/25]> Fold3 <tibble [3 × 4]> <tibble [0 × 3]>
## 4 <split [75/25]> Fold4 <tibble [3 × 4]> <tibble [0 × 3]>## # A tibble: 3 × 6
## .metric .estimator mean n std_err .config
## <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 accuracy multiclass 0.95 4 0.0191 Preprocessor1_Model1
## 2 brier_class multiclass 0.0503 4 0.0178 Preprocessor1_Model1
## 3 roc_auc hand_till 0.964 4 0.0137 Preprocessor1_Model1The accuracy appears to be 94 percent. Often the performance will be reduced using cross validation.
5.13.4.4 Example of tuning
Nice, let’s see how this changes when we now tune a hyperparameter. We want to tune the min_n argument to tune for the minimum number of data points for each node. The arguments may vary for the engine that you are using. We need to specify this when we fit the model using the tune() function like so:
set.seed(122)
library(tune)
cat_model_tune <- parsnip::decision_tree(min_n = tune()) %>%
parsnip::set_mode("classification") %>%
parsnip::set_engine("rpart")
cat_model_tune## Decision Tree Model Specification (classification)
##
## Main Arguments:
## min_n = tune()
##
## Computational engine: rpartNow we can create a new workflow using the categorical recipe and the tuning model:
iris_cat_wflow_tune <-workflows::workflow() %>%
workflows::add_recipe(cat_recipe) %>%
workflows::add_model(cat_model_tune)We can use the tune_grid() function of the tune() package to use the workflow and fit the vfold_iris cross validation samples of our training data to test out a number of different values for the min_n argument for our model. The grid() argument specifies how many different values to try out.
Again we can use the collect_metrics() function to get the accuracy. Or, we can use the show_best() function of the tune package to see the min_n values for the top performing models (those with the highest accuracy).
## # A tibble: 3 × 6
## .metric .estimator mean n std_err .config
## <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 accuracy multiclass 0.95 4 0.0191 Preprocessor1_Model1
## 2 brier_class multiclass 0.0503 4 0.0178 Preprocessor1_Model1
## 3 roc_auc hand_till 0.964 4 0.0137 Preprocessor1_Model1## # A tibble: 1 × 6
## .metric .estimator mean n std_err .config
## <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 accuracy multiclass 0.95 4 0.0191 Preprocessor1_Model15.14 Case Studies
Now we will demonstrate a more involved example with a case study.
5.14.1 Case Study #1: Predicting Annual Air Pollution
A variety of different sources contribute different types of pollutants to what we call air pollution.
- Gaseous - Carbon Monoxide (CO), Ozone (O3), Nitrogen Oxides(NO, NO2), Sulfur Dioxide (SO2)
- Particulate - small liquids and solids suspended in the air (includes lead- can include certain types of dust)
- Dust - small solids (larger than particulates) that can be suspended in the air for some time but eventually settle
- Biological - pollen, bacteria, viruses, mold spores
Air pollution particulates are generally described by their size.
There are 3 major categories:
Large Coarse Particulate Matter - has diameter of >10 micrometers (10 µm)
Coarse Particulate Matter (called PM10-2.5) - has diameter of between 2.5 µm and 10 µm
Fine Particulate Matter (called PM2.5) - has diameter of < 2.5 µm
PM10 includes any particulate matter <10 µm (both coarse and fine particulate matter)
Of these different sizes, fine particulate matter air pollution is the most associated with health risk.
In this case study, we will use fine particulate matter air pollution monitor data from gravimetric monitors ] operated by the US Enivornmental Protection Agency (EPA).
Roughly 90% of these monitors are located within cities. Hence, there is limited data about air pollution levels of more rural areas.
To get a better sense of the pollution exposures for the individuals living in these areas, methods like machine learning can be useful to estimate air pollution levels in areas with little to no monitoring.
We will use data like population density, road density, among other features, to build a model to predict the known monitored fine particulate air pollution levels. Such a model can then be used to estimate levels of pollution in places with poor monitoring.
5.14.1.1 The Data
There are 48 predictors with values for 876 monitors (observations).
The data comes from the US Environmental Protection Agency (EPA), the National Aeronautics and Space Administration (NASA), the US Census, and the National Center for Health Statistics (NCHS).
Click here to see a table about the set of features
| Variable | Details |
|---|---|
| id | Monitor number – the county number is indicated before the decimal – the monitor number is indicated after the decimal Example: 1073.0023 is Jefferson county (1073) and .0023 one of 8 monitors |
| fips | Federal information processing standard number for the county where the monitor is located – 5 digit id code for counties (zero is often the first value and sometimes is not shown) – the first 2 numbers indicate the state – the last three numbers indicate the county Example: Alabama’s state code is 01 because it is first alphabetically (note: Alaska and Hawaii are not included because they are not part of the contiguous US) |
| Lat | Latitude of the monitor in degrees |
| Lon | Longitude of the monitor in degrees |
| state | State where the monitor is located |
| county | County where the monitor is located |
| city | City where the monitor is located |
| CMAQ | Estimated values of air pollution from a computational model called Community Multiscale Air Quality (CMAQ) – A monitoring system that simulates the physics of the atmosphere using chemistry and weather data to predict the air pollution – Does not use any of the PM2.5 gravimetric monitoring data. (There is a version that does use the gravimetric monitoring data, but not this one!) – Data from the EPA |
| zcta | Zip Code Tabulation Area where the monitor is located – Postal Zip codes are converted into “generalized areal representations” that are non-overlapping – Data from the 2010 Census |
| zcta_area | Land area of the zip code area in meters squared – Data from the 2010 Census |
| zcta_pop | Population in the zip code area – Data from the 2010 Census |
| imp_a500 | Impervious surface measure – Within a circle with a radius of 500 meters around the monitor – Impervious surface are roads, concrete, parking lots, buildings – This is a measure of development |
| imp_a1000 | Impervious surface measure – Within a circle with a radius of 1000 meters around the monitor |
| imp_a5000 | Impervious surface measure – Within a circle with a radius of 5000 meters around the monitor |
| imp_a10000 | Impervious surface measure – Within a circle with a radius of 10000 meters around the monitor |
| imp_a15000 | Impervious surface measure – Within a circle with a radius of 15000 meters around the monitor |
| county_area | Land area of the county of the monitor in meters squared |
| county_pop | Population of the county of the monitor |
| Log_dist_to_prisec | Log (Natural log) distance to a primary or secondary road from the monitor – Highway or major road |
| log_pri_length_5000 | Count of primary road length in meters in a circle with a radius of 5000 meters around the monitor (Natural log) – Highways only |
| log_pri_length_10000 | Count of primary road length in meters in a circle with a radius of 10000 meters around the monitor (Natural log) – Highways only |
| log_pri_length_15000 | Count of primary road length in meters in a circle with a radius of 15000 meters around the monitor (Natural log) – Highways only |
| log_pri_length_25000 | Count of primary road length in meters in a circle with a radius of 25000 meters around the monitor (Natural log) – Highways only |
| log_prisec_length_500 | Count of primary and secondary road length in meters in a circle with a radius of 500 meters around the monitor (Natural log) – Highway and secondary roads |
| log_prisec_length_1000 | Count of primary and secondary road length in meters in a circle with a radius of 1000 meters around the monitor (Natural log) – Highway and secondary roads |
| log_prisec_length_5000 | Count of primary and secondary road length in meters in a circle with a radius of 5000 meters around the monitor (Natural log) – Highway and secondary roads |
| log_prisec_length_10000 | Count of primary and secondary road length in meters in a circle with a radius of 10000 meters around the monitor (Natural log) – Highway and secondary roads |
| log_prisec_length_15000 | Count of primary and secondary road length in meters in a circle with a radius of 15000 meters around the monitor (Natural log) – Highway and secondary roads |
| log_prisec_length_25000 | Count of primary and secondary road length in meters in a circle with a radius of 25000 meters around the monitor (Natural log) – Highway and secondary roads |
| log_nei_2008_pm25_sum_10000 | Tons of emissions from major sources data base (annual data) sum of all sources within a circle with a radius of 10000 meters of distance around the monitor (Natural log) |
| log_nei_2008_pm25_sum_15000 | Tons of emissions from major sources data base (annual data) sum of all sources within a circle with a radius of 15000 meters of distance around the monitor (Natural log) |
| log_nei_2008_pm25_sum_25000 | Tons of emissions from major sources data base (annual data) sum of all sources within a circle with a radius of 25000 meters of distance around the monitor (Natural log) |
| log_nei_2008_pm10_sum_10000 | Tons of emissions from major sources data base (annual data) sum of all sources within a circle with a radius of 10000 meters of distance around the monitor (Natural log) |
| log_nei_2008_pm10_sum_15000 | Tons of emissions from major sources data base (annual data) sum of all sources within a circle with a radius of 15000 meters of distance around the monitor (Natural log) |
| log_nei_2008_pm10_sum_25000 | Tons of emissions from major sources data base (annual data) sum of all sources within a circle with a radius of 25000 meters of distance around the monitor (Natural log) |
| popdens_county | Population density (number of people per kilometer squared area of the county) |
| popdens_zcta | Population density (number of people per kilometer squared area of zcta) |
| nohs | Percentage of people in zcta area where the monitor is that do not have a high school degree – Data from the Census |
| somehs | Percentage of people in zcta area where the monitor whose highest formal educational attainment was some high school education – Data from the Census |
| hs | Percentage of people in zcta area where the monitor whose highest formal educational attainment was completing a high school degree – Data from the Census |
| somecollege | Percentage of people in zcta area where the monitor whose highest formal educational attainment was completing some college education – Data from the Census |
| associate | Percentage of people in zcta area where the monitor whose highest formal educational attainment was completing an associate degree – Data from the Census |
| bachelor | Percentage of people in zcta area where the monitor whose highest formal educational attainment was a bachelor’s degree – Data from the Census |
| grad | Percentage of people in zcta area where the monitor whose highest formal educational attainment was a graduate degree – Data from the Census |
| pov | Percentage of people in zcta area where the monitor is that lived in poverty in 2008 – Data from the Census |
| hs_orless | Percentage of people in zcta area where the monitor whose highest formal educational attainment was a high school degree or less (sum of nohs, somehs, and hs) |
| urc2013 | 2013 Urban-rural classification of the county where the monitor is located – 6 category variable - 1 is totally urban 6 is completely rural – Data from the National Center for Health Statistics |
| urc2006 | 2006 Urban-rural classification of the county where the monitor is located – 6 category variable - 1 is totally urban 6 is completely rural – Data from the National Center for Health Statistics |
| aod | Aerosol Optical Depth measurement from a NASA satellite – based on the diffraction of a laser – used as a proxy of particulate pollution – unit-less - higher value indicates more pollution – Data from NASA |
Many of these features have to do with the circular area around the monitor called the “buffer”, but you don’t need to worry much about this.
5.14.1.2 Data Import
We have one CSV file that contains both our single outcome variable and all of our features (or predictor variables).
Next, we import our data into R now so that we can explore the data further.
We will call our data object pm for particulate matter.
We import the data using the read_csv() function from the readr package.
## here() starts at /Users/carriewright/Documents/GitHub/Coursera/tidyversecourse## Rows: 876 Columns: 50## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (3): state, county, city
## dbl (47): id, value, fips, lat, lon, CMAQ, zcta, zcta_area, zcta_pop, imp_a5...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.5.14.1.3 Data Exploration and Wrangling
First, let’s just get a general sense of our data.
## Rows: 876
## Columns: 50
## $ id <dbl> 1003.001, 1027.000, 1033.100, 1049.100, 10…
## $ value <dbl> 9.597647, 10.800000, 11.212174, 11.659091,…
## $ fips <dbl> 1003, 1027, 1033, 1049, 1055, 1069, 1073, …
## $ lat <dbl> 30.49800, 33.28126, 34.75878, 34.28763, 33…
## $ lon <dbl> -87.88141, -85.80218, -87.65056, -85.96830…
## $ state <chr> "Alabama", "Alabama", "Alabama", "Alabama"…
## $ county <chr> "Baldwin", "Clay", "Colbert", "DeKalb", "E…
## $ city <chr> "Fairhope", "Ashland", "Muscle Shoals", "C…
## $ CMAQ <dbl> 8.098836, 9.766208, 9.402679, 8.534772, 9.…
## $ zcta <dbl> 36532, 36251, 35660, 35962, 35901, 36303, …
## $ zcta_area <dbl> 190980522, 374132430, 16716984, 203836235,…
## $ zcta_pop <dbl> 27829, 5103, 9042, 8300, 20045, 30217, 901…
## $ imp_a500 <dbl> 0.01730104, 1.96972318, 19.17301038, 5.782…
## $ imp_a1000 <dbl> 1.4096021, 0.8531574, 11.1448962, 3.867647…
## $ imp_a5000 <dbl> 3.3360118, 0.9851479, 15.1786154, 1.231141…
## $ imp_a10000 <dbl> 1.9879187, 0.5208189, 9.7253870, 1.0316469…
## $ imp_a15000 <dbl> 1.4386207, 0.3359198, 5.2472094, 0.9730444…
## $ county_area <dbl> 4117521611, 1564252280, 1534877333, 201266…
## $ county_pop <dbl> 182265, 13932, 54428, 71109, 104430, 10154…
## $ log_dist_to_prisec <dbl> 4.648181, 7.219907, 5.760131, 3.721489, 5.…
## $ log_pri_length_5000 <dbl> 8.517193, 8.517193, 8.517193, 8.517193, 9.…
## $ log_pri_length_10000 <dbl> 9.210340, 9.210340, 9.274303, 10.409411, 1…
## $ log_pri_length_15000 <dbl> 9.630228, 9.615805, 9.658899, 11.173626, 1…
## $ log_pri_length_25000 <dbl> 11.32735, 10.12663, 10.15769, 11.90959, 12…
## $ log_prisec_length_500 <dbl> 7.295356, 6.214608, 8.611945, 7.310155, 8.…
## $ log_prisec_length_1000 <dbl> 8.195119, 7.600902, 9.735569, 8.585843, 9.…
## $ log_prisec_length_5000 <dbl> 10.815042, 10.170878, 11.770407, 10.214200…
## $ log_prisec_length_10000 <dbl> 11.88680, 11.40554, 12.84066, 11.50894, 12…
## $ log_prisec_length_15000 <dbl> 12.205723, 12.042963, 13.282656, 12.353663…
## $ log_prisec_length_25000 <dbl> 13.41395, 12.79980, 13.79973, 13.55979, 13…
## $ log_nei_2008_pm25_sum_10000 <dbl> 0.318035438, 3.218632928, 6.573127301, 0.0…
## $ log_nei_2008_pm25_sum_15000 <dbl> 1.967358961, 3.218632928, 6.581917457, 3.2…
## $ log_nei_2008_pm25_sum_25000 <dbl> 5.067308, 3.218633, 6.875900, 4.887665, 4.…
## $ log_nei_2008_pm10_sum_10000 <dbl> 1.35588511, 3.31111648, 6.69187313, 0.0000…
## $ log_nei_2008_pm10_sum_15000 <dbl> 2.26783411, 3.31111648, 6.70127741, 3.3500…
## $ log_nei_2008_pm10_sum_25000 <dbl> 5.628728, 3.311116, 7.148858, 5.171920, 4.…
## $ popdens_county <dbl> 44.265706, 8.906492, 35.460814, 35.330814,…
## $ popdens_zcta <dbl> 145.716431, 13.639555, 540.887040, 40.7189…
## $ nohs <dbl> 3.3, 11.6, 7.3, 14.3, 4.3, 5.8, 7.1, 2.7, …
## $ somehs <dbl> 4.9, 19.1, 15.8, 16.7, 13.3, 11.6, 17.1, 6…
## $ hs <dbl> 25.1, 33.9, 30.6, 35.0, 27.8, 29.8, 37.2, …
## $ somecollege <dbl> 19.7, 18.8, 20.9, 14.9, 29.2, 21.4, 23.5, …
## $ associate <dbl> 8.2, 8.0, 7.6, 5.5, 10.1, 7.9, 7.3, 8.0, 4…
## $ bachelor <dbl> 25.3, 5.5, 12.7, 7.9, 10.0, 13.7, 5.9, 17.…
## $ grad <dbl> 13.5, 3.1, 5.1, 5.8, 5.4, 9.8, 2.0, 8.7, 2…
## $ pov <dbl> 6.1, 19.5, 19.0, 13.8, 8.8, 15.6, 25.5, 7.…
## $ hs_orless <dbl> 33.3, 64.6, 53.7, 66.0, 45.4, 47.2, 61.4, …
## $ urc2013 <dbl> 4, 6, 4, 6, 4, 4, 1, 1, 1, 1, 1, 1, 1, 2, …
## $ urc2006 <dbl> 5, 6, 4, 5, 4, 4, 1, 1, 1, 1, 1, 1, 1, 2, …
## $ aod <dbl> 37.36364, 34.81818, 36.00000, 33.08333, 43…We can see that there are 876 monitors (rows) and that we have 50 total variables (columns) - one of which is the outcome variable. In this case, the outcome variable is called value.
Notice that some of the variables that we would think of as factors (or categorical data) are currently of class character as indicated by the <chr> just to the right of the column names/variable names in the glimpse() output. This means that the variable values are character strings, such as words or phrases.
The other variables are of class <dbl>, which stands for double precision which indicates that they are numeric and that they have decimal values. In contrast, one could have integer values which would not allow for decimal numbers. Here is a link for more information on double precision numeric values.
Another common data class is factor which is abbreviated like this: <fct>. A factor is something that has unique levels but there is no appreciable order to the levels. For example we can have a numeric value that is just an id that we want to be interpreted as just a unique level and not as the number that it would typically indicate. This would be useful for several of our variables:
- the monitor ID (
id) - the Federal Information Processing Standard number for the county where the monitor was located (
fips) - the zip code tabulation area (
zcta)
None of the values actually have any real numeric meaning, so we want to make sure that R does not interpret them as if they do.
So let’s convert these variables into factors.
We can do this using the across() function of the dplyr package and the as.factor() base function.
The across() function has two main arguments: (i) the columns you want to operate on and (ii) the function or list of functions to apply to each column.
##
## Attaching package: 'magrittr'## The following object is masked from 'package:purrr':
##
## set_names## The following object is masked from 'package:tidyr':
##
## extract## Rows: 876
## Columns: 50
## $ id <fct> 1003.001, 1027.0001, 1033.1002, 1049.1003,…
## $ value <dbl> 9.597647, 10.800000, 11.212174, 11.659091,…
## $ fips <fct> 1003, 1027, 1033, 1049, 1055, 1069, 1073, …
## $ lat <dbl> 30.49800, 33.28126, 34.75878, 34.28763, 33…
## $ lon <dbl> -87.88141, -85.80218, -87.65056, -85.96830…
## $ state <chr> "Alabama", "Alabama", "Alabama", "Alabama"…
## $ county <chr> "Baldwin", "Clay", "Colbert", "DeKalb", "E…
## $ city <chr> "Fairhope", "Ashland", "Muscle Shoals", "C…
## $ CMAQ <dbl> 8.098836, 9.766208, 9.402679, 8.534772, 9.…
## $ zcta <fct> 36532, 36251, 35660, 35962, 35901, 36303, …
## $ zcta_area <dbl> 190980522, 374132430, 16716984, 203836235,…
## $ zcta_pop <dbl> 27829, 5103, 9042, 8300, 20045, 30217, 901…
## $ imp_a500 <dbl> 0.01730104, 1.96972318, 19.17301038, 5.782…
## $ imp_a1000 <dbl> 1.4096021, 0.8531574, 11.1448962, 3.867647…
## $ imp_a5000 <dbl> 3.3360118, 0.9851479, 15.1786154, 1.231141…
## $ imp_a10000 <dbl> 1.9879187, 0.5208189, 9.7253870, 1.0316469…
## $ imp_a15000 <dbl> 1.4386207, 0.3359198, 5.2472094, 0.9730444…
## $ county_area <dbl> 4117521611, 1564252280, 1534877333, 201266…
## $ county_pop <dbl> 182265, 13932, 54428, 71109, 104430, 10154…
## $ log_dist_to_prisec <dbl> 4.648181, 7.219907, 5.760131, 3.721489, 5.…
## $ log_pri_length_5000 <dbl> 8.517193, 8.517193, 8.517193, 8.517193, 9.…
## $ log_pri_length_10000 <dbl> 9.210340, 9.210340, 9.274303, 10.409411, 1…
## $ log_pri_length_15000 <dbl> 9.630228, 9.615805, 9.658899, 11.173626, 1…
## $ log_pri_length_25000 <dbl> 11.32735, 10.12663, 10.15769, 11.90959, 12…
## $ log_prisec_length_500 <dbl> 7.295356, 6.214608, 8.611945, 7.310155, 8.…
## $ log_prisec_length_1000 <dbl> 8.195119, 7.600902, 9.735569, 8.585843, 9.…
## $ log_prisec_length_5000 <dbl> 10.815042, 10.170878, 11.770407, 10.214200…
## $ log_prisec_length_10000 <dbl> 11.88680, 11.40554, 12.84066, 11.50894, 12…
## $ log_prisec_length_15000 <dbl> 12.205723, 12.042963, 13.282656, 12.353663…
## $ log_prisec_length_25000 <dbl> 13.41395, 12.79980, 13.79973, 13.55979, 13…
## $ log_nei_2008_pm25_sum_10000 <dbl> 0.318035438, 3.218632928, 6.573127301, 0.0…
## $ log_nei_2008_pm25_sum_15000 <dbl> 1.967358961, 3.218632928, 6.581917457, 3.2…
## $ log_nei_2008_pm25_sum_25000 <dbl> 5.067308, 3.218633, 6.875900, 4.887665, 4.…
## $ log_nei_2008_pm10_sum_10000 <dbl> 1.35588511, 3.31111648, 6.69187313, 0.0000…
## $ log_nei_2008_pm10_sum_15000 <dbl> 2.26783411, 3.31111648, 6.70127741, 3.3500…
## $ log_nei_2008_pm10_sum_25000 <dbl> 5.628728, 3.311116, 7.148858, 5.171920, 4.…
## $ popdens_county <dbl> 44.265706, 8.906492, 35.460814, 35.330814,…
## $ popdens_zcta <dbl> 145.716431, 13.639555, 540.887040, 40.7189…
## $ nohs <dbl> 3.3, 11.6, 7.3, 14.3, 4.3, 5.8, 7.1, 2.7, …
## $ somehs <dbl> 4.9, 19.1, 15.8, 16.7, 13.3, 11.6, 17.1, 6…
## $ hs <dbl> 25.1, 33.9, 30.6, 35.0, 27.8, 29.8, 37.2, …
## $ somecollege <dbl> 19.7, 18.8, 20.9, 14.9, 29.2, 21.4, 23.5, …
## $ associate <dbl> 8.2, 8.0, 7.6, 5.5, 10.1, 7.9, 7.3, 8.0, 4…
## $ bachelor <dbl> 25.3, 5.5, 12.7, 7.9, 10.0, 13.7, 5.9, 17.…
## $ grad <dbl> 13.5, 3.1, 5.1, 5.8, 5.4, 9.8, 2.0, 8.7, 2…
## $ pov <dbl> 6.1, 19.5, 19.0, 13.8, 8.8, 15.6, 25.5, 7.…
## $ hs_orless <dbl> 33.3, 64.6, 53.7, 66.0, 45.4, 47.2, 61.4, …
## $ urc2013 <dbl> 4, 6, 4, 6, 4, 4, 1, 1, 1, 1, 1, 1, 1, 2, …
## $ urc2006 <dbl> 5, 6, 4, 5, 4, 4, 1, 1, 1, 1, 1, 1, 1, 2, …
## $ aod <dbl> 37.36364, 34.81818, 36.00000, 33.08333, 43…Great! Now we can see that these variables are now factors as indicated by <fct> after the variable name.
The skim() function of the skimr package is also really helpful for getting a general sense of your data.
By design, it provides summary statistics about variables in the dataset.
| Name | pm |
| Number of rows | 876 |
| Number of columns | 50 |
| _______________________ | |
| Column type frequency: | |
| character | 3 |
| factor | 3 |
| numeric | 44 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| state | 0 | 1 | 4 | 20 | 0 | 49 | 0 |
| county | 0 | 1 | 3 | 20 | 0 | 471 | 0 |
| city | 0 | 1 | 4 | 48 | 0 | 607 | 0 |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| id | 0 | 1 | FALSE | 876 | 100: 1, 102: 1, 103: 1, 104: 1 |
| fips | 0 | 1 | FALSE | 569 | 170: 12, 603: 10, 261: 9, 107: 8 |
| zcta | 0 | 1 | FALSE | 842 | 475: 3, 110: 2, 160: 2, 290: 2 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| value | 0 | 1 | 10.81 | 2.580000e+00 | 3.02 | 9.27 | 11.15 | 12.37 | 2.316000e+01 | ▂▆▇▁▁ |
| lat | 0 | 1 | 38.48 | 4.620000e+00 | 25.47 | 35.03 | 39.30 | 41.66 | 4.840000e+01 | ▁▃▅▇▂ |
| lon | 0 | 1 | -91.74 | 1.496000e+01 | -124.18 | -99.16 | -87.47 | -80.69 | -6.804000e+01 | ▃▂▃▇▃ |
| CMAQ | 0 | 1 | 8.41 | 2.970000e+00 | 1.63 | 6.53 | 8.62 | 10.24 | 2.313000e+01 | ▃▇▃▁▁ |
| zcta_area | 0 | 1 | 183173481.91 | 5.425989e+08 | 15459.00 | 14204601.75 | 37653560.50 | 160041508.25 | 8.164821e+09 | ▇▁▁▁▁ |
| zcta_pop | 0 | 1 | 24227.58 | 1.777216e+04 | 0.00 | 9797.00 | 22014.00 | 35004.75 | 9.539700e+04 | ▇▇▃▁▁ |
| imp_a500 | 0 | 1 | 24.72 | 1.934000e+01 | 0.00 | 3.70 | 25.12 | 40.22 | 6.961000e+01 | ▇▅▆▃▂ |
| imp_a1000 | 0 | 1 | 24.26 | 1.802000e+01 | 0.00 | 5.32 | 24.53 | 38.59 | 6.750000e+01 | ▇▅▆▃▁ |
| imp_a5000 | 0 | 1 | 19.93 | 1.472000e+01 | 0.05 | 6.79 | 19.07 | 30.11 | 7.460000e+01 | ▇▆▃▁▁ |
| imp_a10000 | 0 | 1 | 15.82 | 1.381000e+01 | 0.09 | 4.54 | 12.36 | 24.17 | 7.209000e+01 | ▇▃▂▁▁ |
| imp_a15000 | 0 | 1 | 13.43 | 1.312000e+01 | 0.11 | 3.24 | 9.67 | 20.55 | 7.110000e+01 | ▇▃▁▁▁ |
| county_area | 0 | 1 | 3768701992.12 | 6.212830e+09 | 33703512.00 | 1116536297.50 | 1690826566.50 | 2878192209.00 | 5.194723e+10 | ▇▁▁▁▁ |
| county_pop | 0 | 1 | 687298.44 | 1.293489e+06 | 783.00 | 100948.00 | 280730.50 | 743159.00 | 9.818605e+06 | ▇▁▁▁▁ |
| log_dist_to_prisec | 0 | 1 | 6.19 | 1.410000e+00 | -1.46 | 5.43 | 6.36 | 7.15 | 1.045000e+01 | ▁▁▃▇▁ |
| log_pri_length_5000 | 0 | 1 | 9.82 | 1.080000e+00 | 8.52 | 8.52 | 10.05 | 10.73 | 1.205000e+01 | ▇▂▆▅▂ |
| log_pri_length_10000 | 0 | 1 | 10.92 | 1.130000e+00 | 9.21 | 9.80 | 11.17 | 11.83 | 1.302000e+01 | ▇▂▇▇▃ |
| log_pri_length_15000 | 0 | 1 | 11.50 | 1.150000e+00 | 9.62 | 10.87 | 11.72 | 12.40 | 1.359000e+01 | ▆▂▇▇▃ |
| log_pri_length_25000 | 0 | 1 | 12.24 | 1.100000e+00 | 10.13 | 11.69 | 12.46 | 13.05 | 1.436000e+01 | ▅▃▇▇▃ |
| log_prisec_length_500 | 0 | 1 | 6.99 | 9.500000e-01 | 6.21 | 6.21 | 6.21 | 7.82 | 9.400000e+00 | ▇▁▂▂▁ |
| log_prisec_length_1000 | 0 | 1 | 8.56 | 7.900000e-01 | 7.60 | 7.60 | 8.66 | 9.20 | 1.047000e+01 | ▇▅▆▃▁ |
| log_prisec_length_5000 | 0 | 1 | 11.28 | 7.800000e-01 | 8.52 | 10.91 | 11.42 | 11.83 | 1.278000e+01 | ▁▁▃▇▃ |
| log_prisec_length_10000 | 0 | 1 | 12.41 | 7.300000e-01 | 9.21 | 11.99 | 12.53 | 12.94 | 1.385000e+01 | ▁▁▃▇▅ |
| log_prisec_length_15000 | 0 | 1 | 13.03 | 7.200000e-01 | 9.62 | 12.59 | 13.13 | 13.57 | 1.441000e+01 | ▁▁▃▇▅ |
| log_prisec_length_25000 | 0 | 1 | 13.82 | 7.000000e-01 | 10.13 | 13.38 | 13.92 | 14.35 | 1.523000e+01 | ▁▁▃▇▆ |
| log_nei_2008_pm25_sum_10000 | 0 | 1 | 3.97 | 2.350000e+00 | 0.00 | 2.15 | 4.29 | 5.69 | 9.120000e+00 | ▆▅▇▆▂ |
| log_nei_2008_pm25_sum_15000 | 0 | 1 | 4.72 | 2.250000e+00 | 0.00 | 3.47 | 5.00 | 6.35 | 9.420000e+00 | ▃▃▇▇▂ |
| log_nei_2008_pm25_sum_25000 | 0 | 1 | 5.67 | 2.110000e+00 | 0.00 | 4.66 | 5.91 | 7.28 | 9.650000e+00 | ▂▂▇▇▃ |
| log_nei_2008_pm10_sum_10000 | 0 | 1 | 4.35 | 2.320000e+00 | 0.00 | 2.69 | 4.62 | 6.07 | 9.340000e+00 | ▅▅▇▇▂ |
| log_nei_2008_pm10_sum_15000 | 0 | 1 | 5.10 | 2.180000e+00 | 0.00 | 3.87 | 5.39 | 6.72 | 9.710000e+00 | ▂▃▇▇▂ |
| log_nei_2008_pm10_sum_25000 | 0 | 1 | 6.07 | 2.010000e+00 | 0.00 | 5.10 | 6.37 | 7.52 | 9.880000e+00 | ▁▂▆▇▃ |
| popdens_county | 0 | 1 | 551.76 | 1.711510e+03 | 0.26 | 40.77 | 156.67 | 510.81 | 2.682191e+04 | ▇▁▁▁▁ |
| popdens_zcta | 0 | 1 | 1279.66 | 2.757490e+03 | 0.00 | 101.15 | 610.35 | 1382.52 | 3.041884e+04 | ▇▁▁▁▁ |
| nohs | 0 | 1 | 6.99 | 7.210000e+00 | 0.00 | 2.70 | 5.10 | 8.80 | 1.000000e+02 | ▇▁▁▁▁ |
| somehs | 0 | 1 | 10.17 | 6.200000e+00 | 0.00 | 5.90 | 9.40 | 13.90 | 7.220000e+01 | ▇▂▁▁▁ |
| hs | 0 | 1 | 30.32 | 1.140000e+01 | 0.00 | 23.80 | 30.75 | 36.10 | 1.000000e+02 | ▂▇▂▁▁ |
| somecollege | 0 | 1 | 21.58 | 8.600000e+00 | 0.00 | 17.50 | 21.30 | 24.70 | 1.000000e+02 | ▆▇▁▁▁ |
| associate | 0 | 1 | 7.13 | 4.010000e+00 | 0.00 | 4.90 | 7.10 | 8.80 | 7.140000e+01 | ▇▁▁▁▁ |
| bachelor | 0 | 1 | 14.90 | 9.710000e+00 | 0.00 | 8.80 | 12.95 | 19.22 | 1.000000e+02 | ▇▂▁▁▁ |
| grad | 0 | 1 | 8.91 | 8.650000e+00 | 0.00 | 3.90 | 6.70 | 11.00 | 1.000000e+02 | ▇▁▁▁▁ |
| pov | 0 | 1 | 14.95 | 1.133000e+01 | 0.00 | 6.50 | 12.10 | 21.22 | 6.590000e+01 | ▇▅▂▁▁ |
| hs_orless | 0 | 1 | 47.48 | 1.675000e+01 | 0.00 | 37.92 | 48.65 | 59.10 | 1.000000e+02 | ▁▃▇▃▁ |
| urc2013 | 0 | 1 | 2.92 | 1.520000e+00 | 1.00 | 2.00 | 3.00 | 4.00 | 6.000000e+00 | ▇▅▃▂▁ |
| urc2006 | 0 | 1 | 2.97 | 1.520000e+00 | 1.00 | 2.00 | 3.00 | 4.00 | 6.000000e+00 | ▇▅▃▂▁ |
| aod | 0 | 1 | 43.70 | 1.956000e+01 | 5.00 | 31.66 | 40.17 | 49.67 | 1.430000e+02 | ▃▇▁▁▁ |
Notice how there is a column called n_missing about the number of values that are missing.
This is also indicated by the complete_rate variable (or missing/number of observations).
In our dataset, it looks like our data do not contain any missing data.
Also notice how the function provides separate tables of summary statistics for each data type: character, factor and numeric.
Next, the n_unique column shows us the number of unique values for each of our columns.
We can see that there are 49 states represented in the data.
We can see that for many variables there are many low values as the distribution shows two peaks, one near zero and another with a higher value.
This is true for the imp variables (measures of development), the nei variables (measures of emission sources) and the road density variables.
We can also see that the range of some of the variables is very large, in particular the area and population related variables.
Let’s take a look to see which states are included using the distinct() function of the dplyr package:
## # A tibble: 49 × 1
## state
## <chr>
## 1 Alabama
## 2 Arizona
## 3 Arkansas
## 4 California
## 5 Colorado
## 6 Connecticut
## 7 Delaware
## 8 District Of Columbia
## 9 Florida
## 10 Georgia
## # ℹ 39 more rows5.14.1.4 Evaluate Correlation
In prediction analyses, it is also useful to evaluate if any of the variables are correlated. Why should we care about this?
If we are using a linear regression to model our data then we might run into a problem called multicollinearity which can lead us to misinterpret what is really predictive of our outcome variable. This phenomenon occurs when the predictor variables actually predict one another.
Another reason we should look out for correlation is that we don’t want to include redundant variables. This can add unnecessary noise to our algorithm causing a reduction in prediction accuracy and it can cause our algorithm to be unnecessarily slower. Finally, it can also make it difficult to interpret what variables are actually predictive.
Intuitively we can expect some of our variables to be correlated.
The corrplot package is another option to look at correlation among possible predictors, and particularly useful if we have many predictors.
First, we calculate the Pearson correlation coefficients between all features pairwise using the cor() function of the stats package (which is loaded automatically). Then we use the corrplot::corrplot() function. First we need to select only the numeric variables using dplyr.
## corrplot 0.95 loaded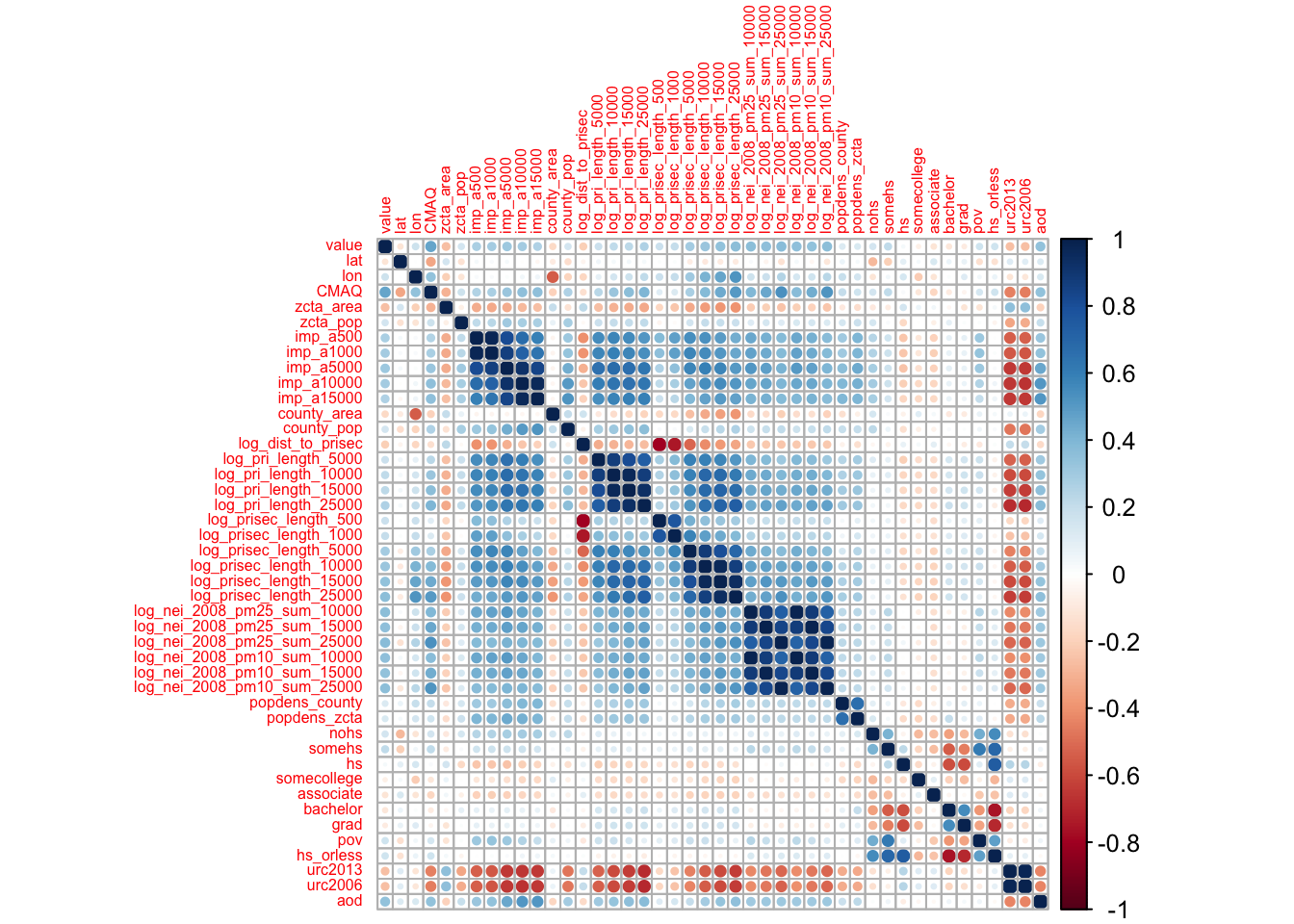
We can see that the development variables (imp) variables are correlated with each other as we might expect.
We also see that the road density variables seem to be correlated with each other, and the emission variables seem to be correlated with each other.
Also notice that none of the predictors are highly correlated with our outcome variable (value).
Now that we have a sense of what our data are, we can get started with building a machine learning model to predict air pollution.
5.14.1.5 Splitting the Data
## ── Attaching packages ────────────────────────────────────── tidymodels 1.3.0 ──## ✔ dials 1.4.0 ✔ workflowsets 1.1.0
## ✔ modeldata 1.4.0 ✔ yardstick 1.3.2## ── Conflicts ───────────────────────────────────────── tidymodels_conflicts() ──
## ✖ scales::discard() masks purrr::discard()
## ✖ magrittr::extract() masks tidyr::extract()
## ✖ dplyr::filter() masks stats::filter()
## ✖ xts::first() masks dplyr::first()
## ✖ recipes::fixed() masks stringr::fixed()
## ✖ dplyr::lag() masks stats::lag()
## ✖ xts::last() masks dplyr::last()
## ✖ dials::prune() masks rpart::prune()
## ✖ magrittr::set_names() masks purrr::set_names()
## ✖ yardstick::spec() masks readr::spec()
## ✖ recipes::step() masks stats::step()## <Training/Testing/Total>
## <584/292/876>We can see the number of monitors in our training, testing, and original data by typing in the name of our split object. The result will look like this: <training data sample number, testing data sample number, original sample number>
Importantly the initial_split() function only determines what rows of our pm dataframe should be assigned for training or testing, it does not actually split the data.
To extract the testing and training data we can use the training() and testing() functions also of the rsample package.
Great!
Now let’s make a recipe!
5.14.1.6 Making a Recipe
Now with our data, we will start by making a recipe for our training data.
If you recall, the continuous outcome variable is value (the average annual gravimetric monitor PM2.5 concentration in ug/m3).
Our features (or predictor variables) are all the other variables except the monitor ID, which is an id variable.
The reason not to include the id variable is because this variable includes the county number and a number designating which particular monitor the values came from (of the monitors there are in that county).
Since this number is arbitrary and the county information is also given in the data, and the fact that each monitor only has one value in the value variable, nothing is gained by including this variable and it may instead introduce noise.
However, it is useful to keep this data to take a look at what is happening later.
We will show you what to do in this case in just a bit.
In the simplest case, we might use all predictors like this:
#install.packages(tidymodels)
library(tidymodels)
simple_rec <- train_pm %>%
recipes::recipe(value ~ .)
simple_rec## ## ── Recipe ──────────────────────────────────────────────────────────────────────## ## ── Inputs## Number of variables by role## outcome: 1
## predictor: 49Now, let’s get back to the id variable.
Instead of including it as a predictor variable, we could also use the update_role() function of the recipes package.
simple_rec <- train_pm %>%
recipes::recipe(value ~ .) %>%
recipes::update_role(id, new_role = "id variable")
simple_rec## ## ── Recipe ──────────────────────────────────────────────────────────────────────## ## ── Inputs## Number of variables by role## outcome: 1
## predictor: 48
## id variable: 1This link and this link show the many options for recipe step functions.
All of the step functions look like step_*() with the * replaced with a name, except for the check functions which look like check_*().
There are several ways to select what variables to apply steps to:
- Using
tidyselectmethods:contains(),matches(),starts_with(),ends_with(),everything(),num_range()
- Using the type:
all_nominal(),all_numeric(),has_type() - Using the role:
all_predictors(),all_outcomes(),has_role() - Using the name - use the actual name of the variable/variables of interest
Let’s try adding some steps to our recipe.
We want to dummy encode our categorical variables so that they are numeric as we plan to use a linear regression for our model.
We will use the one-hot encoding means that we do not simply encode our categorical variables numerically, as our numeric assignments can be interpreted by algorithms as having a particular rank or order. Instead, binary variables made of 1s and 0s are used to arbitrarily assign a numeric value that has no apparent order.
## ## ── Recipe ──────────────────────────────────────────────────────────────────────## ## ── Inputs## Number of variables by role## outcome: 1
## predictor: 48
## id variable: 1## ## ── Operations## • Dummy variables from: state, county, city, zctaOur fips variable includes a numeric code for state and county - and therefore is essentially a proxy for county.
Since we already have county, we will just use it and keep the fips ID as another ID variable.
We can remove the fips variable from the predictors using update_role() to make sure that the role is no longer "predictor".
We can make the role anything we want actually, so we will keep it something identifiable.
## ## ── Recipe ──────────────────────────────────────────────────────────────────────## ## ── Inputs## Number of variables by role## outcome: 1
## predictor: 47
## county id: 1
## id variable: 1We also want to remove variables that appear to be redundant and are highly correlated with others, as we know from our exploratory data analysis that many of our variables are correlated with one another.
We can do this using the step_corr() function.
We don’t want to remove some of our variables, like the CMAQ and aod variables, we can specify this using the - sign before the names of these variables like so:
## ## ── Recipe ──────────────────────────────────────────────────────────────────────## ## ── Inputs## Number of variables by role## outcome: 1
## predictor: 48
## id variable: 1## ## ── Operations## • Correlation filter on: all_predictors(), -CMAQ, -aodIt is also a good idea to remove variables with near-zero variance, which can be done with the step_nzv() function.
Variables have low variance if all the values are very similar, the values are very sparse, or if they are highly imbalanced. Again we don’t want to remove our CMAQ and aod variables.
## ## ── Recipe ──────────────────────────────────────────────────────────────────────## ## ── Inputs## Number of variables by role## outcome: 1
## predictor: 48
## id variable: 1## ## ── Operations## • Sparse, unbalanced variable filter on: all_predictors(), -CMAQ, -aodLet’s put all this together now.
Remember: it is important to add the steps to the recipe in an order that makes sense just like with a cooking recipe.
First, we are going to create numeric values for our categorical variables, then we will look at correlation and near-zero variance.
Again, we do not want to remove the CMAQ and aod variables, so we can make sure they are kept in the model by excluding them from those steps.
If we specifically wanted to remove a predictor we could use step_rm().
simple_rec <- train_pm %>%
recipes::recipe(value ~ .) %>%
recipes::update_role(id, new_role = "id variable") %>%
update_role("fips", new_role = "county id") %>%
step_dummy(state, county, city, zcta, one_hot = TRUE) %>%
step_corr(all_predictors(), - CMAQ, - aod)%>%
step_nzv(all_predictors(), - CMAQ, - aod)
simple_rec## ## ── Recipe ──────────────────────────────────────────────────────────────────────## ## ── Inputs## Number of variables by role## outcome: 1
## predictor: 47
## county id: 1
## id variable: 1## ## ── Operations## • Dummy variables from: state, county, city, zcta## • Correlation filter on: all_predictors(), -CMAQ, -aod## • Sparse, unbalanced variable filter on: all_predictors(), -CMAQ, -aodNice! Now let’s check our preprocessing.
5.14.1.7 Running Preprocessing
First we need to use the prep() function of the recipes package to prepare for preprocessing. However, we will specify that we also want to run and retain the preprocessing for the training data using the retain = TRUE argument.
## oper 1 step dummy [training]
## oper 2 step corr [training]## Warning in stats::cor(x, use = use, method = method): the standard deviation is
## zero## Warning: The correlation matrix has missing values. 273 columns were excluded from the
## filter.## oper 3 step nzv [training]
## The retained training set is ~ 0.26 Mb in memory.## [1] "var_info" "term_info" "steps" "template"
## [5] "retained" "requirements" "ptype" "tr_info"
## [9] "orig_lvls" "fit_times" "last_term_info"Since we retained our preprocessed training data (i.e. prep(retain=TRUE)), we can take a look at it by using the bake() function of the recipes package like this (this previously used the juice() function):
## Rows: 584
## Columns: 37
## $ id <fct> 18003.0004, 55041.0007, 6065.1003, 39009.0…
## $ fips <fct> 18003, 55041, 6065, 39009, 39061, 24510, 6…
## $ lat <dbl> 41.09497, 45.56300, 33.94603, 39.44217, 39…
## $ lon <dbl> -85.10182, -88.80880, -117.40063, -81.9088…
## $ CMAQ <dbl> 10.383231, 3.411247, 11.404085, 7.971165, …
## $ zcta_area <dbl> 16696709, 370280916, 41957182, 132383592, …
## $ zcta_pop <dbl> 21306, 4141, 44001, 1115, 6566, 934, 41192…
## $ imp_a500 <dbl> 28.9783737, 0.0000000, 30.3901384, 0.00000…
## $ imp_a15000 <dbl> 13.0547959, 0.3676404, 23.7457506, 0.33079…
## $ county_area <dbl> 1702419942, 2626421270, 18664696661, 13043…
## $ county_pop <dbl> 355329, 9304, 2189641, 64757, 802374, 6209…
## $ log_dist_to_prisec <dbl> 6.621891, 8.415468, 7.419762, 6.344681, 5.…
## $ log_pri_length_5000 <dbl> 8.517193, 8.517193, 10.150514, 8.517193, 9…
## $ log_pri_length_25000 <dbl> 12.77378, 10.16440, 13.14450, 10.12663, 13…
## $ log_prisec_length_500 <dbl> 6.214608, 6.214608, 6.214608, 6.214608, 7.…
## $ log_prisec_length_1000 <dbl> 9.240294, 7.600902, 7.600902, 8.793450, 8.…
## $ log_prisec_length_5000 <dbl> 11.485093, 9.425537, 10.155961, 10.562382,…
## $ log_prisec_length_10000 <dbl> 12.75582, 11.44833, 11.59563, 11.69093, 12…
## $ log_nei_2008_pm10_sum_10000 <dbl> 4.91110140, 3.86982666, 4.03184660, 0.0000…
## $ log_nei_2008_pm10_sum_15000 <dbl> 5.399131, 3.883689, 5.459257, 0.000000, 6.…
## $ log_nei_2008_pm10_sum_25000 <dbl> 5.816047, 3.887264, 6.884537, 3.765635, 6.…
## $ popdens_county <dbl> 208.719947, 3.542463, 117.314577, 49.64834…
## $ popdens_zcta <dbl> 1276.059851, 11.183401, 1048.711994, 8.422…
## $ nohs <dbl> 4.3, 5.1, 3.7, 4.8, 2.1, 0.0, 2.5, 7.7, 0.…
## $ somehs <dbl> 6.7, 10.4, 5.9, 11.5, 10.5, 0.0, 4.3, 7.5,…
## $ hs <dbl> 31.7, 40.3, 17.9, 47.3, 30.0, 0.0, 17.8, 2…
## $ somecollege <dbl> 27.2, 24.1, 26.3, 20.0, 27.1, 0.0, 26.1, 2…
## $ associate <dbl> 8.2, 7.4, 8.3, 3.1, 8.5, 71.4, 13.2, 7.6, …
## $ bachelor <dbl> 15.0, 8.6, 20.2, 9.8, 14.2, 0.0, 23.4, 17.…
## $ grad <dbl> 6.8, 4.2, 17.7, 3.5, 7.6, 28.6, 12.6, 12.3…
## $ pov <dbl> 13.500, 18.900, 6.700, 14.400, 12.500, 3.5…
## $ hs_orless <dbl> 42.7, 55.8, 27.5, 63.6, 42.6, 0.0, 24.6, 3…
## $ urc2006 <dbl> 3, 6, 1, 5, 1, 1, 2, 1, 2, 6, 4, 4, 4, 4, …
## $ aod <dbl> 54.11111, 31.16667, 83.12500, 33.36364, 50…
## $ value <dbl> 11.699065, 6.956780, 13.289744, 10.742000,…
## $ state_California <dbl> 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, …
## $ city_Not.in.a.city <dbl> 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, …Notice that this requires the new_data = NULL argument when we are using the training data.
For easy comparison sake - here is our original data:
## Rows: 876
## Columns: 50
## $ id <fct> 1003.001, 1027.0001, 1033.1002, 1049.1003,…
## $ value <dbl> 9.597647, 10.800000, 11.212174, 11.659091,…
## $ fips <fct> 1003, 1027, 1033, 1049, 1055, 1069, 1073, …
## $ lat <dbl> 30.49800, 33.28126, 34.75878, 34.28763, 33…
## $ lon <dbl> -87.88141, -85.80218, -87.65056, -85.96830…
## $ state <chr> "Alabama", "Alabama", "Alabama", "Alabama"…
## $ county <chr> "Baldwin", "Clay", "Colbert", "DeKalb", "E…
## $ city <chr> "Fairhope", "Ashland", "Muscle Shoals", "C…
## $ CMAQ <dbl> 8.098836, 9.766208, 9.402679, 8.534772, 9.…
## $ zcta <fct> 36532, 36251, 35660, 35962, 35901, 36303, …
## $ zcta_area <dbl> 190980522, 374132430, 16716984, 203836235,…
## $ zcta_pop <dbl> 27829, 5103, 9042, 8300, 20045, 30217, 901…
## $ imp_a500 <dbl> 0.01730104, 1.96972318, 19.17301038, 5.782…
## $ imp_a1000 <dbl> 1.4096021, 0.8531574, 11.1448962, 3.867647…
## $ imp_a5000 <dbl> 3.3360118, 0.9851479, 15.1786154, 1.231141…
## $ imp_a10000 <dbl> 1.9879187, 0.5208189, 9.7253870, 1.0316469…
## $ imp_a15000 <dbl> 1.4386207, 0.3359198, 5.2472094, 0.9730444…
## $ county_area <dbl> 4117521611, 1564252280, 1534877333, 201266…
## $ county_pop <dbl> 182265, 13932, 54428, 71109, 104430, 10154…
## $ log_dist_to_prisec <dbl> 4.648181, 7.219907, 5.760131, 3.721489, 5.…
## $ log_pri_length_5000 <dbl> 8.517193, 8.517193, 8.517193, 8.517193, 9.…
## $ log_pri_length_10000 <dbl> 9.210340, 9.210340, 9.274303, 10.409411, 1…
## $ log_pri_length_15000 <dbl> 9.630228, 9.615805, 9.658899, 11.173626, 1…
## $ log_pri_length_25000 <dbl> 11.32735, 10.12663, 10.15769, 11.90959, 12…
## $ log_prisec_length_500 <dbl> 7.295356, 6.214608, 8.611945, 7.310155, 8.…
## $ log_prisec_length_1000 <dbl> 8.195119, 7.600902, 9.735569, 8.585843, 9.…
## $ log_prisec_length_5000 <dbl> 10.815042, 10.170878, 11.770407, 10.214200…
## $ log_prisec_length_10000 <dbl> 11.88680, 11.40554, 12.84066, 11.50894, 12…
## $ log_prisec_length_15000 <dbl> 12.205723, 12.042963, 13.282656, 12.353663…
## $ log_prisec_length_25000 <dbl> 13.41395, 12.79980, 13.79973, 13.55979, 13…
## $ log_nei_2008_pm25_sum_10000 <dbl> 0.318035438, 3.218632928, 6.573127301, 0.0…
## $ log_nei_2008_pm25_sum_15000 <dbl> 1.967358961, 3.218632928, 6.581917457, 3.2…
## $ log_nei_2008_pm25_sum_25000 <dbl> 5.067308, 3.218633, 6.875900, 4.887665, 4.…
## $ log_nei_2008_pm10_sum_10000 <dbl> 1.35588511, 3.31111648, 6.69187313, 0.0000…
## $ log_nei_2008_pm10_sum_15000 <dbl> 2.26783411, 3.31111648, 6.70127741, 3.3500…
## $ log_nei_2008_pm10_sum_25000 <dbl> 5.628728, 3.311116, 7.148858, 5.171920, 4.…
## $ popdens_county <dbl> 44.265706, 8.906492, 35.460814, 35.330814,…
## $ popdens_zcta <dbl> 145.716431, 13.639555, 540.887040, 40.7189…
## $ nohs <dbl> 3.3, 11.6, 7.3, 14.3, 4.3, 5.8, 7.1, 2.7, …
## $ somehs <dbl> 4.9, 19.1, 15.8, 16.7, 13.3, 11.6, 17.1, 6…
## $ hs <dbl> 25.1, 33.9, 30.6, 35.0, 27.8, 29.8, 37.2, …
## $ somecollege <dbl> 19.7, 18.8, 20.9, 14.9, 29.2, 21.4, 23.5, …
## $ associate <dbl> 8.2, 8.0, 7.6, 5.5, 10.1, 7.9, 7.3, 8.0, 4…
## $ bachelor <dbl> 25.3, 5.5, 12.7, 7.9, 10.0, 13.7, 5.9, 17.…
## $ grad <dbl> 13.5, 3.1, 5.1, 5.8, 5.4, 9.8, 2.0, 8.7, 2…
## $ pov <dbl> 6.1, 19.5, 19.0, 13.8, 8.8, 15.6, 25.5, 7.…
## $ hs_orless <dbl> 33.3, 64.6, 53.7, 66.0, 45.4, 47.2, 61.4, …
## $ urc2013 <dbl> 4, 6, 4, 6, 4, 4, 1, 1, 1, 1, 1, 1, 1, 2, …
## $ urc2006 <dbl> 5, 6, 4, 5, 4, 4, 1, 1, 1, 1, 1, 1, 1, 2, …
## $ aod <dbl> 37.36364, 34.81818, 36.00000, 33.08333, 43…Notice how we only have 36 variables now instead of 50!
Two of these are our ID variables (fips and the actual monitor ID (id)) and one is our outcome (value).
Thus we only have 33 predictors now.
We can also see that we no longer have any categorical variables.
Variables like state are gone and only state_California remains as it was the only state identity to have nonzero variance.
We can also see that there were more monitors listed as "Not in a city" than any city.
5.14.1.7.1 Extract preprocessed testing data using bake()
According to the tidymodels documentation:
bake()takes a trained recipe and applies the operations to a data set to create a design matrix. For example: it applies the centering to new data sets using these means used to create the recipe.
Therefore, if you wanted to look at the preprocessed testing data you would use the bake() function of the recipes package.
## Warning: ! There are new levels in `county`: "Colbert", "Etowah", "Russell", "Walker",
## "Cochise", "Coconino", "Mohave", "Arkansas", "Crittenden", "Garland",
## "Phillips", "Pope", "Calaveras", "Humboldt", "Inyo", "Merced", "Monterey",
## "San Benito", …, "Laramie", and "Sublette".
## ℹ Consider using step_novel() (`?recipes::step_novel()`) before `step_dummy()`
## to handle unseen values.## Warning: ! There are new levels in `city`: "Muscle Shoals", "Gadsden", "Dothan",
## "Chickasaw", "Montgomery", "Phenix City", "Douglas", "Flagstaff", "Peach
## Springs", "Apache Junction", "Stuttgart", "Hot Springs (Hot Springs National
## Park)", "Newport", "Russellville", "Springdale", "San Andreas", "Eureka", "El
## Centro", …, "Cheyenne", and "Pinedale".
## ℹ Consider using step_novel() (`?recipes::step_novel()`) before `step_dummy()`
## to handle unseen values.## Rows: 292
## Columns: 37
## $ id <fct> 1033.1002, 1055.001, 1069.0003, 1073.0023,…
## $ fips <fct> 1033, 1055, 1069, 1073, 1073, 1073, 1073, …
## $ lat <dbl> 34.75878, 33.99375, 31.22636, 33.55306, 33…
## $ lon <dbl> -87.65056, -85.99107, -85.39077, -86.81500…
## $ CMAQ <dbl> 9.402679, 9.241744, 9.121892, 10.235612, 1…
## $ zcta_area <dbl> 16716984, 154069359, 162685124, 26929603, …
## $ zcta_pop <dbl> 9042, 20045, 30217, 9010, 16140, 3699, 137…
## $ imp_a500 <dbl> 19.17301038, 16.49307958, 19.13927336, 41.…
## $ imp_a15000 <dbl> 5.2472094, 5.1612102, 4.7401296, 17.452484…
## $ county_area <dbl> 1534877333, 1385618994, 1501737720, 287819…
## $ county_pop <dbl> 54428, 104430, 101547, 658466, 658466, 194…
## $ log_dist_to_prisec <dbl> 5.760131, 5.261457, 7.112373, 6.600958, 6.…
## $ log_pri_length_5000 <dbl> 8.517193, 9.066563, 8.517193, 11.156977, 1…
## $ log_pri_length_25000 <dbl> 10.15769, 12.01356, 10.12663, 12.98762, 12…
## $ log_prisec_length_500 <dbl> 8.611945, 8.740680, 6.214608, 6.214608, 6.…
## $ log_prisec_length_1000 <dbl> 9.735569, 9.627898, 7.600902, 9.075921, 8.…
## $ log_prisec_length_5000 <dbl> 11.770407, 11.728889, 12.298627, 12.281645…
## $ log_prisec_length_10000 <dbl> 12.840663, 12.768279, 12.994141, 13.278416…
## $ log_nei_2008_pm10_sum_10000 <dbl> 6.69187313, 4.43719884, 0.92888890, 8.2097…
## $ log_nei_2008_pm10_sum_15000 <dbl> 6.70127741, 4.46267932, 3.67473904, 8.6488…
## $ log_nei_2008_pm10_sum_25000 <dbl> 7.148858, 4.678311, 3.744629, 8.858019, 8.…
## $ popdens_county <dbl> 35.460814, 75.367038, 67.619664, 228.77763…
## $ popdens_zcta <dbl> 540.8870404, 130.1037411, 185.7391706, 334…
## $ nohs <dbl> 7.3, 4.3, 5.8, 7.1, 2.7, 11.1, 9.7, 3.0, 8…
## $ somehs <dbl> 15.8, 13.3, 11.6, 17.1, 6.6, 11.6, 21.6, 1…
## $ hs <dbl> 30.6, 27.8, 29.8, 37.2, 30.7, 46.0, 39.3, …
## $ somecollege <dbl> 20.9, 29.2, 21.4, 23.5, 25.7, 17.2, 21.6, …
## $ associate <dbl> 7.6, 10.1, 7.9, 7.3, 8.0, 4.1, 5.2, 6.6, 4…
## $ bachelor <dbl> 12.7, 10.0, 13.7, 5.9, 17.6, 7.1, 2.2, 7.8…
## $ grad <dbl> 5.1, 5.4, 9.8, 2.0, 8.7, 2.9, 0.4, 4.2, 3.…
## $ pov <dbl> 19.0, 8.8, 15.6, 25.5, 7.3, 8.1, 13.3, 23.…
## $ hs_orless <dbl> 53.7, 45.4, 47.2, 61.4, 40.0, 68.7, 70.6, …
## $ urc2006 <dbl> 4, 4, 4, 1, 1, 1, 2, 3, 3, 3, 2, 5, 4, 1, …
## $ aod <dbl> 36.000000, 43.416667, 33.000000, 39.583333…
## $ value <dbl> 11.212174, 12.375394, 10.508850, 15.591017…
## $ state_California <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ city_Not.in.a.city <dbl> NA, NA, NA, 0, 1, 1, 1, NA, NA, NA, 0, NA,…Notice that our city_Not.in.a.city variable seems to be NA values.
Why might that be?
Ah! Perhaps it is because some of our levels were not previously seen in the training set!
Let’s take a look using the set operations of the dplyr package.
We can take a look at cities that were different between the test and training set.
traincities <- train_pm %>% distinct(city)
testcities <- test_pm %>% distinct(city)
#get the number of cities that were different
dim(dplyr::setdiff(traincities, testcities))## [1] 381 1## [1] 55 1Indeed, there are lots of different cities in our test data that are not in our training data!
So, let’s go back to our pm dataset and modify the city variable to just be values of in a city or not in a city using the case_when() function of dplyr.
This function allows you to vectorize multiple if_else() statements.
pm %>%
mutate(city = case_when(city == "Not in a city" ~ "Not in a city",
city != "Not in a city" ~ "In a city"))## # A tibble: 876 × 50
## id value fips lat lon state county city CMAQ zcta zcta_area
## <fct> <dbl> <fct> <dbl> <dbl> <chr> <chr> <chr> <dbl> <fct> <dbl>
## 1 1003.001 9.60 1003 30.5 -87.9 Alabama Baldwin In a… 8.10 36532 190980522
## 2 1027.0001 10.8 1027 33.3 -85.8 Alabama Clay In a… 9.77 36251 374132430
## 3 1033.1002 11.2 1033 34.8 -87.7 Alabama Colbert In a… 9.40 35660 16716984
## 4 1049.1003 11.7 1049 34.3 -86.0 Alabama DeKalb In a… 8.53 35962 203836235
## 5 1055.001 12.4 1055 34.0 -86.0 Alabama Etowah In a… 9.24 35901 154069359
## 6 1069.0003 10.5 1069 31.2 -85.4 Alabama Houston In a… 9.12 36303 162685124
## 7 1073.0023 15.6 1073 33.6 -86.8 Alabama Jeffer… In a… 10.2 35207 26929603
## 8 1073.1005 12.4 1073 33.3 -87.0 Alabama Jeffer… Not … 10.2 35111 166239542
## 9 1073.1009 11.1 1073 33.5 -87.3 Alabama Jeffer… Not … 8.16 35444 385566685
## 10 1073.101 13.1 1073 33.5 -86.5 Alabama Jeffer… In a… 9.30 35094 148994881
## # ℹ 866 more rows
## # ℹ 39 more variables: zcta_pop <dbl>, imp_a500 <dbl>, imp_a1000 <dbl>,
## # imp_a5000 <dbl>, imp_a10000 <dbl>, imp_a15000 <dbl>, county_area <dbl>,
## # county_pop <dbl>, log_dist_to_prisec <dbl>, log_pri_length_5000 <dbl>,
## # log_pri_length_10000 <dbl>, log_pri_length_15000 <dbl>,
## # log_pri_length_25000 <dbl>, log_prisec_length_500 <dbl>,
## # log_prisec_length_1000 <dbl>, log_prisec_length_5000 <dbl>, …Alternatively you could create a custom step function to do this and add this to your recipe, but that is beyond the scope of this case study.
We will need to repeat all the steps (splitting the data, preprocessing, etc) as the levels of our variables have now changed.
While we are doing this, we might also have this issue for county.
The county variables appears to get dropped due to either correlation or near zero variance.
It is likely due to near zero variance because this is the more granular of these geographic categorical variables and likely sparse.
pm %<>%
mutate(city = case_when(city == "Not in a city" ~ "Not in a city",
city != "Not in a city" ~ "In a city"))
set.seed(1234) # same seed as before
pm_split <-rsample::initial_split(data = pm, prop = 2/3)
pm_split## <Training/Testing/Total>
## <584/292/876>Now we will create a new recipe:
novel_rec <-train_pm %>%
recipe() %>%
update_role(everything(), new_role = "predictor") %>%
update_role(value, new_role = "outcome") %>%
update_role(id, new_role = "id variable") %>%
update_role("fips", new_role = "county id") %>%
step_dummy(state, county, city, zcta, one_hot = TRUE) %>%
step_corr(all_numeric()) %>%
step_nzv(all_numeric()) Now we will check the preprocessed data again to see if we still have NA values.
## oper 1 step dummy [training]
## oper 2 step corr [training]## Warning in stats::cor(x, use = use, method = method): the standard deviation is
## zero## Warning: The correlation matrix has missing values. 273 columns were excluded from the
## filter.## oper 3 step nzv [training]
## The retained training set is ~ 0.27 Mb in memory.## Rows: 584
## Columns: 38
## $ id <fct> 18003.0004, 55041.0007, 6065.1003, 39009.0…
## $ value <dbl> 11.699065, 6.956780, 13.289744, 10.742000,…
## $ fips <fct> 18003, 55041, 6065, 39009, 39061, 24510, 6…
## $ lat <dbl> 41.09497, 45.56300, 33.94603, 39.44217, 39…
## $ lon <dbl> -85.10182, -88.80880, -117.40063, -81.9088…
## $ CMAQ <dbl> 10.383231, 3.411247, 11.404085, 7.971165, …
## $ zcta_area <dbl> 16696709, 370280916, 41957182, 132383592, …
## $ zcta_pop <dbl> 21306, 4141, 44001, 1115, 6566, 934, 41192…
## $ imp_a500 <dbl> 28.9783737, 0.0000000, 30.3901384, 0.00000…
## $ imp_a15000 <dbl> 13.0547959, 0.3676404, 23.7457506, 0.33079…
## $ county_area <dbl> 1702419942, 2626421270, 18664696661, 13043…
## $ county_pop <dbl> 355329, 9304, 2189641, 64757, 802374, 6209…
## $ log_dist_to_prisec <dbl> 6.621891, 8.415468, 7.419762, 6.344681, 5.…
## $ log_pri_length_5000 <dbl> 8.517193, 8.517193, 10.150514, 8.517193, 9…
## $ log_pri_length_25000 <dbl> 12.77378, 10.16440, 13.14450, 10.12663, 13…
## $ log_prisec_length_500 <dbl> 6.214608, 6.214608, 6.214608, 6.214608, 7.…
## $ log_prisec_length_1000 <dbl> 9.240294, 7.600902, 7.600902, 8.793450, 8.…
## $ log_prisec_length_5000 <dbl> 11.485093, 9.425537, 10.155961, 10.562382,…
## $ log_prisec_length_10000 <dbl> 12.75582, 11.44833, 11.59563, 11.69093, 12…
## $ log_prisec_length_25000 <dbl> 13.98749, 13.15082, 13.44293, 13.58697, 14…
## $ log_nei_2008_pm10_sum_10000 <dbl> 4.91110140, 3.86982666, 4.03184660, 0.0000…
## $ log_nei_2008_pm10_sum_15000 <dbl> 5.399131, 3.883689, 5.459257, 0.000000, 6.…
## $ log_nei_2008_pm10_sum_25000 <dbl> 5.816047, 3.887264, 6.884537, 3.765635, 6.…
## $ popdens_county <dbl> 208.719947, 3.542463, 117.314577, 49.64834…
## $ popdens_zcta <dbl> 1276.059851, 11.183401, 1048.711994, 8.422…
## $ nohs <dbl> 4.3, 5.1, 3.7, 4.8, 2.1, 0.0, 2.5, 7.7, 0.…
## $ somehs <dbl> 6.7, 10.4, 5.9, 11.5, 10.5, 0.0, 4.3, 7.5,…
## $ hs <dbl> 31.7, 40.3, 17.9, 47.3, 30.0, 0.0, 17.8, 2…
## $ somecollege <dbl> 27.2, 24.1, 26.3, 20.0, 27.1, 0.0, 26.1, 2…
## $ associate <dbl> 8.2, 7.4, 8.3, 3.1, 8.5, 71.4, 13.2, 7.6, …
## $ bachelor <dbl> 15.0, 8.6, 20.2, 9.8, 14.2, 0.0, 23.4, 17.…
## $ grad <dbl> 6.8, 4.2, 17.7, 3.5, 7.6, 28.6, 12.6, 12.3…
## $ pov <dbl> 13.500, 18.900, 6.700, 14.400, 12.500, 3.5…
## $ hs_orless <dbl> 42.7, 55.8, 27.5, 63.6, 42.6, 0.0, 24.6, 3…
## $ urc2006 <dbl> 3, 6, 1, 5, 1, 1, 2, 1, 2, 6, 4, 4, 4, 4, …
## $ aod <dbl> 54.11111, 31.16667, 83.12500, 33.36364, 50…
## $ state_California <dbl> 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, …
## $ city_Not.in.a.city <dbl> 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, …## Warning: ! There are new levels in `county`: "Colbert", "Etowah", "Russell", "Walker",
## "Cochise", "Coconino", "Mohave", "Arkansas", "Crittenden", "Garland",
## "Phillips", "Pope", "Calaveras", "Humboldt", "Inyo", "Merced", "Monterey",
## "San Benito", …, "Laramie", and "Sublette".
## ℹ Consider using step_novel() (`?recipes::step_novel()`) before `step_dummy()`
## to handle unseen values.## Rows: 292
## Columns: 38
## $ id <fct> 1033.1002, 1055.001, 1069.0003, 1073.0023,…
## $ value <dbl> 11.212174, 12.375394, 10.508850, 15.591017…
## $ fips <fct> 1033, 1055, 1069, 1073, 1073, 1073, 1073, …
## $ lat <dbl> 34.75878, 33.99375, 31.22636, 33.55306, 33…
## $ lon <dbl> -87.65056, -85.99107, -85.39077, -86.81500…
## $ CMAQ <dbl> 9.402679, 9.241744, 9.121892, 10.235612, 1…
## $ zcta_area <dbl> 16716984, 154069359, 162685124, 26929603, …
## $ zcta_pop <dbl> 9042, 20045, 30217, 9010, 16140, 3699, 137…
## $ imp_a500 <dbl> 19.17301038, 16.49307958, 19.13927336, 41.…
## $ imp_a15000 <dbl> 5.2472094, 5.1612102, 4.7401296, 17.452484…
## $ county_area <dbl> 1534877333, 1385618994, 1501737720, 287819…
## $ county_pop <dbl> 54428, 104430, 101547, 658466, 658466, 194…
## $ log_dist_to_prisec <dbl> 5.760131, 5.261457, 7.112373, 6.600958, 6.…
## $ log_pri_length_5000 <dbl> 8.517193, 9.066563, 8.517193, 11.156977, 1…
## $ log_pri_length_25000 <dbl> 10.15769, 12.01356, 10.12663, 12.98762, 12…
## $ log_prisec_length_500 <dbl> 8.611945, 8.740680, 6.214608, 6.214608, 6.…
## $ log_prisec_length_1000 <dbl> 9.735569, 9.627898, 7.600902, 9.075921, 8.…
## $ log_prisec_length_5000 <dbl> 11.770407, 11.728889, 12.298627, 12.281645…
## $ log_prisec_length_10000 <dbl> 12.840663, 12.768279, 12.994141, 13.278416…
## $ log_prisec_length_25000 <dbl> 13.79973, 13.70026, 13.85550, 14.45221, 13…
## $ log_nei_2008_pm10_sum_10000 <dbl> 6.69187313, 4.43719884, 0.92888890, 8.2097…
## $ log_nei_2008_pm10_sum_15000 <dbl> 6.70127741, 4.46267932, 3.67473904, 8.6488…
## $ log_nei_2008_pm10_sum_25000 <dbl> 7.148858, 4.678311, 3.744629, 8.858019, 8.…
## $ popdens_county <dbl> 35.460814, 75.367038, 67.619664, 228.77763…
## $ popdens_zcta <dbl> 540.8870404, 130.1037411, 185.7391706, 334…
## $ nohs <dbl> 7.3, 4.3, 5.8, 7.1, 2.7, 11.1, 9.7, 3.0, 8…
## $ somehs <dbl> 15.8, 13.3, 11.6, 17.1, 6.6, 11.6, 21.6, 1…
## $ hs <dbl> 30.6, 27.8, 29.8, 37.2, 30.7, 46.0, 39.3, …
## $ somecollege <dbl> 20.9, 29.2, 21.4, 23.5, 25.7, 17.2, 21.6, …
## $ associate <dbl> 7.6, 10.1, 7.9, 7.3, 8.0, 4.1, 5.2, 6.6, 4…
## $ bachelor <dbl> 12.7, 10.0, 13.7, 5.9, 17.6, 7.1, 2.2, 7.8…
## $ grad <dbl> 5.1, 5.4, 9.8, 2.0, 8.7, 2.9, 0.4, 4.2, 3.…
## $ pov <dbl> 19.0, 8.8, 15.6, 25.5, 7.3, 8.1, 13.3, 23.…
## $ hs_orless <dbl> 53.7, 45.4, 47.2, 61.4, 40.0, 68.7, 70.6, …
## $ urc2006 <dbl> 4, 4, 4, 1, 1, 1, 2, 3, 3, 3, 2, 5, 4, 1, …
## $ aod <dbl> 36.000000, 43.416667, 33.000000, 39.583333…
## $ state_California <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ city_Not.in.a.city <dbl> 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, …Great, now we no longer have NA values!
5.14.1.8 Specifying the Model
The first step is to define what type of model we would like to use. For our case, we are going to start our analysis with a linear regression but we will demonstrate how we can try different models.
See here for modeling options in parsnip.
## Linear Regression Model Specification (regression)
##
## Computational engine: lmOK. So far, all we have defined is that we want to use a linear regression…
Let’s tell parsnip more about what we want.
We would like to use the ordinary least squares method to fit our linear regression.
So we will tell parsnip that we want to use the lm package to implement our linear regression (there are many options actually such as rstan glmnet, keras, and sparklyr). See here for a description of the differences and using these different engines with parsnip.
We will do so by using the set_engine() function of the parsnip package.
## Linear Regression Model Specification (regression)
##
## Computational engine: lmHere, we aim to predict the air pollution.
You can do this with the set_mode() function of the parsnip package, by using either set_mode("classification") or set_mode("regression").
## Linear Regression Model Specification (regression)
##
## Computational engine: lmNow we will use the workflows package to keep track of both our preprocessing steps and our model specification. It also allows us to implement fancier optimizations in an automated way.
If you recall novel_rec is the recipe we previously created with the recipes package and lm_PM_model was created when we specified our model with the parsnip package.
Here, we combine everything together into a workflow.
PM_wflow <-workflows::workflow() %>%
workflows::add_recipe(novel_rec) %>%
workflows::add_model(lm_PM_model)
PM_wflow## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: linear_reg()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 3 Recipe Steps
##
## • step_dummy()
## • step_corr()
## • step_nzv()
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Linear Regression Model Specification (regression)
##
## Computational engine: lmAh, nice. Notice how it tells us about both our preprocessing steps and our model specifications.
Next, we “prepare the recipe” (or estimate the parameters) and fit the model to our training data all at once. Printing the output, we can see the coefficients of the model.
## Warning in stats::cor(x, use = use, method = method): the standard deviation is
## zero## Warning: The correlation matrix has missing values. 273 columns were excluded from the
## filter.## ══ Workflow [trained] ══════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: linear_reg()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 3 Recipe Steps
##
## • step_dummy()
## • step_corr()
## • step_nzv()
##
## ── Model ───────────────────────────────────────────────────────────────────────
##
## Call:
## stats::lm(formula = ..y ~ ., data = data)
##
## Coefficients:
## (Intercept) lat
## 2.936e+02 3.261e-02
## lon CMAQ
## 1.586e-02 2.463e-01
## zcta_area zcta_pop
## -3.433e-10 1.013e-05
## imp_a500 imp_a15000
## 5.064e-03 -3.066e-03
## county_area county_pop
## -2.324e-11 -7.576e-08
## log_dist_to_prisec log_pri_length_5000
## 6.214e-02 -2.006e-01
## log_pri_length_25000 log_prisec_length_500
## -5.411e-02 2.204e-01
## log_prisec_length_1000 log_prisec_length_5000
## 1.154e-01 2.374e-01
## log_prisec_length_10000 log_prisec_length_25000
## -3.436e-02 5.224e-01
## log_nei_2008_pm10_sum_10000 log_nei_2008_pm10_sum_15000
## 1.829e-01 -2.355e-02
## log_nei_2008_pm10_sum_25000 popdens_county
## 2.403e-02 2.203e-05
## popdens_zcta nohs
## -2.132e-06 -2.983e+00
## somehs hs
## -2.956e+00 -2.962e+00
## somecollege associate
## -2.967e+00 -2.999e+00
## bachelor grad
## -2.979e+00 -2.978e+00
## pov hs_orless
## 1.859e-03 NA
## urc2006 aod
## 2.577e-01 1.535e-02
## state_California city_Not.in.a.city
## 3.114e+00 -4.250e-025.14.1.9 Assessing the Model Fit
After we fit our model, we can use the broom package to look at the output from the fitted model in an easy/tidy way.
The tidy() function returns a tidy dataframe with coefficients from the model (one row per coefficient).
Many other broom functions currently only work with parsnip objects, not raw workflows objects.
However, we can use the tidy function if we first use the pull_workflow_fit() function.
## # A tibble: 36 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 2.94e+ 2 1.18e+ 2 2.49 0.0130
## 2 lat 3.26e- 2 2.28e- 2 1.43 0.153
## 3 lon 1.59e- 2 1.01e- 2 1.58 0.115
## 4 CMAQ 2.46e- 1 3.97e- 2 6.20 0.00000000108
## 5 zcta_area -3.43e-10 1.60e-10 -2.15 0.0320
## 6 zcta_pop 1.01e- 5 5.33e- 6 1.90 0.0578
## 7 imp_a500 5.06e- 3 7.42e- 3 0.683 0.495
## 8 imp_a15000 -3.07e- 3 1.16e- 2 -0.263 0.792
## 9 county_area -2.32e-11 1.97e-11 -1.18 0.238
## 10 county_pop -7.58e- 8 9.29e- 8 -0.815 0.415
## # ℹ 26 more rowsWe have fit our model on our training data, which means we have created a model to predict values of air pollution based on the predictors that we have included. Yay!
One last thing before we leave this section.
We often are interested in getting a sense of which variables are the most important in our model.
We can explore the variable importance using the vip() function of the vip package.
This function creates a bar plot of variable importance scores for each predictor variable (or feature) in a model.
The bar plot is ordered by importance (highest to smallest).
Notice again that we need to use the pull_workflow_fit() function.
Let’s take a look at the top 10 contributing variables:
##
## Attaching package: 'vip'## The following object is masked from 'package:utils':
##
## vi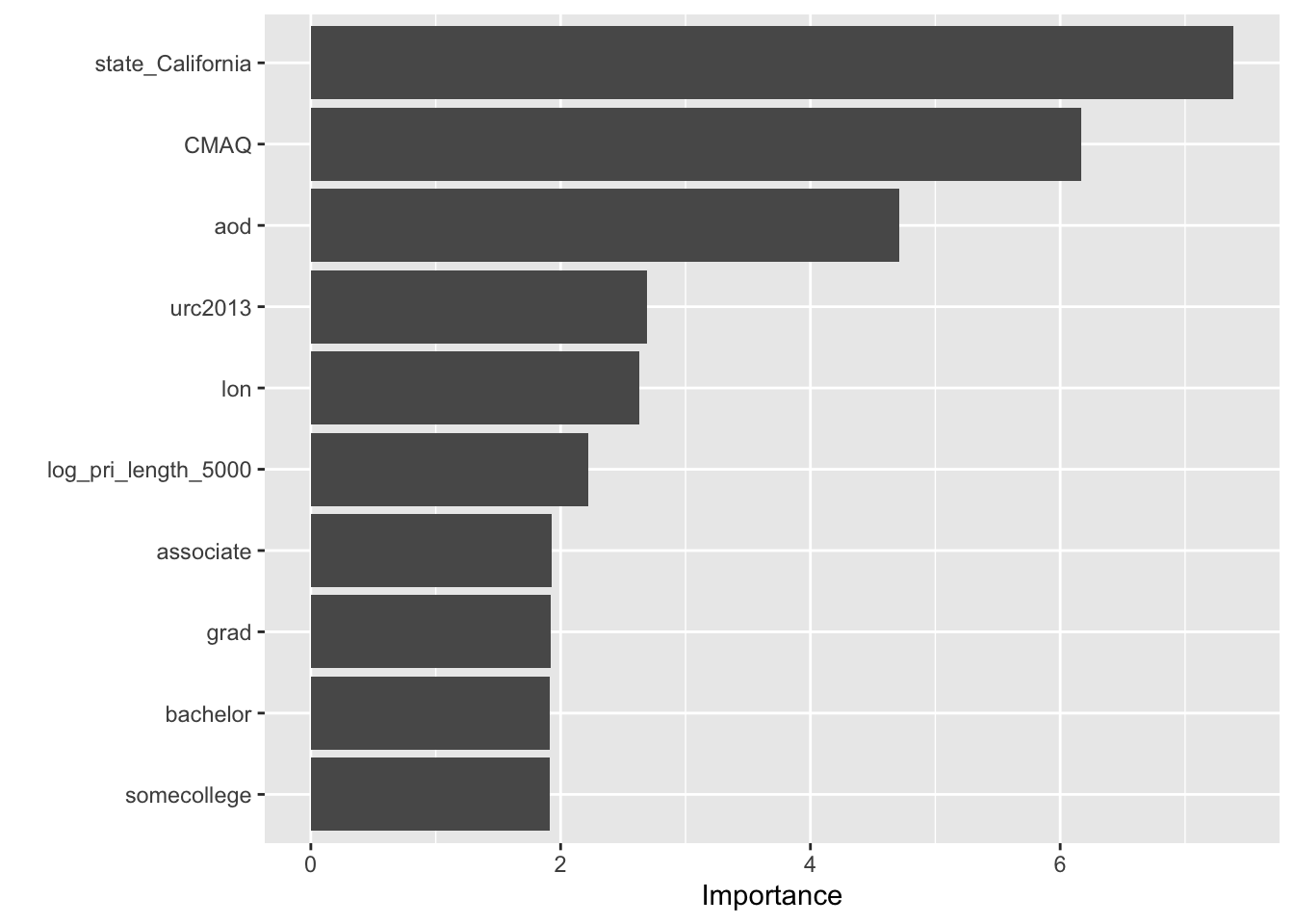
The state in which the monitor was located (in this case if it was in California or not),the CMAQ model, and the aod satellite information appear to be the most important for predicting the air pollution at a given monitor.
5.14.1.10 Model Performance
In this next section, our goal is to assess the overall model performance. The way we do this is to compare the similarity between the predicted estimates of the outcome variable produced by the model and the true outcome variable values.
Machine learning (ML) is an optimization problem that tries to minimize the distance between our predicted outcome \(\hat{Y} = f(X)\) and actual outcome \(Y\) using our features (or predictor variables) \(X\) as input to a function \(f\) that we want to estimate.
As our goal in this section is to assess overall model performance, we will now talk about different distance metrics that you can use.
First, let’s pull out our predicted outcome values \(\hat{Y} = f(X)\) from the models we fit (using different approaches).
wf_fit <- PM_wflow_fit %>%
pull_workflow_fit()
wf_fitted_values <- wf_fit$fit$fitted.values
head(wf_fitted_values)## 1 2 3 4 5 6
## 12.186782 9.139406 12.646119 10.377628 11.909934 9.520860Alternatively, we can get the fitted values using the augment() function of the broom package using the output from workflows:
wf_fitted_values <-
broom::augment(wf_fit$fit, data = preproc_train) %>%
select(value, .fitted:.std.resid)
head(wf_fitted_values)## # A tibble: 6 × 6
## value .fitted .hat .sigma .cooksd .std.resid
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 11.7 12.2 0.0370 2.05 0.0000648 -0.243
## 2 6.96 9.14 0.0496 2.05 0.00179 -1.09
## 3 13.3 12.6 0.0484 2.05 0.000151 0.322
## 4 10.7 10.4 0.0502 2.05 0.0000504 0.183
## 5 14.5 11.9 0.0243 2.05 0.00113 1.26
## 6 12.2 9.52 0.476 2.04 0.0850 1.81Finally, we can also use the predict() function.
Note that because we use the actual workflow here, we can (and actually need to) use the raw data instead of the preprocessed data.
values_pred_train <-
predict(PM_wflow_fit, train_pm) %>%
bind_cols(train_pm %>% select(value, fips, county, id)) ## Warning in predict.lm(object = object$fit, newdata = new_data, type =
## "response", : prediction from rank-deficient fit; consider predict(.,
## rankdeficient="NA")## # A tibble: 584 × 5
## .pred value fips county id
## <dbl> <dbl> <fct> <chr> <fct>
## 1 12.2 11.7 18003 Allen 18003.0004
## 2 9.14 6.96 55041 Forest 55041.0007
## 3 12.6 13.3 6065 Riverside 6065.1003
## 4 10.4 10.7 39009 Athens 39009.0003
## 5 11.9 14.5 39061 Hamilton 39061.8001
## 6 9.52 12.2 24510 Baltimore (City) 24510.0006
## 7 12.6 11.2 6061 Placer 6061.0006
## 8 10.3 6.98 6065 Riverside 6065.5001
## 9 8.74 6.61 44003 Kent 44003.0002
## 10 10.0 11.6 37111 McDowell 37111.0004
## # ℹ 574 more rows5.14.1.11 Visualizing Model Performance
Now, we can compare the predicted outcome values (or fitted values) \(\hat{Y}\) to the actual outcome values \(Y\) that we observed:
library(ggplot2)
wf_fitted_values %>%
ggplot(aes(x = value, y = .fitted)) +
geom_point() +
xlab("actual outcome values") +
ylab("predicted outcome values")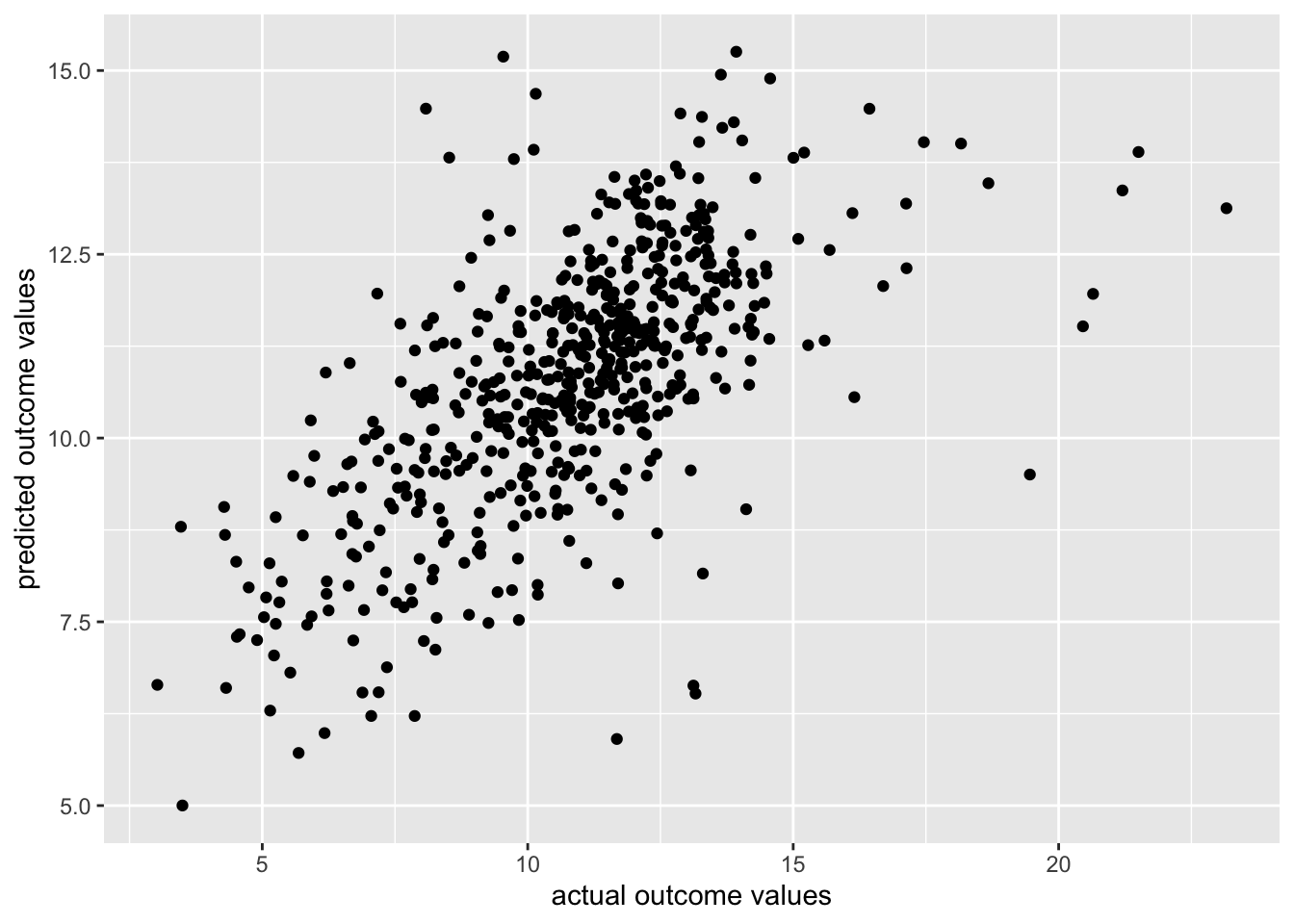
OK, so our range of the predicted outcome values appears to be smaller than the real values. We could probably do a bit better.
5.14.1.12 Quantifying Model Performance
Next, let’s use different distance functions \(d(\cdot)\) to assess how far off our predicted outcome \(\hat{Y} = f(X)\) and actual outcome \(Y\) values are from each other:
\[d(Y - \hat{Y})\]
There are entire scholarly fields of research dedicated to identifying different distance metrics \(d(\cdot)\) for machine learning applications. However, we will focus on root mean squared error (rmse)
\[RMSE = \sqrt{\frac{\sum_{i=1}^{n}{(\hat{y_t}- y_t)}^2}{n}}\]
One way to calculate these metrics within the tidymodels framework is to use the yardstick package using the metrics() function.
## # A tibble: 3 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 rmse standard 1.98
## 2 rsq standard 0.392
## 3 mae standard 1.47Alternatively if you only wanted one metric you could use the mae(), rsq(), or rmse() functions, respectively.
## # A tibble: 1 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 rmse standard 1.985.14.1.13 Assessing Model Performance on \(v\)-folds Using tune
We also intend to perform cross validation, so we will now split the training data further using the vfold_cv() function of the rsample package.
Again, because these are created at random, we need to use the base set.seed() function in order to obtain the same results each time we knit this document. We will create 10 folds.
## # 10-fold cross-validation
## # A tibble: 10 × 2
## splits id
## <list> <chr>
## 1 <split [525/59]> Fold01
## 2 <split [525/59]> Fold02
## 3 <split [525/59]> Fold03
## 4 <split [525/59]> Fold04
## 5 <split [526/58]> Fold05
## 6 <split [526/58]> Fold06
## 7 <split [526/58]> Fold07
## 8 <split [526/58]> Fold08
## 9 <split [526/58]> Fold09
## 10 <split [526/58]> Fold10## [[1]]
## <Analysis/Assess/Total>
## <525/59/584>
##
## [[2]]
## <Analysis/Assess/Total>
## <525/59/584>
##
## [[3]]
## <Analysis/Assess/Total>
## <525/59/584>
##
## [[4]]
## <Analysis/Assess/Total>
## <525/59/584>
##
## [[5]]
## <Analysis/Assess/Total>
## <526/58/584>
##
## [[6]]
## <Analysis/Assess/Total>
## <526/58/584>
##
## [[7]]
## <Analysis/Assess/Total>
## <526/58/584>
##
## [[8]]
## <Analysis/Assess/Total>
## <526/58/584>
##
## [[9]]
## <Analysis/Assess/Total>
## <526/58/584>
##
## [[10]]
## <Analysis/Assess/Total>
## <526/58/584>We can fit the model to our cross validation folds using the fit_resamples() function of the tune package, by specifying our workflow object and the cross validation fold object we just created.
See here for more information.
## → A | warning: the standard deviation is zero, The correlation matrix has missing values. 330 columns were excluded from the
## filter.## There were issues with some computations A: x1## → B | warning: ! There are new levels in `county`: "Forest", "Niagara", "Spencer", "Trumbull",
## "Preble", "Washtenaw", "LaPorte", "Spartanburg", "Portage", "Talladega",
## "Sussex", "Haywood", "Iberville", "Plumas", "Milwaukee", "Sumner", "Butler",
## "Sebastian", …, "Mobile", and "Glynn".
## ℹ Consider using step_novel() (`?recipes::step_novel()`) before `step_dummy()`
## to handle unseen values., prediction from rank-deficient fit; consider predict(., rankdeficient="NA")## There were issues with some computations A: x1
→ C | warning: the standard deviation is zero, The correlation matrix has missing values. 328 columns were excluded from the
## filter.
## There were issues with some computations A: x1
There were issues with some computations A: x1 B: x1 C: x1
## → D | warning: ! There are new levels in `county`: "Macon", "Arlington", "Champaign",
## "Citrus", "Klamath", "Cumberland", "Ventura", "Monongalia", "Dona Ana",
## "Ottawa", "Tuscaloosa", "Edgecombe", "Peoria", "Macomb", "Teton", "Tooele",
## "St. Lawrence", "Lincoln", and "Gibson".
## ℹ Consider using step_novel() (`?recipes::step_novel()`) before `step_dummy()`
## to handle unseen values., prediction from rank-deficient fit; consider predict(., rankdeficient="NA")
## There were issues with some computations A: x1 B: x1 C: x1
→ E | warning: the standard deviation is zero, The correlation matrix has missing values. 331 columns were excluded from the
## filter.
## There were issues with some computations A: x1 B: x1 C: x1
There were issues with some computations A: x1 B: x1 C: x1 D: x1 E: x1
## → F | warning: ! There are new levels in `county`: "Oconee", "Cobb", "Vigo", "Kane", "Dane",
## "Beaver", "Buncombe", "Scioto", "Mitchell", "Sangamon", "Dodge", "Lynchburg
## City", "Nassau", "Butte", "Vilas", "Rutland", "Josephine", "San Mateo", …,
## "Wake", and "Alamance".
## ℹ Consider using step_novel() (`?recipes::step_novel()`) before `step_dummy()`
## to handle unseen values., prediction from rank-deficient fit; consider predict(., rankdeficient="NA")
## There were issues with some computations A: x1 B: x1 C: x1 D: x1 E: x1
→ G | warning: the standard deviation is zero, The correlation matrix has missing values. 324 columns were excluded from the
## filter.
## There were issues with some computations A: x1 B: x1 C: x1 D: x1 E: x1
There were issues with some computations A: x1 B: x1 C: x1 D: x1 E: x…
## → H | warning: ! There are new levels in `county`: "Allen", "McDowell", "Chaves", "Lawrence",
## "Weber", "Cedar", "Gaston", "Warren", "Bernalillo", "Hancock", "Chittenden",
## "Mahoning", "Ocean", "Clay", "Hidalgo", "Lexington", "Davidson", "Virginia
## Beach City", "Shelby", and "Chester".
## ℹ Consider using step_novel() (`?recipes::step_novel()`) before `step_dummy()`
## to handle unseen values., prediction from rank-deficient fit; consider predict(., rankdeficient="NA")
## There were issues with some computations A: x1 B: x1 C: x1 D: x1 E: x…
There were issues with some computations A: x1 B: x1 C: x2 D: x1 E: x…
## → I | warning: ! There are new levels in `state`: "Nevada".
## ℹ Consider using step_novel() (`?recipes::step_novel()`) before `step_dummy()`
## to handle unseen values., ! There are new levels in `county`: "Bay", "Clermont", "Yellowstone", "Anne
## Arundel", "Houston", "Genesee", "Yavapai", "Middlesex", "Lenawee", "Rowan",
## "Converse", "St. Croix", "Ashley", "Clayton", "Jones", "Seminole", "Lenoir",
## "Henderson", …, "West Baton Rouge", and "Muscatine".
## ℹ Consider using step_novel() (`?recipes::step_novel()`) before `step_dummy()`
## to handle unseen values., prediction from rank-deficient fit; consider predict(., rankdeficient="NA")
## There were issues with some computations A: x1 B: x1 C: x2 D: x1 E: x…
→ J | warning: the standard deviation is zero, The correlation matrix has missing values. 326 columns were excluded from the
## filter.
## There were issues with some computations A: x1 B: x1 C: x2 D: x1 E: x…
There were issues with some computations A: x1 B: x1 C: x2 D: x1 E: x…
## → K | warning: ! There are new levels in `county`: "Yuma", "Flathead", "Grafton", "Brewster",
## "Tarrant", "Park", "East Baton Rouge", "Mille Lacs", "Bell", "Nevada",
## "Monroe", "Shawnee", "Ellis", "Bannock", "Cheshire", "Harris", "Stearns",
## "Pittsburg", "Charles", and "Marshall".
## ℹ Consider using step_novel() (`?recipes::step_novel()`) before `step_dummy()`
## to handle unseen values., prediction from rank-deficient fit; consider predict(., rankdeficient="NA")
## There were issues with some computations A: x1 B: x1 C: x2 D: x1 E: x…
There were issues with some computations A: x1 B: x1 C: x2 D: x1 E: x…
## → L | warning: ! There are new levels in `county`: "Hampton City", "Randolph", "Hinds",
## "Codington", "Dauphin", "Bennington", "Brookings", "Raleigh", "Passaic",
## "Duplin", "Erie", "Page", "Bullitt", "Stanislaus", "Cameron", "Lucas",
## "Davis", "Santa Clara", …, "Spokane", and "La Salle".
## ℹ Consider using step_novel() (`?recipes::step_novel()`) before `step_dummy()`
## to handle unseen values., prediction from rank-deficient fit; consider predict(., rankdeficient="NA")
## There were issues with some computations A: x1 B: x1 C: x2 D: x1 E: x…
There were issues with some computations A: x1 B: x1 C: x3 D: x1 E: x…
## → M | warning: ! There are new levels in `county`: "Athens", "Cabell", "Dougherty",
## "Manistee", "Oklahoma", "Will", "Grant", "Taylor", "Allegan", "Bolivar",
## "Sullivan", "McLean", "Albemarle", "Knox", "Essex", "Manitowoc", "Pierce",
## "Jersey", …, "Belknap", and "Sauk".
## ℹ Consider using step_novel() (`?recipes::step_novel()`) before `step_dummy()`
## to handle unseen values., prediction from rank-deficient fit; consider predict(., rankdeficient="NA")
## There were issues with some computations A: x1 B: x1 C: x3 D: x1 E: x…
There were issues with some computations A: x1 B: x1 C: x3 D: x1 E: x…
## → N | warning: ! There are new levels in `state`: "Maine" and "North Dakota".
## ℹ Consider using step_novel() (`?recipes::step_novel()`) before `step_dummy()`
## to handle unseen values., ! There are new levels in `county`: "Placer", "DeKalb", "Sutter", "Camden",
## "Durham", "Henry", "Harney", "Colusa", "Queens", "Berkshire", "Kalamazoo",
## "Aroostook", "Ouachita", "Burleigh", "San Joaquin", "Sainte Genevieve",
## "Sandoval", "Palo Alto", …, "Roanoke City", and "Gwinnett".
## ℹ Consider using step_novel() (`?recipes::step_novel()`) before `step_dummy()`
## to handle unseen values., prediction from rank-deficient fit; consider predict(., rankdeficient="NA")
## There were issues with some computations A: x1 B: x1 C: x3 D: x1 E: x…
→ O | warning: the standard deviation is zero, The correlation matrix has missing values. 329 columns were excluded from the
## filter.
## There were issues with some computations A: x1 B: x1 C: x3 D: x1 E: x…
There were issues with some computations A: x1 B: x1 C: x3 D: x1 E: x…
## → P | warning: ! There are new levels in `county`: "Stark", "St. Lucie", "Ashland", "Morgan",
## "Box Elder", "Yolo", "Clarke", "Chesterfield", "Woodbury", "New London",
## "Santa Cruz", "Forrest", "Howard", "Buchanan", "Ohio", "Pueblo", "Medina",
## "McCracken", …, "Dubois", and "Robeson".
## ℹ Consider using step_novel() (`?recipes::step_novel()`) before `step_dummy()`
## to handle unseen values., prediction from rank-deficient fit; consider predict(., rankdeficient="NA")
## There were issues with some computations A: x1 B: x1 C: x3 D: x1 E: x…
There were issues with some computations A: x1 B: x1 C: x3 D: x1 E: x…We can now take a look at various performance metrics based on the fit of our cross validation “resamples”.
To do this we will use the collect_metrics() function of the tune package. This will show us the mean of the accuracy estimate of the different cross validation folds.
## # Resampling results
## # 10-fold cross-validation
## # A tibble: 10 × 4
## splits id .metrics .notes
## <list> <chr> <list> <list>
## 1 <split [525/59]> Fold01 <tibble [2 × 4]> <tibble [2 × 3]>
## 2 <split [525/59]> Fold02 <tibble [2 × 4]> <tibble [2 × 3]>
## 3 <split [525/59]> Fold03 <tibble [2 × 4]> <tibble [2 × 3]>
## 4 <split [525/59]> Fold04 <tibble [2 × 4]> <tibble [2 × 3]>
## 5 <split [526/58]> Fold05 <tibble [2 × 4]> <tibble [2 × 3]>
## 6 <split [526/58]> Fold06 <tibble [2 × 4]> <tibble [2 × 3]>
## 7 <split [526/58]> Fold07 <tibble [2 × 4]> <tibble [2 × 3]>
## 8 <split [526/58]> Fold08 <tibble [2 × 4]> <tibble [2 × 3]>
## 9 <split [526/58]> Fold09 <tibble [2 × 4]> <tibble [2 × 3]>
## 10 <split [526/58]> Fold10 <tibble [2 × 4]> <tibble [2 × 3]>
##
## There were issues with some computations:
##
## - Warning(s) x1: ! There are new levels in `county`: "Allen", "McDowell", "Chaves"...
## - Warning(s) x1: ! There are new levels in `county`: "Athens", "Cabell", "Doughert...
## - Warning(s) x1: ! There are new levels in `county`: "Forest", "Niagara", "Spencer...
## - Warning(s) x1: ! There are new levels in `county`: "Hampton City", "Randolph", "...
## - Warning(s) x1: ! There are new levels in `county`: "Macon", "Arlington", "Champa...
## - Warning(s) x1: ! There are new levels in `county`: "Oconee", "Cobb", "Vigo", "Ka...
## - Warning(s) x1: ! There are new levels in `county`: "Stark", "St. Lucie", "Ashlan...
## - Warning(s) x1: ! There are new levels in `county`: "Yuma", "Flathead", "Grafton"...
## - Warning(s) x1: ! There are new levels in `state`: "Maine" and "North Dakota". ℹ ...
## - Warning(s) x1: ! There are new levels in `state`: "Nevada". ℹ Consider using ste...
## - Warning(s) x1: the standard deviation is zero, The correlation matrix has missin...
## - Warning(s) x1: the standard deviation is zero, The correlation matrix has missin...
## - Warning(s) x3: the standard deviation is zero, The correlation matrix has missin...
## - Warning(s) x1: the standard deviation is zero, The correlation matrix has missin...
## - Warning(s) x1: the standard deviation is zero, The correlation matrix has missin...
## - Warning(s) x3: the standard deviation is zero, The correlation matrix has missin...
##
## Run `show_notes(.Last.tune.result)` for more information.## # A tibble: 2 × 6
## .metric .estimator mean n std_err .config
## <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 rmse standard 2.09 10 0.123 Preprocessor1_Model1
## 2 rsq standard 0.321 10 0.0357 Preprocessor1_Model1In the previous section, we demonstrated how to build a machine learning model (specifically a linear regression model) to predict air pollution with the tidymodels framework.
In the next few section, we will demonstrate another machine learning model.
5.14.1.14 Random Forest
Now, we are going to predict our outcome variable (air pollution) using a decision tree method called random forest.
In the case of random forest, multiple decision trees are created - hence the name forest, and each tree is built using a random subset of the training data (with replacement) - hence the full name random forest. This random aspect helps to keep the algorithm from overfitting the data.
The mean of the predictions from each of the trees is used in the final output.
In our case, we are going to use the random forest method of the the randomForest package.
This package is currently not compatible with categorical variables that have more than 53 levels. See here for the documentation about when this was updated from 25 levels. Thus we will remove the zcta and county variables.
Note that the step_novel() function is necessary here for the state variable to get all cross validation folds to work, because there will be different levels included in each fold test and training sets. Thus there are new levels for some of the test sets which would otherwise result in an error.
According to the documentation for the recipes package:
step_novel creates a specification of a recipe step that will assign a previously unseen factor level to a new value.
RF_rec <- recipe(train_pm) %>%
update_role(everything(), new_role = "predictor")%>%
update_role(value, new_role = "outcome")%>%
update_role(id, new_role = "id variable") %>%
update_role("fips", new_role = "county id") %>%
step_novel("state") %>%
step_string2factor("state", "county", "city") %>%
step_rm("county") %>%
step_rm("zcta") %>%
step_corr(all_numeric())%>%
step_nzv(all_numeric())The rand_forest() function of the parsnip package has three important arguments that act as an interface for the different possible engines to perform a random forest analysis:
mtry- The number of predictor variables (or features) that will be randomly sampled at each split when creating the tree models. The default number for regression analyses is the number of predictors divided by 3.min_n- The minimum number of data points in a node that are required for the node to be split further.trees- the number of trees in the ensemble
We will start by trying an mtry value of 10 and a min_n value of 4.
Now that we have our recipe (RF_rec), let’s specify the model with rand_forest() from parsnip.
## Random Forest Model Specification (unknown mode)
##
## Main Arguments:
## mtry = 10
## min_n = 4
##
## Computational engine: rangerNext, we set the engine and mode:
Note that you could also use the ranger or spark packages instead of randomForest.
If you were to use the ranger package to implement the random forest analysis you would need to specify an importance argument to be able to evaluate predictor importance. The options are impurity or permutation.
These other packages have different advantages and disadvantages- for example ranger and spark are not as limiting for the number of categories for categorical variables. For more information see their documentation: here for ranger, here for spark, and here for randomForest.
See here for more documentation about implementing these engine options with tidymodels. Note that there are also other R packages for implementing random forest algorithms, but these three packages (ranger, spark, and randomForest) are currently compatible with tidymodels.
## randomForest 4.7-1.2## Type rfNews() to see new features/changes/bug fixes.##
## Attaching package: 'randomForest'## The following object is masked from 'package:dplyr':
##
## combine## The following object is masked from 'package:ggplot2':
##
## margin## Random Forest Model Specification (regression)
##
## Main Arguments:
## mtry = 10
## min_n = 4
##
## Computational engine: randomForestThen, we put this all together into a workflow:
RF_wflow <- workflows::workflow() %>%
workflows::add_recipe(RF_rec) %>%
workflows::add_model(RF_PM_model)
RF_wflow## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: rand_forest()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 6 Recipe Steps
##
## • step_novel()
## • step_string2factor()
## • step_rm()
## • step_rm()
## • step_corr()
## • step_nzv()
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Random Forest Model Specification (regression)
##
## Main Arguments:
## mtry = 10
## min_n = 4
##
## Computational engine: randomForestFinally, we fit the data to the model:
## ══ Workflow [trained] ══════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: rand_forest()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 6 Recipe Steps
##
## • step_novel()
## • step_string2factor()
## • step_rm()
## • step_rm()
## • step_corr()
## • step_nzv()
##
## ── Model ───────────────────────────────────────────────────────────────────────
##
## Call:
## randomForest(x = maybe_data_frame(x), y = y, mtry = min_cols(~10, x), nodesize = min_rows(~4, x))
## Type of random forest: regression
## Number of trees: 500
## No. of variables tried at each split: 10
##
## Mean of squared residuals: 2.66909
## % Var explained: 58.74Now, we will look at variable importance:
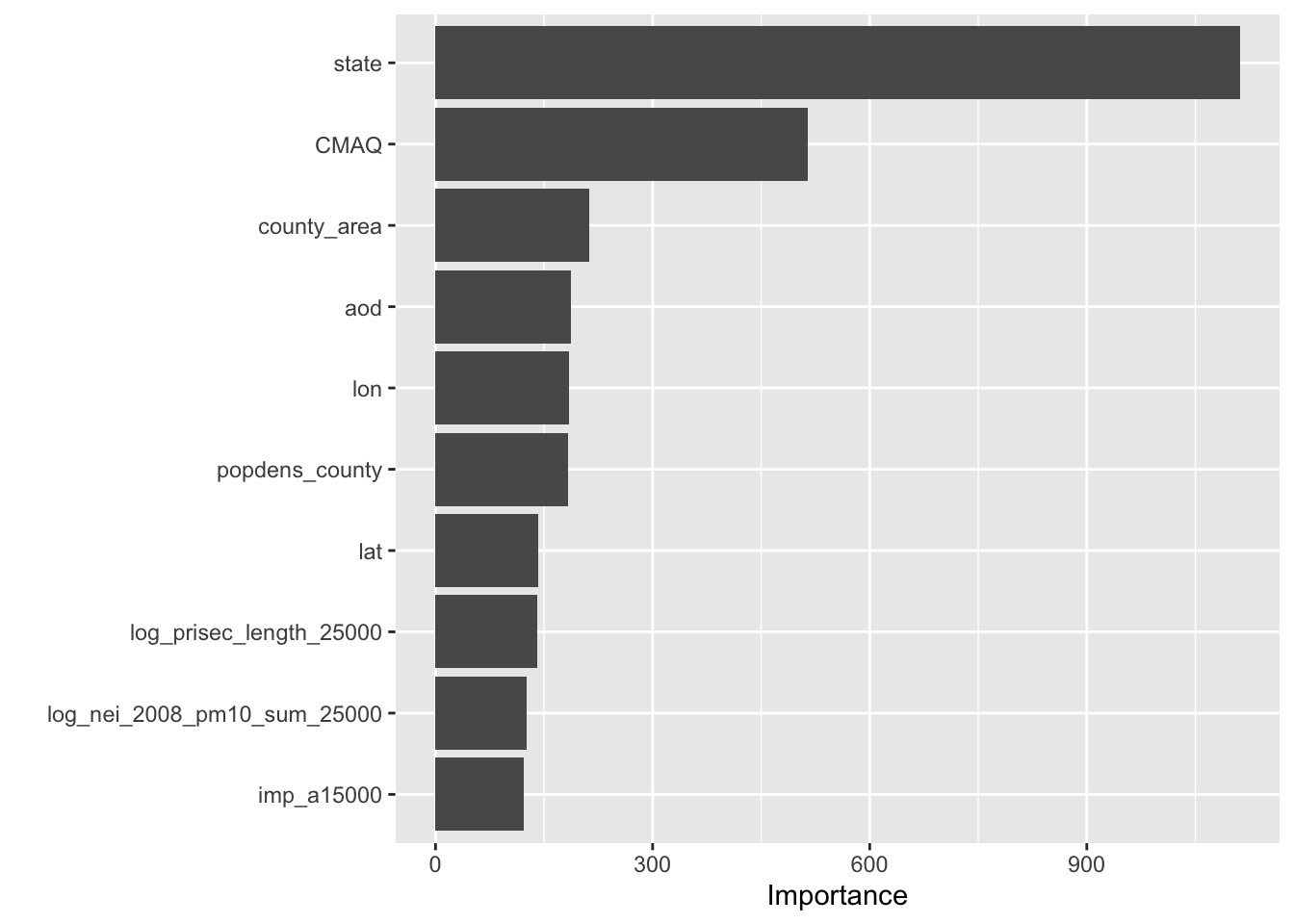
Interesting! In the previous model the CMAQ values and the state where the monitor was located were also the top two most important, however predictors about education levels of the communities where the monitor was located was among the top most important. Now we see that population density and proximity to sources of emissions and roads are among the top ten.
Now let’s take a look at model performance by fitting the data using cross validation:
set.seed(456)
resample_RF_fit <- tune::fit_resamples(RF_wflow, vfold_pm)
collect_metrics(resample_RF_fit)OK, so our first model had a mean rmse value of 2.13.
It looks like the random forest model had a much lower rmse value of 1.68.
If we tuned our random forest model based on the number of trees or the value for mtry (which is “The number of predictors that will be randomly sampled at each split when creating the tree models”), we might get a model with even better performance.
However, our cross validated mean rmse value of 1.68 is quite good because our range of true outcome values is much larger: (4.298, 23.161).
5.14.1.15 Model Tuning
Hyperparameters are often things that we need to specify about a model. For example, the number of predictor variables (or features) that will be randomly sampled at each split when creating the tree models called mtry is a hyperparameter. The default number for regression analyses is the number of predictors divided by 3. Instead of arbitrarily specifying this, we can try to determine the best option for model performance by a process called tuning.
Now let’s try some tuning.
Let’s take a closer look at the mtry and min_n hyperparameters in our Random Forest model.
We aren’t exactly sure what values of mtry and min_n achieve good accuracy yet keep our model generalizable for other data.
This is when our cross validation methods become really handy because now we can test out different values for each of these hyperparameters to assess what values seem to work best for model performance on these resamples of our training set data.
Previously we specified our model like so:
RF_PM_model <-
parsnip::rand_forest(mtry = 10, min_n = 4) %>%
set_engine("randomForest") %>%
set_mode("regression")
RF_PM_model## Random Forest Model Specification (regression)
##
## Main Arguments:
## mtry = 10
## min_n = 4
##
## Computational engine: randomForestNow instead of specifying a value for the mtry and min_n arguments, we can use the tune() function of the tune package like so: mtry = tune(). This indicates that these hyperparameters are to be tuned.
tune_RF_model <- rand_forest(mtry = tune(), min_n = tune()) %>%
set_engine("randomForest") %>%
set_mode("regression")
tune_RF_model## Random Forest Model Specification (regression)
##
## Main Arguments:
## mtry = tune()
## min_n = tune()
##
## Computational engine: randomForestAgain we will add this to a workflow, the only difference here is that we are using a different model specification with tune_RF_model instead of RF_model:
RF_tune_wflow <- workflows::workflow() %>%
workflows::add_recipe(RF_rec) %>%
workflows::add_model(tune_RF_model)
RF_tune_wflow## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: rand_forest()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 6 Recipe Steps
##
## • step_novel()
## • step_string2factor()
## • step_rm()
## • step_rm()
## • step_corr()
## • step_nzv()
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Random Forest Model Specification (regression)
##
## Main Arguments:
## mtry = tune()
## min_n = tune()
##
## Computational engine: randomForestNow we can use the tune_grid() function of the tune package to evaluate different combinations of values for mtry and min_n using our cross validation samples of our training set (vfold_pm) to see what combination of values performs best.
To use this function we will specify the workflow using the object argument and the samples to use using the resamples argument. The grid argument specifies how many possible options for each argument should be attempted.
By default 10 different values will be attempted for each hyperparameter that is being tuned.
We can use the doParallel package to allow us to fit all these models to our cross validation samples faster. So if you were performing this on a computer with multiple cores or processors, then different models with different hyperparameter values can be fit to the cross validation samples simultaneously across different cores or processors.
You can see how many cores you have access to on your system using the detectCores() function in the parallel package.
## [1] 8The registerDoParallel() function will use the number for cores specified using the cores= argument, or it will assign it automatically to one-half of the number of cores detected by the parallel package.
We need to use set.seed() here because the values chosen for mtry and min_n may vary if we preform this evaluation again because they are chosen semi-randomly (meaning that they are within a range of reasonable values but still random).
Note: this step will take some time.
doParallel::registerDoParallel(cores=2)
set.seed(123)
tune_RF_results <- tune_grid(object = RF_tune_wflow, resamples = vfold_pm, grid = 20)## i Creating pre-processing data to finalize unknown parameter: mtry## Warning: ! tune detected a parallel backend registered with foreach but no backend
## registered with future.
## ℹ Support for parallel processing with foreach was soft-deprecated in tune
## 1.2.1.
## ℹ See ?parallelism (`?tune::parallelism()`) to learn more.## # Tuning results
## # 10-fold cross-validation
## # A tibble: 10 × 4
## splits id .metrics .notes
## <list> <chr> <list> <list>
## 1 <split [525/59]> Fold01 <tibble [40 × 6]> <tibble [0 × 3]>
## 2 <split [525/59]> Fold02 <tibble [40 × 6]> <tibble [1 × 3]>
## 3 <split [525/59]> Fold03 <tibble [40 × 6]> <tibble [0 × 3]>
## 4 <split [525/59]> Fold04 <tibble [40 × 6]> <tibble [0 × 3]>
## 5 <split [526/58]> Fold05 <tibble [40 × 6]> <tibble [0 × 3]>
## 6 <split [526/58]> Fold06 <tibble [40 × 6]> <tibble [0 × 3]>
## 7 <split [526/58]> Fold07 <tibble [40 × 6]> <tibble [0 × 3]>
## 8 <split [526/58]> Fold08 <tibble [40 × 6]> <tibble [0 × 3]>
## 9 <split [526/58]> Fold09 <tibble [40 × 6]> <tibble [1 × 3]>
## 10 <split [526/58]> Fold10 <tibble [40 × 6]> <tibble [0 × 3]>
##
## There were issues with some computations:
##
## - Warning(s) x2: ! 36 columns were requested but there were 35 predictors in the d...
##
## Run `show_notes(.Last.tune.result)` for more information.See the tune getting started guide for more information about implementing this in tidymodels.
If you wanted more control over this process you could specify the different possible options for mtry and min_n in the tune_grid() function using the grid_*() functions of the dials package to create a more specific grid.
By default the values for the hyperparameters being tuned are chosen semi-randomly (meaning that they are within a range of reasonable values but still random).
Now we can use the collect_metrics() function again to take a look at what happened with our cross validation tests. We can see the different values chosen for mtry and min_n and the mean rmse and rsq values across the cross validation samples.
## # A tibble: 6 × 8
## mtry min_n .metric .estimator mean n std_err .config
## <int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 1 14 rmse standard 1.95 10 0.119 Preprocessor1_Model01
## 2 1 14 rsq standard 0.483 10 0.0323 Preprocessor1_Model01
## 3 2 24 rmse standard 1.84 10 0.124 Preprocessor1_Model02
## 4 2 24 rsq standard 0.539 10 0.0362 Preprocessor1_Model02
## 5 4 34 rmse standard 1.75 10 0.127 Preprocessor1_Model03
## 6 4 34 rsq standard 0.573 10 0.0352 Preprocessor1_Model03We can now use the show_best() function as it was truly intended, to see what values for min_n and mtry resulted in the best performance.
## # A tibble: 1 × 8
## mtry min_n .metric .estimator mean n std_err .config
## <int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 15 2 rmse standard 1.58 10 0.116 Preprocessor1_Model09There we have it… looks like an mtry of 17 and min_n of 4 had the best rmse value. You can verify this in the above output, but it is easier to just pull this row out using this function. We can see that the mean rmse value across the cross validation sets was 1.68. Before tuning it was 1.68 with a similar std_err so the performance was in this particular case wasn’t really improved, but that will not always be the case.
5.14.1.16 Final model performance evaluation
Now that we have decided that we have reasonable performance with our training data, we can stop building our model and evaluate performance with our testing data.
Here, we will use the random forest model that we built to predict values for the monitors in the testing data and we will use the values for mtry and min_n that we just determined based on our tuning analysis to achieve the best performance.
So, first we need to specify these values in a workflow. We can use the select_best() function of the tune package to grab the values that were determined to be best for mtry and min_n.
## Warning in select_best(tune_RF_results): No value of `metric` was given; "rmse"
## will be used.## # A tibble: 1 × 3
## mtry min_n .config
## <int> <int> <chr>
## 1 15 2 Preprocessor1_Model09Now we can finalize the model/workflow that we we used for tuning with these values.
With the workflows package, we can use the splitting information for our original data pm_split to fit the final model on the full training set and also on the testing data using the last_fit() function of the tune package. No preprocessing steps are required.
The results will show the performance using the testing data.
overallfit <-tune::last_fit(RF_tuned_wflow, pm_split)
# or
overallfit <-RF_wflow %>%
tune::last_fit(pm_split)The overallfit output has a lot of really useful information about the model, the data test and training split, and the predictions for the testing data.
To see the performance on the test data we can use the collect_metrics() function like we did before.
## # A tibble: 2 × 4
## .metric .estimator .estimate .config
## <chr> <chr> <dbl> <chr>
## 1 rmse standard 1.71 Preprocessor1_Model1
## 2 rsq standard 0.613 Preprocessor1_Model1Awesome! We can see that our rmse of 1.43 is quite similar with our testing data cross validation sets. We achieved quite good performance, which suggests that we would could predict other locations with more sparse monitoring based on our predictors with reasonable accuracy.
Now if you wanted to take a look at the predicted values for the test set (the 292 rows with predictions out of the 876 original monitor values) you can use the collect_predictions() function of the tune package:
## # A tibble: 6 × 5
## .pred id .row value .config
## <dbl> <chr> <int> <dbl> <chr>
## 1 12.0 train/test split 3 11.2 Preprocessor1_Model1
## 2 11.7 train/test split 5 12.4 Preprocessor1_Model1
## 3 11.0 train/test split 6 10.5 Preprocessor1_Model1
## 4 13.1 train/test split 7 15.6 Preprocessor1_Model1
## 5 12.0 train/test split 8 12.4 Preprocessor1_Model1
## 6 10.7 train/test split 9 11.1 Preprocessor1_Model1Nice!
Now, we can compare the predicted outcome values (or fitted values) \(\hat{Y}\) to the actual outcome values \(Y\) that we observed:
test_predictions %>%
ggplot(aes(x = value, y = .pred)) +
geom_point() +
xlab("actual outcome values") +
ylab("predicted outcome values") +
geom_smooth(method = "lm")## `geom_smooth()` using formula = 'y ~ x'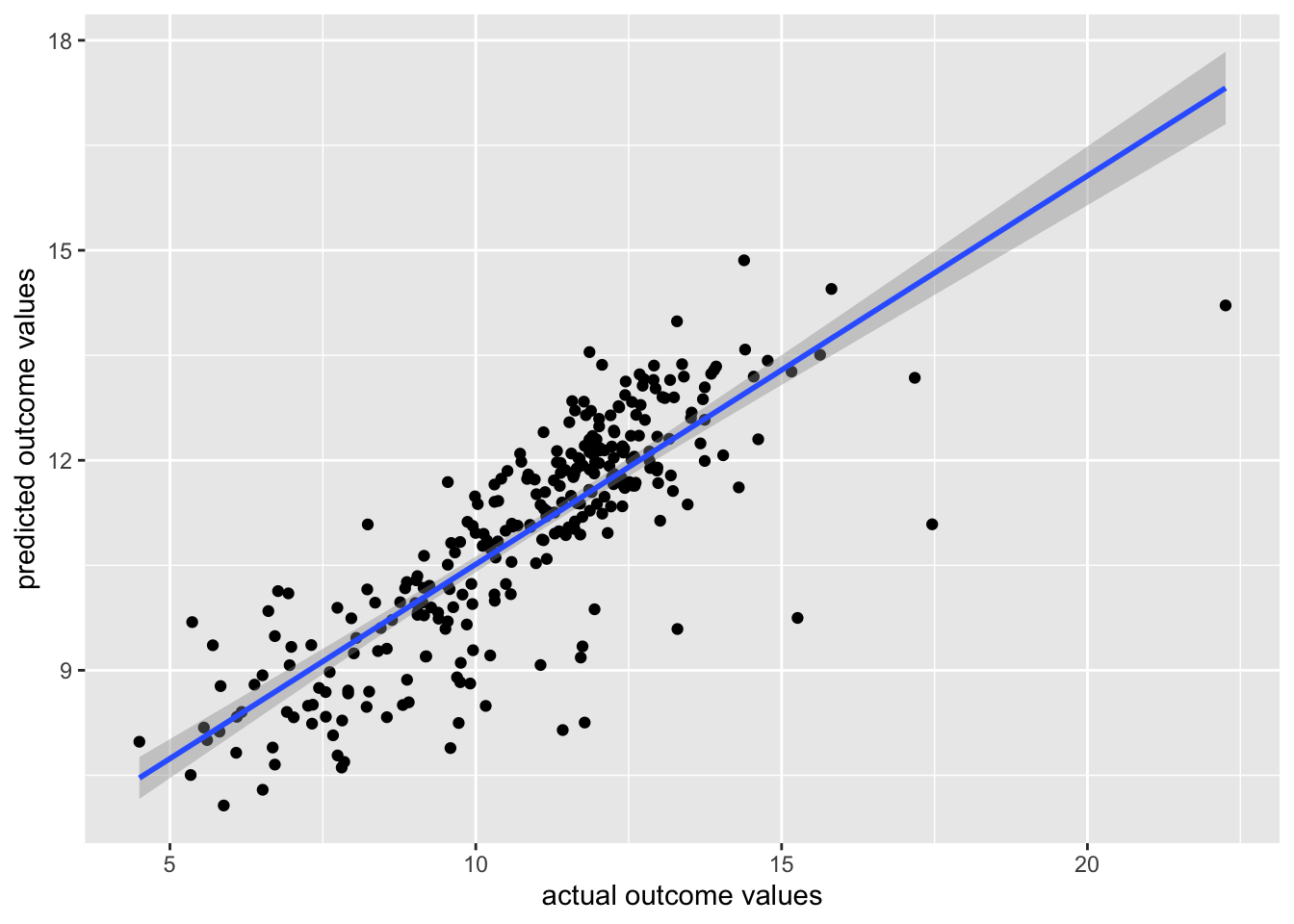
Great!
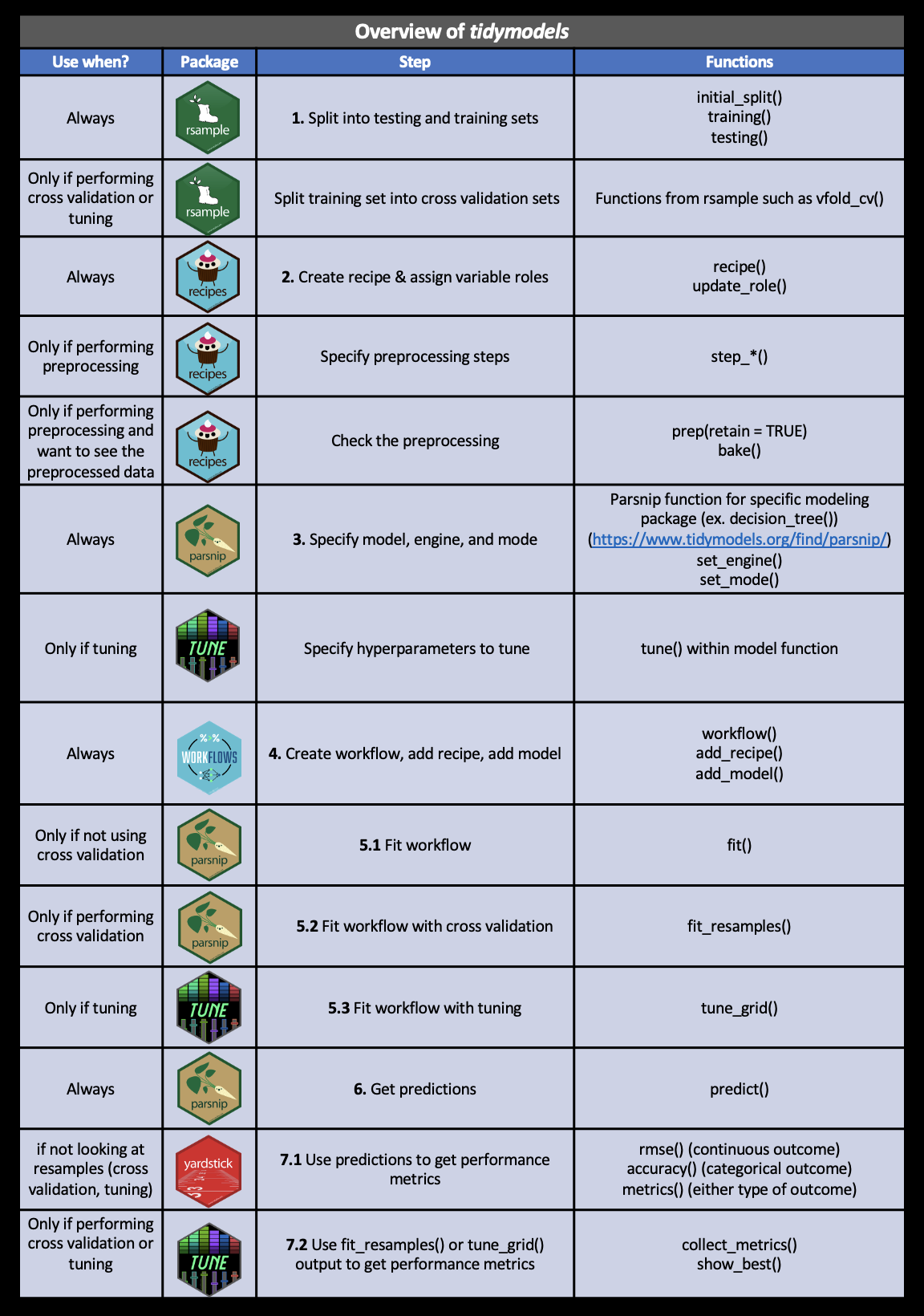
{kind=link}